
Introduction
The importance of version control Version control is a crucial component of software development that enables developers to track and manage changes to their code over time. It allows multiple developers to work on the same codebase without conflicts and provides a way to revert to previous versions of the code in case of mistakes or errors. With version control, developers can collaborate effectively, share code, and maintain a history of changes that can be traced back to specific developers and commits. Git is a popular version control system that provides a powerful set of tools for managing code changes and collaborating on projects. What is Git and why it is essential for modern development? Git is a distributed version control system that was created by Linus Torvalds in 2005. It is widely used by developers and development teams around the world as it provides a powerful and flexible way to manage changes to code over time.
Git is essential for modern development for several reasons. First, it enables developers to work collaboratively on the same codebase without conflicts, allowing multiple developers to make changes to the same code simultaneously. Second, it provides a history of changes made to the codebase, making it easy to trace back changes to specific commits, files, and developers. Third, Git allows developers to experiment with new features and ideas without affecting the stability of the main codebase. Finally, Git provides a way to revert to previous versions of the code in case of mistakes or errors, which can save developers a lot of time and effort.
Overall, Git is a powerful tool that has revolutionized the way developers collaborate and manage code, and it is essential for modern development practices. The benefits of using Git for collaboration and teamwork Git provides a number of benefits for collaboration and teamwork in software development:
-
Distributed development: Git is a distributed version control system, which means that each developer has a complete copy of the repository on their local machine. This allows developers to work independently, without requiring a central server, and to easily share changes with other team members.
-
Branching and merging: Git provides powerful branching and merging capabilities that enable developers to work on separate features or fixes without affecting the main codebase. This makes it easier to manage complex projects with multiple contributors and to experiment with new features and ideas.
-
Code review: Git provides a mechanism for code review, which allows developers to review each other’s code and provide feedback before changes are merged into the main codebase. This helps to catch errors and improve the quality of the code.
-
Traceability: Git provides a history of changes to the codebase, including who made the changes and when. This makes it easy to track down bugs or issues and to understand the evolution of the code over time.
-
Collaboration tools: Git provides integration with a wide range of collaboration tools, such as GitHub, GitLab, and Bitbucket. These tools provide features such as issue tracking, project management, and continuous integration, which help to streamline collaboration and teamwork.
Overall, Git provides a powerful set of tools for collaboration and teamwork in software development, making it easier for teams to work together, manage complex projects, and produce high-quality code. Understanding the basics of Git: None Sure, I can explain the basics of Git!
Git is a version control system that allows developers to track and manage changes to their code over time. Here are some key concepts to understand:
-
Repository: A repository is a collection of files and directories that are tracked by Git. It contains all of the code and history for a particular project.
-
Commit: A commit is a snapshot of the repository at a particular point in time. Each commit has a unique identifier, known as a SHA hash, and includes a message that describes the changes made in that commit.
-
Branch: A branch is a separate line of development that diverges from the main codebase. Branches are useful for developing new features or fixing bugs without affecting the main codebase.
-
Merge: Merging is the process of combining changes from one branch into another. When you merge a branch, Git automatically determines the changes that need to be applied and creates a new commit that includes those changes.
-
Remote: A remote is a copy of the repository that is hosted on a server, such as GitHub or GitLab. Remotes allow multiple developers to collaborate on a project and share changes with each other.
These are just a few of the basic concepts in Git, but they should give you a good understanding of how Git works. Let me know if you have any other questions! The Git workflow and the role of the Git repository The Git workflow typically involves the following steps:
-
Create a repository: The first step in using Git is to create a repository, either locally on your machine or on a remote server like GitHub or GitLab.
-
Add files: Once you have a repository, you can start adding files to it. You can add files manually using the command line, or use a graphical interface like GitKraken or Sourcetree.
-
Make changes: Once you have added files to your repository, you can start making changes to them. Git tracks all changes to files, so you can easily see what has been modified, added, or deleted.
-
Stage changes: Before you can commit changes, you need to stage them. Staging means selecting the changes that you want to include in the commit.
-
Commit changes: Once you have staged your changes, you can commit them to the repository. Each commit includes a message that describes the changes made.
-
Push changes: If you are working with a remote repository, you need to push your changes to the remote server. This makes your changes available to other developers who are working on the same project.
-
Pull changes: If other developers have made changes to the repository, you need to pull those changes to your local machine. This ensures that you are working with the most up-to-date version of the code.
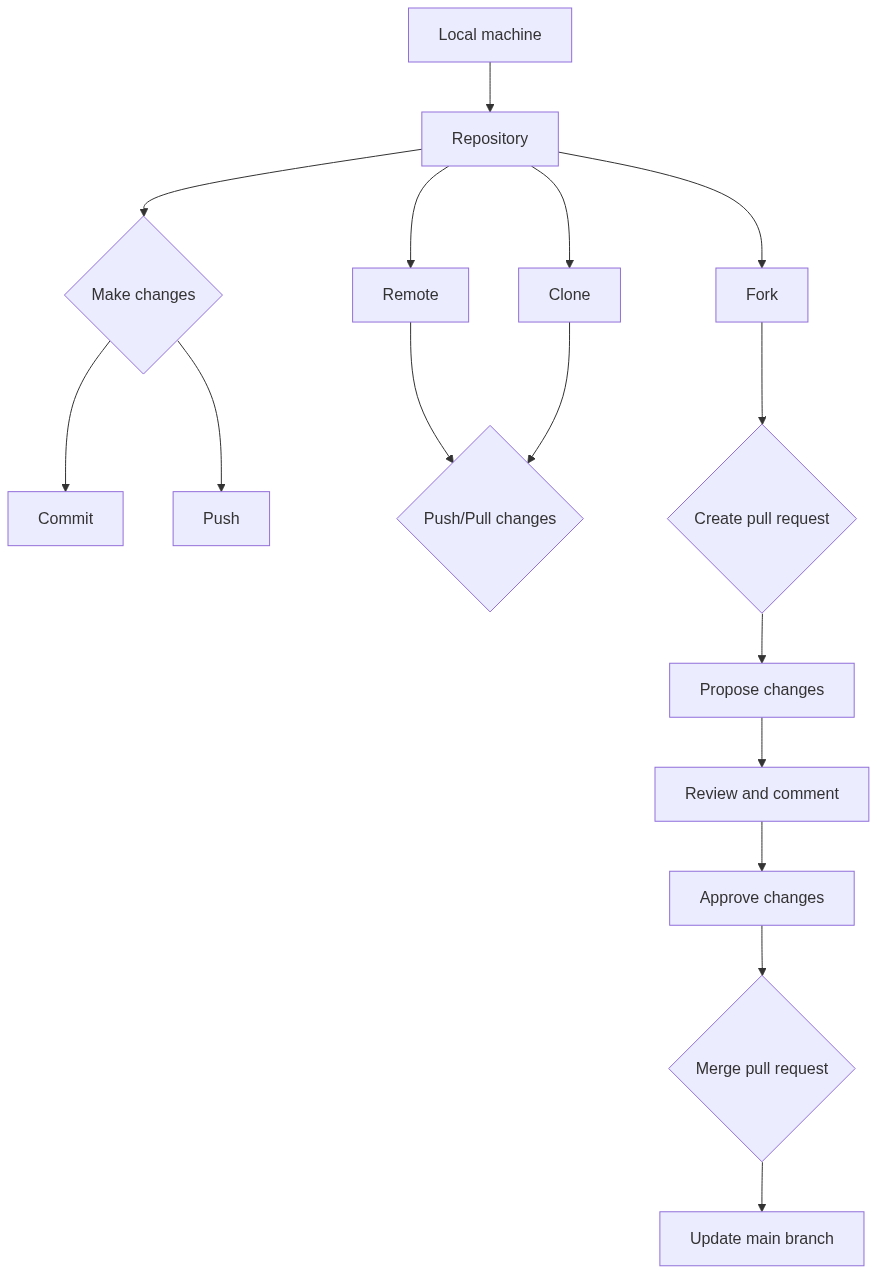
The Git repository plays a central role in this workflow, as it is where all code changes are tracked and managed. The repository is where you store all of your project files, as well as the history of changes made to those files over time. Git allows multiple developers to work on the same repository simultaneously, and provides powerful tools for managing conflicts and merging changes together.
Overall, Git provides a powerful and flexible workflow for managing code changes, collaborating with other developers, and maintaining the integrity of your codebase over time. Key Git concepts and terminology: commit, branch, merge, pull, push, and more Sure! Here are some key Git concepts and terminology:
-
Commit: A commit is a snapshot of the repository at a particular point in time. Each commit has a unique identifier, known as a SHA hash, and includes a message that describes the changes made in that commit.
-
Branch: A branch is a separate line of development that diverges from the main codebase. Branches are useful for developing new features or fixing bugs without affecting the main codebase.
-
Merge: Merging is the process of combining changes from one branch into another. When you merge a branch, Git automatically determines the changes that need to be applied and creates a new commit that includes those changes.
-
Pull: Pulling is the process of fetching changes from a remote repository and merging them into your local repository.
-
Push: Pushing is the process of sending changes from your local repository to a remote repository.
-
Remote: A remote is a copy of the repository that is hosted on a server, such as GitHub or GitLab. Remotes allow multiple developers to collaborate on a project and share changes with each other.
-
Clone: Cloning is the process of creating a local copy of a remote repository.
-
Fork: Forking is the process of creating a copy of a remote repository in your own GitHub account. Forking is useful when you want to contribute to an open-source project but do not have permission to directly modify the main repository.
-
Pull request: A pull request is a way to propose changes to a repository on GitHub. When you create a pull request, you are asking the owner of the repository to merge your changes into the main codebase.
-
Conflict: A conflict occurs when Git is unable to automatically merge changes from two different branches. When a conflict occurs, you need to manually resolve the differences between the two branches.
These are just a few of the key Git concepts and terminology. Understanding these concepts is essential for working effectively with Git and collaborating with other developers. Setting up Git on your local machine and configuring it for optimal use Sure, here are the steps to set up Git on your local machine and configure it for optimal use:
-
Install Git: The first step is to download and install Git on your local machine. You can download Git from the official website at https://git-scm.com/downloads.
-
Configure your name and email: Once Git is installed, you need to configure your name and email address. This information is used to identify you as the author of commits. To configure your name and email, open the command line and enter the following commands:
git config --global user.name "Your Name"
git config --global user.email "youremail@example.com"Replace “Your Name” and ”youremail@example.com” with your actual name and email address.
- Configure your default editor: By default, Git uses the Vim text editor for commit messages. If you prefer to use a different editor, you can configure it using the following command:
git config --global core.editor "nano"Replace “nano” with the name of your preferred editor.
- Configure line endings: Different operating systems use different line endings, which can cause issues when working with files that are shared between different systems. To configure line endings, enter the following command:
git config --global core.autocrlf inputThis configures Git to use the Unix-style line endings, which are compatible with both Unix and Windows systems.
- Configure color output: Git uses color output by default, which can make it easier to read and understand output. To enable color output, enter the following command:
git config --global color.ui trueThese are just a few of the basic Git configurations you can make on your local machine. Configuring Git to work optimally for your needs can help improve your productivity and make your workflow smoother.
Mastering Git commands If you have any specific Git commands you’d like me to explain or demonstrate, feel free to let me know! Otherwise, here are some commonly used Git commands:
-
git init: Initializes a new Git repository in the current directory. -
git clone: Creates a copy of a remote Git repository on your local machine. -
git add: Adds changes to the staging area, preparing them to be committed. -
git commit: Creates a new commit with changes that have been added to the staging area. -
git status: Shows the status of files in the working directory and staging area. -
git log: Shows a history of commits in the repository. -
git branch: Lists, creates, or deletes branches in the repository. -
git checkout: Switches between branches or restores files to a previous commit. -
git merge: Merges changes from one branch into another. -
git pull: Fetches changes from a remote repository and merges them into the current branch. -
git push: Sends changes from a local repository to a remote repository. -
git remote: Lists, adds, or removes remote repositories. -
git stash: Temporarily saves changes in a “stash” without creating a commit.
These are just a few of the many Git commands available. Mastering Git commands can help you become more efficient and effective at using Git for version control and collaboration. Basic Git commands: init, add, commit, status, and log Sure, here’s a brief overview of some basic Git commands:
-
git init: Initializes a new Git repository in the current directory. This command creates a new .git directory in the current directory, which is where Git stores all the repository data. -
git add: Adds changes to the staging area, preparing them to be committed. This command stages changes to files in the working directory, so that they can be included in the next commit. -
git commit: Creates a new commit with changes that have been added to the staging area. This command creates a new snapshot of the repository, including any changes that have been added to the staging area. -
git status: Shows the status of files in the working directory and staging area. This command shows which files have been changed, which files are staged, and which files are not being tracked by Git. -
git log: Shows a history of commits in the repository. This command displays a list of all commits in the repository, along with the author, date, and commit message for each commit.
These are some of the most basic Git commands, and they are essential for getting started with Git. As you become more comfortable with Git, you may find yourself using more advanced commands to manage your repositories and collaborate with others. Advanced Git commands: branch, merge, rebase, reset, and cherry-pick Certainly! Here’s an overview of some advanced Git commands:
-
git branch: Lists, creates, or deletes branches in the repository. This command can be used to create new branches to work on new features, or to switch between existing branches. -
git merge: Merges changes from one branch into another. This command is used to combine changes from one branch into another, and is commonly used to merge feature branches back into a main branch. -
git rebase: Moves commits from one branch to another, rewriting the history of the repository. This command can be used to keep the commit history cleaner and easier to read, but should be used with caution when working on shared branches. -
git reset: Resets the current branch to a previous commit, discarding any changes that have been made since that commit. This command can be used to undo changes that have been made, or to move the current branch to a previous state. -
git cherry-pick: Applies a specific commit from one branch to another. This command is useful when you want to apply a single commit from one branch to another, without merging the entire branch.
These commands can be powerful tools for managing your Git repositories and collaborating with others. However, they should be used with caution, as they can have significant impacts on the repository history and collaboration process. It’s important to be familiar with the potential effects of these commands before using them. Using Git with GitHub, GitLab, and other Git hosting services Using Git with Git hosting services like GitHub, GitLab, and Bitbucket can greatly enhance collaboration and make it easier to share code with others. Here are some key concepts and commands for working with Git hosting services:
-
Repository: A repository is a collection of files and version control information managed by Git. Git hosting services like GitHub and GitLab allow users to create and manage repositories online, making it easy to share code and collaborate with others.
-
Remote: A remote is a link to a Git repository hosted on a remote server, such as GitHub or GitLab. The remote allows users to push and pull changes to and from the repository.
-
Clone: Cloning a repository creates a local copy of the repository on your own computer. This can be done using the
git clonecommand, followed by the URL of the remote repository. -
Pull Request: A pull request is a way to propose changes to a repository hosted on a Git hosting service. It allows other users to review and comment on the proposed changes before they are merged into the main branch of the repository.
-
Fork: Forking a repository creates a copy of the repository under your own account on the Git hosting service. This allows you to make changes to the code without affecting the original repository, and can be useful when contributing to open source projects.
-
Merge: Merging is the process of combining changes from one branch into another. When using Git hosting services, merging typically involves creating a pull request to propose the changes, and then merging the pull request once it has been reviewed and approved.
These concepts and commands are fundamental to using Git with Git hosting services. While the exact process may differ slightly between services, the basic principles are the same, and mastering these concepts can greatly enhance your ability to collaborate and share code with others.
Collaborating with Git is one of its most powerful features. Here are some key concepts and commands to help you collaborate effectively with Git:
-
Forking: Forking is the process of making a copy of a Git repository under your own account. This allows you to make changes to the code without affecting the original repository, and can be useful when contributing to open source projects.
-
Pull Requests: Pull requests are a way to propose changes to a repository. They allow other users to review and comment on the proposed changes before they are merged into the main branch of the repository. Pull requests are typically used in conjunction with forking and branching, and can be a powerful tool for collaboration.
-
Branching: Branching is the process of creating a new branch in a Git repository. Branches are typically used to work on new features or bug fixes without affecting the main branch of the repository. Once the changes are complete, they can be merged back into the main branch using a pull request.
-
Collaborator Access: Collaborator access allows other users to make changes to a Git repository. This can be useful when working on a project with multiple contributors. Collaborator access can be granted on Git hosting services like GitHub and GitLab.
-
Resolving Merge Conflicts: Merge conflicts can occur when two or more users make changes to the same file in a Git repository. Git provides tools to help resolve these conflicts, allowing users to merge their changes together without losing any data.
These concepts and commands are fundamental to collaborating with Git. By understanding these concepts and using these commands effectively, you can work effectively with other users and make the most of Git’s powerful collaboration features. Working with remote repositories: cloning, fetching, pulling, and pushing Working with remote repositories is a key part of collaborating with Git. Here are some key concepts and commands to help you work effectively with remote repositories:
-
Cloning: Cloning a repository creates a local copy of the repository on your own computer. This can be done using the
git clonecommand, followed by the URL of the remote repository. Cloning a repository is typically the first step when working with a remote repository. -
Fetching: Fetching retrieves changes from the remote repository without merging them into your local repository. This can be done using the
git fetchcommand. Fetching is useful when you want to see the changes that have been made to the remote repository without affecting your own work. -
Pulling: Pulling retrieves changes from the remote repository and merges them into your local repository. This can be done using the
git pullcommand. Pulling is useful when you want to update your local repository with the latest changes from the remote repository. -
Pushing: Pushing sends changes from your local repository to the remote repository. This can be done using the
git pushcommand. Pushing is useful when you want to share your changes with other users who are working on the same repository. -
Remote Configuration: Remote configuration allows you to manage the connections between your local repository and the remote repository. This can be done using the
git remotecommand, which allows you to add, remove, and view remote repositories.
These concepts and commands are fundamental to working with remote repositories in Git. By understanding these concepts and using these commands effectively, you can collaborate with other users and share your work with the wider community. Resolving merge conflicts and handling Git errors Resolving merge conflicts and handling Git errors are important skills for any Git user. Here are some key concepts and commands to help you handle merge conflicts and Git errors effectively:
-
Merge Conflicts: Merge conflicts occur when Git is unable to automatically merge changes from two or more branches. This can happen when multiple users make changes to the same file, or when a user modifies a file that has been deleted or moved by another user. To resolve a merge conflict, you must manually edit the conflicting file to resolve the differences between the two branches.
-
Git Revert: The
git revertcommand allows you to undo changes made to a file or repository. This can be useful when you make a mistake or when a change causes errors in the code. Reverting a commit creates a new commit that undoes the changes made by the original commit. -
Git Reset: The
git resetcommand allows you to undo changes made to your local repository. This can be useful when you want to discard changes that have not been committed, or when you want to undo changes that have already been committed. Resetting a commit moves the HEAD pointer to an earlier commit, effectively undoing any changes made since that commit. -
Git Clean: The
git cleancommand allows you to remove untracked files from your local repository. This can be useful when you want to remove files that are no longer needed, or when you want to clean up your repository after a merge or rebase. -
Git Ignore: The
.gitignorefile allows you to specify files and directories that should be ignored by Git. This can be useful when you have files that should not be tracked by Git, such as log files or temporary files.
By understanding these concepts and using these commands effectively, you can handle merge conflicts and Git errors with confidence, and maintain a clean and organized repository. Collaborating with other developers using Git: forking, branching, and submitting pull requests Collaborating with other developers using Git involves several key concepts and workflows, including forking, branching, and submitting pull requests. Here’s a summary of each:
-
Forking: Forking is the process of creating a copy of a repository in your own account on a Git hosting service like GitHub or GitLab. Forking allows you to make changes to the repository without affecting the original repository. Once you’ve made changes to your fork, you can submit a pull request to the original repository to request that your changes be merged.
-
Branching: Branching is the process of creating a new branch in a repository to work on a specific feature or bug fix. Branching allows you to work on changes independently from the main branch, and merge changes back into the main branch when they are complete. Branching can be done using the
git branchcommand. -
Pull Requests: Pull requests are requests to merge changes from one branch into another. Pull requests are typically used when collaborating with other developers on a repository. To create a pull request, you must first fork the repository, create a new branch, make changes, and then submit a pull request to the original repository. Once the pull request is submitted, the repository owner can review the changes and either approve or reject the pull request.
These workflows are critical for collaborating effectively with other developers using Git. By understanding these workflows and using Git commands like git fork, git branch, and git pull request effectively, you can work with other developers to build high-quality software and contribute to open source projects.
Best practices for Git usage: None
Best practices for Git usage can help you avoid common mistakes and make the most of Git’s features. Here are some best practices to keep in mind when using Git:
-
Use descriptive commit messages: Write clear and concise commit messages that describe the changes you’ve made to the code. This makes it easier for other developers to understand the changes and track the history of the code.
-
Use branching effectively: Use branches to work on specific features or bug fixes, and merge changes back into the main branch when they are complete. This helps keep the main branch stable and reduces the risk of introducing bugs or conflicts.
-
Use Git for collaboration: Use Git to collaborate with other developers, whether you’re working on a small project with a few developers or contributing to a large open source project. Use tools like pull requests to review and merge changes, and communicate effectively with other developers to ensure that everyone is on the same page.
-
Use Git tags: Use Git tags to mark important milestones in the development process, such as releases or major feature updates. This makes it easier to track the history of the code and revert to earlier versions if necessary.
-
Back up your Git repository: Make sure to regularly back up your Git repository, whether by pushing changes to a remote repository or creating a local backup. This ensures that you don’t lose any code or changes in the event of a hardware failure or other issue.
By following these best practices, you can make the most of Git’s features and avoid common mistakes that can lead to conflicts or lost code. Creating effective commit messages and committing frequently Creating effective commit messages and committing frequently are essential practices for using Git effectively. Here’s why:
-
Effective commit messages: Commit messages should be clear, concise, and descriptive. They should describe the changes you’ve made to the code in enough detail that other developers can understand what you’ve done. This is important because it helps other developers track the history of the code and understand why certain changes were made. It also helps you keep track of the changes you’ve made over time, which can be useful when debugging issues or rolling back changes.
-
Committing frequently: Committing frequently is important because it allows you to track the changes you’ve made to the code over time. By committing frequently, you can create a detailed history of the code and easily revert to earlier versions if necessary. It also makes it easier to collaborate with other developers, as they can see the changes you’ve made and provide feedback or make their own changes.
Here are some tips for creating effective commit messages and committing frequently:
-
Use the imperative mood: When writing commit messages, use the imperative mood (e.g. “Add feature” instead of “Added feature”). This makes the commit message more concise and descriptive.
-
Keep it simple: Commit messages should be short and to the point. Avoid including unnecessary details or information.
-
Commit early and often: Commit changes frequently, even if they are small changes. This allows you to track the history of the code and makes it easier to identify issues or bugs.
-
Use separate commits for separate changes: If you’re making multiple changes to the code, use separate commits for each change. This makes it easier to track the history of the code and identify which changes caused issues or bugs.
By following these tips, you can create effective commit messages and commit frequently, which will help you use Git more effectively and collaborate more efficiently with other developers. Keeping your Git repository clean and organized Keeping your Git repository clean and organized is an important part of using Git effectively. Here are some tips for keeping your repository clean and organized:
-
Use branching: Use branches to work on specific features or bug fixes. This helps keep the main branch stable and reduces the risk of introducing bugs or conflicts. When you’re finished with a branch, merge it back into the main branch.
-
Delete unused branches: Delete branches that are no longer needed. This helps keep the repository clean and organized and reduces clutter.
-
Use Git ignore: Use Git ignore to ignore files or directories that don’t need to be tracked by Git. This includes files like log files or build artifacts.
-
Keep commits small: Keep your commits small and focused. This makes it easier to track changes and identify issues or bugs.
-
Use descriptive commit messages: Use descriptive commit messages that describe the changes you’ve made to the code. This makes it easier to track the history of the code and understand why certain changes were made.
-
Use Git tags: Use Git tags to mark important milestones in the development process, such as releases or major feature updates. This makes it easier to track the history of the code and revert to earlier versions if necessary.
By following these tips, you can keep your Git repository clean and organized, which will make it easier to collaborate with other developers and track changes over time. Using Git hooks and other tools to automate your workflow Using Git hooks and other tools to automate your workflow can save time and reduce errors. Here are some examples of tools and techniques that can be used to automate your workflow:
-
Git hooks: Git hooks are scripts that can be triggered by Git events, such as before or after a commit or push. These scripts can perform tasks such as running automated tests, checking for coding style violations, or automatically updating documentation.
-
Continuous Integration (CI) tools: CI tools such as Jenkins or Travis CI can be used to automate the build, testing, and deployment process. These tools can be configured to automatically run tests when new code is committed or to deploy the code to a staging or production environment.
-
Code review tools: Code review tools such as GitHub Pull Requests or GitLab Merge Requests can be used to automate the code review process. These tools can be configured to automatically run tests, check for coding style violations, and notify reviewers of new code changes.
-
Task runners: Task runners such as Grunt or Gulp can be used to automate repetitive tasks, such as minifying CSS or JavaScript files or compiling source code.
-
Version control tools: Version control tools such as Git can be used to automate the process of tracking changes to code and collaborating with other developers.
By using these tools and techniques, you can automate your workflow and reduce errors, which can help improve the quality of your code and reduce the time required to complete tasks. Git tips and tricks: None Here are some Git tips and tricks that can help you work more effectively with Git:
-
Use aliases: Aliases allow you to create shortcuts for commonly used Git commands. For example, you can create an alias for “git status” by running “git config —global alias.st status”. This allows you to run “git st” instead of “git status”.
-
Use Git reflog: Git reflog allows you to view a log of all the changes made to the Git repository, even if they are not currently visible in the Git history. This can be useful for recovering lost commits or branches.
-
Use Git bisect: Git bisect is a command that can help you identify the commit that introduced a bug. It works by allowing you to perform a binary search through the Git history to find the commit that introduced the bug.
-
Use Git stash: Git stash allows you to temporarily save changes that you are working on without committing them to the repository. This can be useful if you need to switch to another branch or work on a different feature temporarily.
-
Use Git blame: Git blame allows you to see who made changes to a specific line of code and when. This can be useful for tracking down the author of a particular change or for understanding why a certain change was made.
By using these tips and tricks, you can work more effectively with Git and save time and effort when working on your code. Git aliases and shortcuts Git aliases and shortcuts allow you to create custom commands that can save you time and effort when using Git. Here are some examples of Git aliases and shortcuts that you can use:
- Alias for “git status”:
git config --global alias.st statusThis will allow you to run “git st” instead of “git status”.
- Alias for “git add”:
git config --global alias.a addThis will allow you to run “git a” instead of “git add”.
- Alias for “git commit”:
git config --global alias.cm commitThis will allow you to run “git cm” instead of “git commit”.
- Alias for “git push”:
git config --global alias.p pushThis will allow you to run “git p” instead of “git push”.
- Shortcut for checking out a new branch and switching to it:
git config --global alias.cob 'checkout -b'This will allow you to create a new branch and switch to it in one command. For example, “git cob feature-branch” will create a new branch called “feature-branch” and switch to it.
By using Git aliases and shortcuts, you can save time and effort when using Git and make your workflow more efficient. Using Git to manage non-code files, such as documentation and configuration files Git is not limited to version control of source code files. You can use Git to manage non-code files, such as documentation, configuration files, and other files related to your project.
Here are some best practices for using Git to manage non-code files:
-
Use a separate repository: If you have a significant amount of non-code files, it’s best to keep them in a separate repository to keep the code and documentation separate. This also makes it easier to manage permissions for collaborators who don’t need access to the non-code files.
-
Use Git LFS for large files: Git LFS (Large File Storage) is an extension to Git that allows you to manage large files more efficiently. This can be useful if you have large files such as images, videos, or other media files that you want to store in Git.
-
Use a consistent directory structure: To make it easier to find and manage non-code files, use a consistent directory structure. For example, you could have a “docs” directory for all documentation files and a “config” directory for all configuration files.
-
Use descriptive filenames: Use descriptive filenames for your non-code files to make it easier to find and understand what they contain. For example, “server-config.yml” is more descriptive than “config.yml”.
-
Use a versioning convention: Use a versioning convention for your non-code files, similar to how you version your source code files. This makes it easier to keep track of changes and roll back to previous versions if necessary.
By following these best practices, you can use Git to manage non-code files effectively and keep them organized alongside your source code files. Integrating Git with other tools and services, such as editors, IDEs, and CI/CD pipelines Integrating Git with other tools and services can help streamline your development workflow and improve collaboration. Here are some examples of integrating Git with other tools and services:
-
Editors and IDEs: Many editors and IDEs have built-in support for Git, allowing you to perform Git operations directly from the editor. For example, you can commit changes, view the commit history, and switch between branches without leaving your editor. Some popular editors and IDEs that support Git include Visual Studio Code, IntelliJ IDEA, and Eclipse.
-
Continuous Integration/Continuous Deployment (CI/CD) pipelines: CI/CD pipelines automate the process of building, testing, and deploying your code. You can integrate Git with your CI/CD pipeline to automatically trigger builds and deployments when changes are pushed to your Git repository. Popular CI/CD tools that support Git include Jenkins, Travis CI, and CircleCI.
-
Issue tracking and project management tools: Many project management tools, such as Jira and Trello, have built-in integrations with Git, allowing you to link issues and tasks to specific Git branches and commits. This makes it easier to track progress and understand the impact of changes.
-
Code review tools: Code review tools, such as GitHub’s Pull Request feature, allow you to review and discuss changes with your collaborators before merging them into the main branch. This helps ensure that code changes are high-quality and meet your project’s standards.
By integrating Git with other tools and services, you can streamline your development workflow, improve collaboration, and ensure that your code changes are high-quality and well-managed. Troubleshooting common Git issues: None
Recovering lost commits and data In Git, it is generally difficult to lose commits or data permanently as Git stores every commit and its content in a secure manner. However, it is possible to accidentally lose commits or data, for example, by mistakenly deleting a branch or overwriting a commit. Here are some steps you can take to recover lost commits and data in Git:
-
Use the Git reflog: The Git reflog is a log of all the branch and HEAD changes in your repository. You can use the reflog to recover lost commits, branches, and even entire repositories. To access the reflog, run the command
git reflog. You can use the SHA-1 commit hash or branch name from the reflog to restore lost commits or branches. -
Use the Git reset command: The Git reset command can be used to undo changes and restore a previous state of your repository. For example, you can use the command
git reset HEAD~to undo the last commit and restore the repository to the previous state. -
Use the Git revert command: The Git revert command can be used to create a new commit that undoes the changes made by a previous commit. This can be useful if you want to undo changes without losing the commit history. To use the revert command, run
git revert <commit-hash>. -
Use Git data recovery tools: There are various Git data recovery tools available that can help you recover lost data in case of accidental deletion or corruption. One popular tool is the Git Data Recovery Toolkit (GDR), which can recover lost commits, objects, and trees in Git repositories.
It is important to note that while these steps can help recover lost commits and data, it is always a good practice to backup your Git repository regularly to prevent accidental loss of data. Fixing Git mistakes and undoing changes In Git, there are several ways to fix mistakes and undo changes. Here are some common scenarios and the Git commands you can use to undo or fix them:
-
Undoing changes to a file: If you made changes to a file but haven’t committed them yet, you can use the command
git checkout -- <file>to discard the changes and revert the file to the last committed version. If you have already committed the changes, you can use the commandgit revert <commit>to create a new commit that undoes the changes made by a previous commit. -
Undoing a commit: If you have committed changes that you want to undo, you can use the command
git reset HEAD~to undo the last commit and restore the repository to the previous state. This command will remove the last commit from the commit history, but the changes will still be present in the working directory. If you want to completely remove the changes, you can use the commandgit reset --hard HEAD~. -
Changing the last commit message: If you made a mistake in the last commit message, you can use the command
git commit --amend -m "new message"to change the message. This will replace the last commit with a new one that has the updated message. -
Reverting a merge commit: If you merged a branch and later realize that it caused issues, you can use the command
git revert -m 1 <merge-commit>to create a new commit that undoes the changes made by the merge commit. The-m 1option specifies that you want to revert to the first parent of the merge commit.
It is important to note that some Git commands, such as git reset --hard and git push --force, can have irreversible consequences and should be used with caution. Always make sure to back up your work before making any major changes.
Debugging Git errors and performance issues
Debugging Git errors and performance issues can be challenging, but there are some techniques and tools that can help:
-
Using the Git command line with the
--verboseor--debugoption can provide more detailed information about what Git is doing behind the scenes. For example, you can usegit clone --verbose <repository>to see a detailed log of the cloning process. -
Checking the Git documentation and online resources for common errors and solutions can also be helpful. Git has a large and active community, and there are many resources available online, including Stack Overflow, GitHub Discussions, and the Git documentation itself.
-
Using a Git GUI tool, such as GitKraken or Sourcetree, can provide a more user-friendly interface for troubleshooting and debugging Git issues. These tools often include features such as visualization of commit history and branch relationships, which can help you identify the source of errors.
-
If you are experiencing performance issues, such as slow Git commands or large repository size, you can try optimizing your Git configuration settings. For example, you can increase the Git object cache size with the command
git config --global core.packedGitLimit <size>to improve performance for large repositories. -
In some cases, it may be necessary to delete and re-clone a repository to fix persistent issues. Before doing so, make sure to back up any local changes and ensure that you have the latest version of the repository.
If you are still having issues, it may be helpful to reach out to the Git community for support or consult a Git expert for assistance. Conclusion: None As a version control system, Git has become an essential tool for modern software development. Its ability to track changes, manage versions, and facilitate collaboration has made it a cornerstone of many development workflows.
In this comprehensive guide to mastering Git, we covered a range of topics, from the basics of Git commands to advanced techniques for resolving merge conflicts, collaborating with others, and integrating Git with other tools and services. We also discussed best practices for using Git, such as committing frequently and using descriptive commit messages, and provided tips and tricks for improving your workflow.
While Git can be challenging to learn and use effectively, with practice and the help of online resources and communities, developers can become proficient in its use and unlock its full potential. Whether you are working on a solo project or collaborating with a team, mastering Git can help you work more efficiently, manage your code more effectively, and ultimately create better software. Summary of key Git concepts and commands Git is a powerful version control system that has become an essential tool for modern software development. Here is a summary of some key Git concepts and commands:
-
Repository: A repository is a central location where all your code and its history are stored.
-
Commit: A commit is a snapshot of your code at a particular point in time. It captures all the changes you have made since the last commit.
-
Branch: A branch is a separate line of development that allows you to work on a feature or bug fix without affecting the main codebase.
-
Merge: Merging is the process of combining two or more branches back into the main codebase.
-
Pull: A pull retrieves changes from a remote repository and merges them into your local repository.
-
Push: A push sends your local commits to a remote repository.
-
Clone: Cloning creates a copy of a remote repository on your local machine.
-
Fork: Forking creates a copy of a repository under your own account, allowing you to make changes without affecting the original repository.
-
Pull request: A pull request is a proposed change that you submit to the original repository owner for review and potential merging.
-
Add: Add is used to stage changes for a commit.
-
Status: Status displays the current state of your repository, including any files that have been modified or added.
-
Log: Log displays the commit history for your repository.
-
Branch: Branch is used to create, list, delete, and switch between branches.
-
Merge: Merge is used to combine changes from different branches.
-
Rebase: Rebase is used to move your changes onto a different branch.
-
Reset: Reset is used to undo changes and move the repository to a previous state.
-
Cherry-pick: Cherry-pick is used to apply a specific commit to a branch.
These are just some of the key Git concepts and commands that developers use on a daily basis. By mastering these concepts and commands, you can use Git to manage your code more effectively, collaborate with others, and improve your development workflow. Next steps for mastering Git and using it effectively for version control and collaboration Great job! You now have a good understanding of Git and its essential concepts, commands, and best practices. To continue mastering Git and using it effectively for version control and collaboration, here are some recommended next steps:
-
Practice, practice, practice: The best way to master Git is to use it regularly. Try working on some small projects, collaborate with others, and experiment with different Git commands and workflows.
-
Read Git documentation and resources: Git has extensive documentation and a large community of users and contributors. You can find tutorials, blog posts, videos, and books on Git to learn more about specific topics and advanced features.
-
Learn about Git hosting services: Git hosting services like GitHub, GitLab, and Bitbucket offer additional features for collaboration and workflow automation. Learn how to use these services effectively and integrate them into your workflow.
-
Explore Git extensions and tools: Git has many extensions and tools that can enhance your workflow and productivity, such as Git LFS, GitKraken, and Git-flow. Learn how to use these tools and find the ones that work best for your needs.
-
Join Git communities: Joining online communities like GitLab forum, GitHub community, StackOverflow, and Reddit’s r/git can help you learn from other Git users, get feedback on your code, and stay up-to-date on the latest Git news and trends.
Remember, mastering Git takes time and practice, but the benefits of version control and collaboration are well worth the effort. Good luck on your Git journey!
Chapter 1: Getting Started with Git
Installing Git on different platforms Installing Git is a straightforward process and can be done on different platforms. Here are the steps to install Git on some popular operating systems:
Installing Git on Windows:
- Download the latest Git for Windows installer from the Git website: https://git-scm.com/downloads
- Run the installer and follow the prompts to complete the installation.
- Once the installation is complete, open the Git Bash terminal by searching for “Git Bash” in the Start menu.
Installing Git on macOS:
- Open the Terminal app by searching for it in Spotlight or the Applications folder.
- Install Homebrew by running the following command in the Terminal:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"- Once Homebrew is installed, install Git by running the following command:
brew install git- Verify that Git is installed by running the command:
git --versionInstalling Git on Linux:
- Open the terminal app on your Linux distribution.
- Install Git using your package manager. For example, on Debian/Ubuntu-based systems, you can use the following command:
sudo apt-get install git- Verify that Git is installed by running the command:
git --versionThese are just general instructions, and the exact steps may vary depending on your specific operating system and version. It’s always a good idea to refer to the Git documentation or seek help from the community if you encounter any issues during installation. Installing Git on Windows, macOS, and Linux Installing Git on Windows, macOS, and Linux is a straightforward process. Here are the steps to install Git on these platforms:
Installing Git on Windows:
- Download the latest Git for Windows installer from the Git website: https://git-scm.com/downloads
- Run the installer and follow the prompts to complete the installation.
- Once the installation is complete, open the Git Bash terminal by searching for “Git Bash” in the Start menu.
Installing Git on macOS:
- Open the Terminal app by searching for it in Spotlight or the Applications folder.
- Install Homebrew by running the following command in the Terminal:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"- Once Homebrew is installed, install Git by running the following command:
brew install git- Verify that Git is installed by running the command:
git --versionInstalling Git on Linux:
- Open the terminal app on your Linux distribution.
- Install Git using your package manager. For example, on Debian/Ubuntu-based systems, you can use the following command:
sudo apt-get install git- Verify that Git is installed by running the command:
git --versionThese are just general instructions, and the exact steps may vary depending on your specific operating system and version. It’s always a good idea to refer to the Git documentation or seek help from the community if you encounter any issues during installation. Choosing between command line and GUI interfaces Choosing between command line and GUI interfaces for Git depends on personal preference and the specific task at hand.
Command line interfaces (CLI) provide greater control and flexibility, as well as the ability to automate tasks using scripts. They are typically more efficient for experienced users who are comfortable with the command line interface.
Graphical user interfaces (GUI) are generally easier to use for beginners or for visualizing complex workflows. They provide a user-friendly interface and can be helpful for reviewing changes and resolving conflicts. GUIs can also help users who are not familiar with Git commands to perform Git tasks more easily.
Some popular Git GUI clients include GitHub Desktop, GitKraken, and SourceTree. On the other hand, Git command line is available on all operating systems and provides greater flexibility for advanced users.
In summary, the choice between CLI and GUI depends on personal preference, experience level, and the specific task you are trying to accomplish. It’s worth exploring both options and using the one that works best for your needs. Configuring Git with your preferred text editor and other tools Configuring Git with your preferred text editor and other tools can help streamline your workflow and make it easier to work with Git. Here are some steps to follow to configure Git with your preferred tools:
- Configuring your text editor: By default, Git uses Vim as its default editor. If you prefer to use a different text editor, you can configure Git to use it. For example, to use Visual Studio Code as your default editor, run the following command in your terminal:
git config --global core.editor "code --wait"This command sets the global core.editor configuration variable to use Visual Studio Code with the --wait flag, which tells Git to wait for the editor to be closed before continuing with the commit.
- Configuring Git aliases: Git aliases are shortcuts for commonly used Git commands. For example, you can create an alias for
git statusso that you can typegit stinstead. To create an alias, run the following command in your terminal:
git config --global alias.st statusThis command creates a global alias for git status called st.
- Configuring Git with other tools: Git can be integrated with a variety of tools and services, such as editors, IDEs, and CI/CD pipelines. Many of these tools provide their own Git integrations and can be configured to use them. For example, you can configure Visual Studio Code to use Git by installing the Git extension and configuring it with your Git credentials.
Overall, configuring Git with your preferred tools can help improve your productivity and make it easier to work with Git.
Configuring Git
To configure Git, you can use the git config command. This command allows you to set or get configuration variables that control Git’s behavior. Git stores configuration information in three levels: system, global, and local.
- System-level configuration applies to all users on the system and is stored in the
/etc/gitconfigfile. - Global configuration applies to a single user and is stored in the
~/.gitconfigfile. - Local configuration applies to a specific repository and is stored in the
.git/configfile in that repository.
To set your name and email address, which Git uses to identify you for commit messages and other operations, use the following commands:
git config --global user.name "Your Name"
git config --global user.email "youremail@example.com"You can also configure other settings, such as default merge strategies, preferred diff tools, and aliases for frequently used commands.
To view your Git configuration settings, use the git config --list command. This will display a list of all the settings that Git is currently using.
It’s important to configure Git properly to ensure that it works as expected and to customize its behavior to your preferences.
Setting up your user information and preferences
To set up your user information and preferences in Git, you can use the git config command. Here are the basic commands to set up your name and email address:
git config --global user.name "Your Name"
git config --global user.email "youremail@example.com"You can also set other preferences such as the default text editor to use with Git, the default merge strategy, and the default branch to use when pushing changes.
To set your default text editor, use the following command:
git config --global core.editor "editor_name"Replace editor_name with the name of your preferred text editor. For example, if you use VS Code as your text editor, you would use:
git config --global core.editor "code --wait"To set the default merge strategy, use the following command:
git config --global merge.strategy "strategy_name"Replace strategy_name with the name of your preferred merge strategy. The default merge strategy in Git is recursive.
To set the default branch to use when pushing changes, use the following command:
git config --global push.default "branch_name"Replace branch_name with the name of your preferred branch. The default branch in Git is master.
These are just a few examples of the preferences you can set in Git. You can view and edit your Git configuration settings at any time by using the git config --list command.
Configuring Git aliases and other customizations
Git aliases can be used to create shortcuts for frequently used Git commands or to customize the behavior of Git commands. Here are some examples of Git aliases that can be useful:
-
alias ci='git commit': This creates an aliascifor thegit commitcommand, allowing you to commit changes with thecicommand instead of typing outgit commitevery time. -
alias co='git checkout': This creates an aliascofor thegit checkoutcommand, allowing you to switch branches with thecocommand instead of typing outgit checkoutevery time. -
alias st='git status': This creates an aliasstfor thegit statuscommand, allowing you to check the status of your repository with thestcommand instead of typing outgit statusevery time.
To set up Git aliases, you can use the git config command with the --global option to set them globally for your user:
git config --global alias.ci commit
git config --global alias.co checkout
git config --global alias.st statusThis sets up the three aliases mentioned above. You can also edit your .gitconfig file manually to add or modify aliases.
In addition to aliases, you can also customize various Git settings such as your default editor, merge strategy, and more. To configure Git settings, you can use the git config command with the --global option and the appropriate setting name:
git config --global core.editor "nano"
git config --global merge.ff falseThe first command sets your default editor to Nano, while the second command disables fast-forward merges by default. You can find more information on Git configuration settings in the Git documentation. Using Git configuration files to manage multiple Git profiles and environments Git configuration files can be used to manage multiple Git profiles and environments. This is useful if you work on different projects with different Git accounts or if you use Git in different environments, such as your work computer and your personal computer.
To set up multiple Git profiles, you can create a separate Git configuration file for each profile. For example, you can create a work.gitconfig file and a personal.gitconfig file. Each file can contain different user information, such as the name and email address, and different aliases and customizations.
To use a specific Git configuration file, you can specify it when running Git commands using the -c option. For example, to use the work.gitconfig file for a Git command, you can run:
git -c include.path=work.gitconfig <command>Alternatively, you can set up a global Git configuration file that includes the configurations for all your profiles. To do this, you can create a ~/.gitconfig file and include the configurations for each profile in the file. You can use the [include] section to include other Git configuration files. For example, the following ~/.gitconfig file includes the configurations for a work and a personal profile:
[user]
email = personal@email.com
name = Personal Name
[includeIf "gitdir:~/work/"]
path = work.gitconfig
[includeIf "gitdir:~/personal/"]
path = personal.gitconfigIn this example, the [user] section contains the configurations that are common to both profiles. The [includeIf] sections include the work.gitconfig and personal.gitconfig files based on the Git directory of the current repository.
By using Git configuration files, you can manage multiple Git profiles and environments easily and efficiently. Creating a new repository To create a new repository in Git, follow these steps:
- Create a new directory on your local machine where you want to store your project.
- Open a command prompt or terminal window and navigate to the new directory.
- Initialize a new Git repository in the directory using the command
git init. - Add your files to the new repository using the command
git add .(the period at the end specifies that you want to add all files in the current directory and its subdirectories). - Commit your changes to the repository using the command
git commit -m "Initial commit". - Set up a remote repository on a Git hosting service (such as GitHub or GitLab) and obtain its URL.
- Add the remote repository as a Git remote using the command
git remote add origin <remote URL>. - Push your changes to the remote repository using the command
git push -u origin master.
Once you have completed these steps, your new repository should be set up and ready to use. You can continue to add files, make changes, and commit your changes to the repository as needed, and push your changes to the remote repository to collaborate with others. Initializing a new Git repository from scratch To initialize a new Git repository from scratch, follow these steps:
- Open your terminal or command prompt and navigate to the directory where you want to create the repository.
- Use the
git initcommand to initialize a new Git repository in that directory.
For example:
cd /path/to/directory
git init-
You should see a message that says “Initialized empty Git repository in [directory]“. This means that Git has created a new repository and you are ready to start tracking changes.
-
Now you can add files to the repository using the
git addcommand, and then commit them using thegit commitcommand.
For example:
git add file1.txt file2.txt
git commit -m "Initial commit"This will add the files file1.txt and file2.txt to the repository and create a new commit with the message “Initial commit”.
Cloning an existing Git repository
To clone an existing Git repository, you can use the git clone command followed by the URL of the repository you want to clone. Here’s an example:
git clone https://github.com/username/repository-name.gitThis will create a new directory called repository-name in your current working directory and clone the contents of the remote repository into it. If you want to clone the repository into a different directory, you can specify the directory name as an additional argument:
git clone https://github.com/username/repository-name.git my-projectThis will clone the repository into a new directory called my-project.
If you want to clone a specific branch of the repository, you can use the -b option followed by the branch name:
git clone -b branch-name https://github.com/username/repository-name.gitThis will clone only the specified branch.
Note that you’ll need to have Git installed on your local machine to use the git clone command.
Importing an existing project into Git
To import an existing project into Git, you need to create a new Git repository and then add the files from your existing project to the new repository. Here are the general steps:
-
Create a new Git repository: Navigate to the parent directory of your existing project and run the command
git initto create a new Git repository. -
Add your existing files: Copy or move your existing project files into the new Git repository directory.
-
Stage your files: Run the command
git add .to stage all the files in the repository directory. -
Commit your files: Run the command
git commit -m "Initial commit"to commit the changes to the repository. -
Add a remote: If you want to push your changes to a remote repository, you need to add a remote. Run the command
git remote add origin <remote-repository-url>to add a remote named “origin” with the URL of your remote repository. -
Push your changes: Run the command
git push -u origin masterto push your changes to the remote repository.
Note that the exact steps may vary depending on your specific situation, such as whether your existing project is already in a version control system or not. Understanding Git workflow Git workflow refers to the series of steps and actions that are taken when working with Git to manage version control and collaboration. The typical Git workflow involves the following steps:
-
Create a repository: The first step is to create a new Git repository or clone an existing one to your local machine.
-
Create a branch: The next step is to create a new branch for your changes. This allows you to make changes without affecting the main codebase.
-
Make changes: Make your changes to the code or files in the branch.
-
Stage changes: Use the “git add” command to stage your changes. This tells Git which changes you want to commit.
-
Commit changes: Use the “git commit” command to commit your changes to the branch.
-
Push changes: Use the “git push” command to push your changes to the remote repository.
-
Create a pull request: If you are working in a team, create a pull request to merge your changes into the main codebase.
-
Review changes: Other team members can review your changes and provide feedback.
-
Merge changes: Once the changes have been reviewed and approved, merge the branch into the main codebase using the “git merge” command.
-
Repeat: Repeat the process for each new feature or change you want to make.
By following this workflow, you can manage version control and collaboration effectively, and ensure that everyone is working on the same codebase. The role of the Git staging area and commit history In Git, the staging area and commit history are essential components of the workflow.
The staging area is a buffer between your working directory and the commit history. It allows you to selectively choose which changes you want to include in your next commit. You can add changes to the staging area using the git add command, and you can see the changes that are currently staged using the git status command.
Once you have added changes to the staging area, you can commit them to the repository. A commit is a snapshot of the changes you have made to the repository, and it includes a message describing the changes. You can create a new commit using the git commit command.
The commit history is a log of all the changes that have been made to the repository over time. Each commit in the history includes a message, a timestamp, and a unique identifier called a hash. You can view the commit history using the git log command.
By using the staging area and commit history, you can carefully control the changes that are made to your repository and keep a record of every change that has been made. This allows you to collaborate with others and work on complex projects with confidence. Basic Git commands for creating, modifying, and viewing Git commits Sure, here are some basic Git commands for creating, modifying, and viewing Git commits:
git add <file>: Adds a file to the staging areagit commit -m "<commit message>": Commits the staged changes with a message describing the changes madegit status: Shows the status of the working directory and the staging areagit log: Displays the commit history in reverse chronological ordergit diff: Shows the changes between the working directory and the staging areagit diff <commit1> <commit2>: Shows the differences between two commitsgit show <commit>: Displays information about a specific commitgit rm <file>: Removes a file from both the working directory and the Git repositorygit mv <old-file> <new-file>: Renames a file in both the working directory and the Git repository
These commands are essential for basic Git usage, and they allow you to create, modify, and view Git commits effectively. The Git branching model and how to create and merge branches Git branching is a core concept in Git that allows developers to work on multiple versions of a project simultaneously. It enables developers to isolate features and fixes from the main codebase, work on them independently, and merge them back to the main codebase when they are ready.
The basic Git branching model involves creating a new branch from an existing one, making changes to the code in the new branch, and then merging the changes back into the original branch. This can be visualized as a tree structure, with the main branch (usually called the “master” branch) as the trunk and other branches as the branches.
To create a new branch, use the git branch command followed by the name of the new branch:
git branch <new-branch-name>To switch to the new branch, use the git checkout command:
git checkout <new-branch-name>Alternatively, you can create and switch to a new branch in one step using the git checkout command with the -b option:
git checkout -b <new-branch-name>To view all branches in the repository, use the git branch command without any arguments:
git branchTo delete a branch, use the git branch command with the -d option followed by the name of the branch to be deleted:
git branch -d <branch-name>To merge changes from one branch into another, use the git merge command. First, switch to the branch that you want to merge changes into (the “receiving” branch):
git checkout <receiving-branch>Then, run the git merge command with the name of the branch containing the changes (the “source” branch):
git merge <source-branch>Git also provides several tools for managing conflicts that may arise when merging changes from different branches. These include the git mergetool command, which opens a visual merge tool to help resolve conflicts, and the git rebase command, which can be used to apply changes from one branch to another in a more controlled manner.
By using Git branches effectively, developers can work on different features or bug fixes simultaneously without affecting each other’s work. This can lead to a more efficient development process and a more stable and reliable codebase. The Git remote model and how to work with remote repositories The Git remote model is the way Git manages the relationship between the local repository and the remote repository. A remote repository is a version of the project hosted on a remote server, such as GitHub or GitLab. When working with remote repositories, Git provides a set of commands to help you interact with them.
Here are some common Git commands for working with remote repositories:
git clone [remote-url]: Creates a local copy of the remote repository on your machine. This command only needs to be run once to create the initial clone.git remote -v: Lists all the remote repositories associated with the local repository and their URLs.git fetch: Downloads any changes from the remote repository to the local repository, but doesn’t merge them.git pull: Downloads any changes from the remote repository and merges them into the local branch.git push: Uploads any changes from the local repository to the remote repository.
To work with remote repositories, you’ll need to have permission to access them. This typically involves creating an account on the hosting service and configuring your Git credentials. Once you have access, you can use these commands to collaborate with others and keep your local repository in sync with the remote repository. The role of Git tags and how to create and manage them Git tags are a way to mark a specific point in the Git commit history as significant, such as a release or a milestone. They are like bookmarks to specific commits that can be easily referenced later. Tags are often used to indicate versions or releases of a software project, but can also be used for other important points in the commit history.
To create a new Git tag, you can use the git tag command followed by the name of the tag and the commit hash you want to tag. For example:
git tag v1.0.0 4b5f8a1This will create a new tag called v1.0.0 at the commit with the hash 4b5f8a1. You can also create an annotated tag, which includes a message and other metadata, by adding the -a flag:
git tag -a v1.0.0 4b5f8a1 -m "Release version 1.0.0"This will create an annotated tag with the message “Release version 1.0.0”.
To push tags to a remote repository, you can use the git push command followed by the --tags flag:
git push --tagsThis will push all local tags to the remote repository. If you want to push a specific tag, you can use the tag name:
git push origin v1.0.0To list all tags in a repository, you can use the git tag command without any arguments:
git tagThis will list all local tags. To list all tags, including tags in remote repositories, you can use the git tag command with the -a flag:
git tag -aThis will list all tags, including annotated tags, in the local repository and any remote repositories that have been fetched. Using Git with graphical interfaces Git can be used with graphical user interfaces (GUI) as an alternative to the command-line interface. Git GUI tools provide a more visual and user-friendly way to interact with Git repositories, which can be helpful for beginners or those who prefer a more visual approach.
Some popular Git GUI tools include:
-
GitHub Desktop: A desktop application that provides a visual interface for working with Git repositories hosted on GitHub.
-
GitKraken: A cross-platform Git GUI tool that supports multiple Git services, including GitHub, GitLab, and Bitbucket.
-
Sourcetree: A free Git GUI tool that is available for Windows and macOS. It provides a visual representation of Git branches and allows users to easily create and merge branches.
-
Git Cola: A lightweight and open-source Git GUI tool that is available for Linux, macOS, and Windows.
-
Gitg: A graphical user interface for Git that is available for Linux.
These tools provide a range of features, such as visual commit history, diff views, and merge conflict resolution. However, it’s important to note that using a GUI tool doesn’t replace the need for understanding Git concepts and commands. It’s still recommended to have a good understanding of Git fundamentals, as well as using the command-line interface, in order to effectively use Git. Overview of popular Git GUIs such as GitKraken, Sourcetree, and GitAhead There are several popular Git GUIs available, each with its own unique features and interfaces. Some of the most popular Git GUIs are:
-
GitKraken: GitKraken is a popular Git GUI that offers a clean and intuitive interface for managing Git repositories. It supports Git workflows like merging, rebasing, and cloning, and provides useful visualizations of branches and commits.
-
Sourcetree: Sourcetree is a free Git GUI for Windows and Mac that provides an easy-to-use interface for managing Git repositories. It supports Git workflows like merging, rebasing, and cloning, and provides an interactive history view of commits.
-
GitAhead: GitAhead is a fast and lightweight Git GUI that provides an intuitive interface for managing Git repositories. It supports Git workflows like merging, rebasing, and cloning, and provides a simple and streamlined interface for committing changes and managing branches.
-
GitHub Desktop: GitHub Desktop is a Git GUI designed specifically for working with Git repositories hosted on GitHub. It provides a simple and streamlined interface for managing Git repositories, and supports workflows like merging, rebasing, and cloning.
-
TortoiseGit: TortoiseGit is a Git GUI for Windows that integrates with Windows Explorer. It provides a context menu in Windows Explorer for managing Git repositories, and supports workflows like merging, rebasing, and cloning.
Each of these Git GUIs offers a unique set of features and benefits, so it’s worth exploring them to find the one that best fits your needs and workflow. Installing and configuring Git GUIs for optimal use Installing and configuring Git GUIs can vary depending on the GUI you choose to use. However, here are some general steps you can follow to install and configure popular Git GUIs:
GitKraken
- Download and install GitKraken from their official website.
- Once installed, launch GitKraken and log in or sign up for an account.
- When prompted, connect GitKraken to your Git hosting service (e.g. GitHub, GitLab, Bitbucket) by entering your credentials.
- GitKraken will automatically detect your Git repositories, and you can begin working with them using the GUI interface.
Sourcetree
- Download and install Sourcetree from their official website.
- Once installed, launch Sourcetree and log in or sign up for an account.
- When prompted, connect Sourcetree to your Git hosting service (e.g. GitHub, GitLab, Bitbucket) by entering your credentials.
- Sourcetree will automatically detect your Git repositories, and you can begin working with them using the GUI interface.
GitAhead
- Download and install GitAhead from their official website.
- Once installed, launch GitAhead and select “File” -> “Open repository” to open an existing Git repository, or “File” -> “New repository” to create a new Git repository.
- GitAhead will automatically detect your Git repositories, and you can begin working with them using the GUI interface.
Once you have installed and configured a Git GUI, you can use it to perform many of the same Git commands and workflows as the command line interface. However, be aware that some Git GUIs may have slightly different workflows or terminology than the command line interface, so it is important to familiarize yourself with the specific GUI you are using. Using Git GUIs to visualize Git history, branches, and diffs Git GUIs offer a visual way to work with Git repositories, making it easier to visualize Git history, branches, and diffs. Here are some common features and capabilities of Git GUIs:
-
History view: This provides a visual representation of the commit history in your repository. You can see the commit messages, dates, and authors, and you can also view the files that were changed in each commit.
-
Branch view: This shows the current branches in your repository, including their names and the commits they are based on. You can also create new branches, switch between branches, and merge branches from this view.
-
Diff view: This allows you to compare different versions of a file and see the changes that were made between them. You can also view side-by-side diffs and merge conflicts.
-
Committing changes: Git GUIs allow you to stage changes and commit them with a message, just like you would with the command line. Some GUIs also provide additional features, such as the ability to selectively stage changes or amend previous commits.
-
Working with remotes: Git GUIs make it easy to work with remote repositories, allowing you to push and pull changes, view the status of your local and remote branches, and manage remote URLs and credentials.
Popular Git GUIs include GitKraken, Sourcetree, and GitAhead. Each of these tools provides a unique set of features and capabilities, so it’s worth exploring them to see which one best fits your needs. Common Git workflows and scenarios Here are some common Git workflows and scenarios:
-
Centralized Workflow: In this workflow, there is a central repository that all developers work from. Developers clone the central repository to their local machine, make changes, and push the changes back to the central repository. This workflow is simple and easy to understand, but can lead to conflicts if multiple developers are working on the same code.
-
Feature Branch Workflow: In this workflow, each new feature or bug fix is developed on its own branch. Developers work on their local machine, creating new branches from the main branch, and then merge the changes back into the main branch when the feature is complete. This workflow allows for easier collaboration between developers and reduces the chance of conflicts.
-
Gitflow Workflow: This workflow is an extension of the feature branch workflow and is specifically designed for software releases. It involves the use of a master branch and a development branch. Features and bug fixes are developed on feature branches, which are then merged into the development branch. Once the development branch is stable, it is merged into the master branch, which represents the released version of the software.
-
Forking Workflow: In this workflow, each developer forks the main repository into their own repository, and then creates a new feature branch in their own repository. They make changes and push the changes back to their own repository. They then create a pull request to merge the changes into the main repository. This workflow is commonly used in open-source projects where contributors do not have write access to the main repository.
-
Git Rebase Workflow: This workflow involves rewriting the commit history to create a cleaner and more organized history. It involves using the “git rebase” command to take all the changes made on one branch and replay them on top of another branch. This workflow is useful for cleaning up a messy commit history and making it easier to understand.
These are just a few of the many Git workflows and scenarios. The best workflow for your team will depend on the size of your team, the complexity of your project, and your specific needs and goals. Creating a new feature branch and submitting a pull request Sure, here is a brief overview of creating a new feature branch and submitting a pull request workflow using Git:
- Make sure you are on the main branch of your Git repository by running the following command:
git checkout main- Create a new feature branch from the main branch by running the following command:
git checkout -b feature/my-new-featureReplace my-new-feature with a descriptive name for your new feature.
- Make the necessary changes to your codebase and commit them to your local feature branch:
git add .
git commit -m "Add new feature"- Push your local feature branch to the remote repository:
git push -u origin feature/my-new-featureThis will create a new feature branch on the remote repository and set up a tracking relationship between your local and remote branches.
-
Open a pull request on the remote repository’s website by navigating to the branch and clicking “Create pull request”. Provide a descriptive title and description of your changes and submit the pull request.
-
Wait for feedback from other contributors and make any necessary changes to your feature branch until it is ready to be merged.
-
Once your changes are approved, merge your feature branch into the main branch by running the following commands:
git checkout main
git pull origin main
git merge --no-ff feature/my-new-feature- Push the changes to the remote repository:
git push origin mainThat’s it! Your new feature has been merged into the main branch of the repository. Reviewing and merging pull requests When using Git for collaboration, pull requests are a common way for contributors to propose changes to a codebase and for maintainers to review and merge those changes. Here are the general steps for reviewing and merging a pull request:
-
Review the code changes: The first step is to review the changes made in the pull request. Depending on the size and complexity of the changes, this could involve testing the code, reading through the code changes, and discussing any questions or concerns with the contributor.
-
Provide feedback: If any issues or areas for improvement are identified during the code review, provide feedback to the contributor. This could involve leaving comments directly on the pull request, opening issues to track specific tasks, or having discussions in a chat or video call.
-
Merge the pull request: Once the changes have been reviewed and any issues have been addressed, the pull request can be merged into the main codebase. Depending on the Git hosting service being used, there may be options to squash or rebase the commits before merging, or to automatically run tests or other checks before allowing the merge.
-
Close the pull request: After the pull request has been merged, close the pull request to indicate that the changes have been successfully merged into the codebase.
It’s worth noting that the exact process for reviewing and merging pull requests can vary depending on the team or project being worked on. Some teams may have strict review processes or use automated tools to help with the code review process, while others may have more relaxed processes. Ultimately, the goal is to ensure that any changes being made to the codebase are thoroughly reviewed and tested before being merged. Resolving merge conflicts and other Git issues When working collaboratively on a Git repository, it is common to encounter merge conflicts and other issues that need to be resolved. Here are some tips for resolving common Git issues:
-
Merge conflicts: Merge conflicts occur when two or more developers make changes to the same file and Git is unable to automatically merge the changes. To resolve merge conflicts, you will need to manually edit the conflicting file(s) to incorporate both sets of changes. After editing the file(s), you will need to stage the changes and commit them.
-
Undoing changes: If you need to undo a change that has already been committed, you can use the
git revertcommand. This creates a new commit that undoes the changes made by a previous commit. -
Deleting files: If you need to delete a file from a Git repository, you should use the
git rmcommand to remove the file from Git and the filesystem. -
Moving and renaming files: If you need to move or rename a file, you should use the
git mvcommand. This will move or rename the file in the Git repository and update the file path in all commits that reference the file. -
Recovering lost commits: If you accidentally delete a commit or lose a commit due to a Git error, you may be able to recover the lost commit using the
git reflogcommand. This command shows a log of all changes to the Git repository, including commits that may no longer be visible in the Git history. -
Reverting to a previous commit: If you need to revert to a previous commit, you can use the
git resetcommand. This will reset the Git repository to the specified commit and discard any subsequent commits. -
Stashing changes: If you need to temporarily save changes to a Git repository without committing them, you can use the
git stashcommand. This will save the changes to a temporary “stash” and allow you to switch to a different branch or commit. -
Using Git bisect: If you are trying to track down the source of a bug or issue in a Git repository, you can use the
git bisectcommand. This command allows you to perform a binary search through the Git history to locate the commit that introduced the bug. Using Git for code reviews and feedback Git is a powerful tool not only for version control but also for code reviews and collaboration. Here are some tips for using Git for code reviews and feedback: -
Use feature branches: Use feature branches to isolate changes and facilitate review. Reviewers can easily see the changes that are being proposed, and it is easy to revert changes if necessary.
-
Use pull requests: Use pull requests to facilitate the review process. Pull requests allow reviewers to provide feedback and suggestions, and they also make it easy to merge changes once they have been reviewed.
-
Use code review tools: Use tools like GitHub, GitLab, or Bitbucket to facilitate code reviews. These tools provide a user-friendly interface for reviewing changes, allowing reviewers to provide feedback directly on the code.
-
Use inline comments: Use inline comments to provide feedback and suggestions on specific lines of code. Inline comments allow reviewers to provide specific feedback without having to review the entire file.
-
Use code standards and linting: Use code standards and linting tools to ensure that code is consistent and meets established standards. This can make the review process faster and more effective, as reviewers can focus on the substance of the code rather than nitpicking about formatting.
-
Be constructive: When providing feedback, be constructive and respectful. Remember that the goal is to improve the code, not to criticize the author. Provide suggestions and recommendations for improvement, rather than simply pointing out flaws.
-
Provide context: When providing feedback, provide context for your comments. Explain why you are making a particular suggestion or why you think a particular change is necessary. This can help the author understand your feedback and make more effective changes.
-
Use automated testing: Use automated testing to ensure that changes are working as expected. Automated testing can help catch bugs and other issues early in the review process, making it easier to identify and fix issues before they become bigger problems.
By following these tips, you can use Git to facilitate effective code reviews and collaboration, improving the quality of your code and making it easier to work with others on your team.
Chapter 2: Basic Git Operations
Adding and committing changes To add and commit changes in Git, follow these steps:
- Make changes to files in your local repository.
- Use the
git addcommand to stage the changes you want to commit. For example, if you want to stage all changes, you can rungit add .(the dot means all files and directories in the current directory). If you only want to stage changes to a specific file, you can rungit add <file>. - Use the
git commitcommand to commit the staged changes. For example, you can rungit commit -m "Commit message"to commit the changes with a message describing what was changed.
It’s important to note that commits should be small, focused, and self-contained. A commit should only include changes that are related to a specific task or feature. This makes it easier to understand the changes when reviewing the commit history and to revert changes if needed. The Git staging area and how to add files to it The Git staging area is a way to organize and review changes before committing them to the repository. It allows you to control which changes will be included in the next commit and which will be left out.
To add files to the staging area, you use the git add command followed by the file or directory you want to add. For example, to add a single file, you can use:
git add filename.txtTo add all changes in the current directory and its subdirectories, you can use:
git add .You can also add specific parts of a file using the interactive mode with:
git add -pThis will let you review each change and choose whether to add it to the staging area or not.
Once you have added all the changes you want to include in the next commit, you can use the git commit command to create a new commit with the changes in the staging area.
Creating and modifying Git commits
Creating and modifying Git commits involves a series of steps that allow you to manage the changes made to your codebase. Here are the basic steps:
-
Modify your code: Make changes to your code, either by writing new code or modifying existing code.
-
Stage your changes: Use the
git addcommand to add your changes to the staging area. The staging area is a buffer where you can review your changes before committing them to the repository. -
Review your changes: Use the
git diff --stagedcommand to review the changes in the staging area. This will show you the difference between the files in the staging area and the last commit. -
Create a commit: Use the
git commitcommand to create a new commit that includes the changes in the staging area. The commit will have a unique identifier that allows you to reference it later. -
Write a commit message: When you create a commit, you should also write a commit message that describes the changes you made in the commit.
-
Push your changes: Once you have committed your changes, use the
git pushcommand to push the changes to a remote repository.
Here are some additional tips for creating and modifying Git commits:
-
Keep commits small: Make small, focused commits that only address one issue or change at a time. This makes it easier to review and understand your changes.
-
Use descriptive commit messages: Write commit messages that are descriptive and explain the changes you made. This makes it easier for others to understand your changes when reviewing the code.
-
Review your changes before committing: Use the
git diffcommand to review your changes before committing them. This helps you catch any mistakes or unintended changes. -
Use the
--amendoption to modify the last commit: If you forgot to add a file or made a mistake in your last commit, you can use thegit commit --amendcommand to modify the last commit. This will open your default text editor and allow you to modify the commit message or add additional changes to the commit. -
Use Git aliases to simplify the commit process: You can create Git aliases to simplify the process of staging and committing changes. For example, you can create an alias that combines the
git addandgit commitcommands into a single command. Using Git commit messages effectively Using Git commit messages effectively is an essential part of Git usage. A well-written Git commit message provides clear and concise information about the changes made in a commit, which is helpful for understanding the purpose of the commit and tracking the history of the project. Here are some tips for writing effective Git commit messages:
-
Start with a summary: The first line of the commit message should be a short summary of the changes made in the commit. The summary should be descriptive and specific, but not too long.
-
Use the imperative mood: The summary should be written in the imperative mood, such as “Add”, “Fix”, “Update”, etc. This makes the message more actionable and easier to understand.
-
Provide more details: After the summary, provide more details about the changes made in the commit. This could include information about why the changes were made, how they were implemented, and any other relevant details.
-
Keep it concise: While it’s important to provide enough detail, it’s also important to keep the commit message concise. A good rule of thumb is to keep the message under 72 characters.
-
Use proper formatting: Use proper formatting to make the commit message easy to read. Separate the summary from the details with a blank line, and use bullet points or numbered lists if appropriate.
-
Use Git conventions: Git has some conventions for commit messages that you can follow, such as starting the summary with a capital letter and not ending it with a period. These conventions help keep commit messages consistent and easy to read.
-
Review before committing: Before committing, review the commit message to make sure it accurately describes the changes made in the commit.
By following these tips, you can write effective Git commit messages that make it easy to understand the changes made in a commit and track the history of your project. Best practices for committing frequently and keeping commits small and focused Here are some best practices for committing frequently and keeping commits small and focused:
-
Commit early and often: Make small and frequent commits to keep track of changes and make it easier to identify when and where errors occurred.
-
Keep each commit focused: Each commit should be focused on a single change or feature. Avoid including unrelated changes in the same commit.
-
Write clear commit messages: Write descriptive and concise commit messages that explain what changes were made and why. This will help others understand the purpose of the commit and make it easier to search for specific changes later on.
-
Use Git’s staging area: Use Git’s staging area (also known as the index) to review changes before committing them. This allows you to review and selectively stage changes, keeping each commit focused on a single change.
-
Test changes before committing: Always test changes locally before committing them. This can help catch errors or issues before they are pushed to a shared repository.
-
Use interactive rebase to clean up commits: Use interactive rebase to combine, split, or reorder commits before pushing them to a shared repository. This can help keep the commit history clean and focused.
-
Avoid committing large binary files: Avoid committing large binary files such as images, videos, and binary executables directly to a repository. Instead, use Git LFS (Large File Storage) or other external storage solutions.
By following these best practices, you can maintain a clean and focused commit history that makes it easier to understand and manage changes over time.
Viewing the commit history
To view the commit history in Git, you can use the git log command. This command displays a list of all the commits in the repository, in reverse chronological order (i.e., most recent first). Here’s an example:
$ git log
commit 8257a0d6d618b7f1965e5e5ebf9d1a534eb12a45 (HEAD -> master, origin/master)
Author: Jane Smith <jane.smith@example.com>
Date: Tue Apr 27 10:22:42 2021 -0400
Add new feature
commit 36b4785b25e9b76d5d21f2c3f55a3df0e82c78d2
Author: John Doe <john.doe@example.com>
Date: Mon Apr 26 16:49:32 2021 -0400
Fix bug in login page
commit a9d9c7f51182e11b14f7dc8b24fcddcccb34e6fa
Author: Jane Smith <jane.smith@example.com>
Date: Mon Apr 26 12:03:11 2021 -0400
Update README fileEach commit is displayed with a hash code (a unique identifier for the commit), the author, the date, and the commit message. You can use various options with the git log command to customize the output, such as filtering by author or date range, displaying a certain number of commits, or formatting the output in a specific way.
Additionally, there are several graphical tools and GUI clients that can display the commit history in a more visual way, such as GitKraken, Sourcetree, and GitAhead. These tools can also provide additional features such as filtering, searching, and branching visualization.
Using Git log to view commit history and metadata
Yes, that’s correct! The git log command is used to view the commit history of a Git repository. It shows a list of all the commits in reverse chronological order, with the most recent commit appearing first.
By default, git log displays the following information for each commit:
- Commit hash (SHA-1 checksum)
- Author’s name and email address
- Date and time of the commit
- Commit message
There are many options and flags that can be used with git log to customize the output and filter the results. For example, you can use the --oneline option to display each commit on a single line, or the --graph option to show a graph of the commit history with branches and merges.
Some other useful git log options include:
--sinceand--untilto filter the results by date or time range--authorand--committerto filter the results by author or committer--grepto search the commit messages for a specific string--prettyto format the output in various ways
git log is a powerful command that can provide valuable insights into the history of a Git repository. By using it regularly, you can track changes, identify issues, and gain a better understanding of the development process.
Filtering and searching Git history with Git log options
Git log is a command in Git that can be used to view the commit history of a repository. It provides a lot of options that allow you to filter and search through the history to find the information you need. Here are some useful options:
-
--oneline: This option prints each commit on a single line, making it easier to scan through the history. It displays the commit hash and the first line of the commit message. -
--author=<name>: This option shows only the commits made by the specified author. -
--grep=<pattern>: This option searches the commit messages for the specified pattern. -
--after=<date>and--before=<date>: These options show only the commits made after or before the specified date, respectively. -
--since=<time>and--until=<time>: These options show only the commits made since or until the specified time, respectively. -
--stat: This option shows the number of files that were changed in each commit, along with the number of lines that were added and deleted. -
--graph: This option shows a graphical representation of the commit history, with each branch shown as a separate line. -
--decorate: This option adds extra information to the output, such as branch and tag names.
These options can be combined to create more powerful queries. For example, you can use --author=<name> --grep=<pattern> --since=<time> to search for all commits made by a specific author that contain a certain pattern and were made since a certain time.
Visualizing Git history with graphical tools such as gitk and GitKraken
Yes, Git provides several graphical tools to visualize Git history, such as gitk, GitKraken, Sourcetree, and others. These tools allow you to view the commit history, branches, and tags in a more intuitive and interactive way.
Gitk is a graphical user interface for Git that comes bundled with the Git installation. It allows you to view the history of a Git repository in a tree or graph format, browse the details of each commit, and search for specific commits based on various criteria.
GitKraken is a popular Git GUI that offers a range of features for managing Git repositories, including a visual Git history and branch view, pull request and code review functionality, and collaboration tools. With GitKraken, you can view the history of your Git repository, explore the relationships between branches, tags, and commits, and even create and merge branches directly from the interface.
Sourcetree is another popular Git GUI that offers a range of features for managing Git repositories, including a visual history and branch view, pull request and code review functionality, and collaboration tools. With Sourcetree, you can view the history of your Git repository, explore the relationships between branches, tags, and commits, and even create and merge branches directly from the interface.
These tools can be helpful in visualizing the relationships between different commits, branches, and tags in a Git repository, which can make it easier to understand the history of the project and to navigate and manage the repository more effectively. Undoing changes In Git, there are several ways to undo changes that have been made to your repository. Here are a few common scenarios and the corresponding Git commands to undo changes:
-
Discard changes in the working directory: If you have made changes to a file in your working directory but haven’t yet staged them, you can discard the changes with the
git checkoutcommand. For example, if you have made changes tofile.txt, you can discard the changes with the following command:git checkout -- file.txtThis will replace the changes in your working directory with the contents of the file in the most recent commit.
-
Unstage changes: If you have staged changes but haven’t yet committed them, you can unstage them with the
git resetcommand. For example, if you have staged changes tofile.txt, you can unstage them with the following command:git reset file.txtThis will unstage the changes and move the file back to the working directory.
-
Undo a commit: If you have committed changes but haven’t yet pushed them to a remote repository, you can undo the commit with the
git resetcommand. For example, if you want to undo the most recent commit, you can use the following command:git reset HEAD~1This will reset the repository to the commit before the most recent one. Note that this will discard the changes in the most recent commit, so be careful when using this command.
-
Revert a commit: If you have committed changes and pushed them to a remote repository, you can revert the commit with the
git revertcommand. For example, if you want to revert the most recent commit, you can use the following command:git revert HEADThis will create a new commit that undoes the changes in the most recent commit.
-
Restore a deleted file: If you have deleted a file from your repository and want to restore it, you can use the
git checkoutcommand. For example, if you have deletedfile.txt, you can restore it with the following command:git checkout HEAD -- file.txtThis will restore the file from the most recent commit. Reverting changes with Git revert Yes, you can use the
git revertcommand to undo changes in Git. Thegit revertcommand creates a new commit that undoes the changes made by a previous commit, effectively reverting the repository to the state it was in before the commit was made.
Here’s an example:
Suppose you have a commit with the hash 123456 that made some changes you want to undo. You can revert that commit by running the following command:
git revert 123456Git will create a new commit that undoes the changes made by the previous commit. You can then push the new commit to the repository to share the changes with others.
Note that git revert does not delete or remove any commits. Instead, it adds a new commit that undoes the changes made by a previous commit, so the commit history remains intact.
Resetting the Git HEAD pointer with Git reset
In Git, the HEAD pointer points to the latest commit in the current branch. git reset is a command that allows you to move the HEAD pointer to a different commit. This can be useful in situations where you need to undo changes or start over from a previous state.
There are three types of git reset commands:
-
Soft reset: This type of reset moves the
HEADpointer to a previous commit, but keeps the changes made in the commits after that. This means that the changes made in the later commits will still be staged, ready to be committed again. To perform a soft reset, use the following command:git reset --soft <commit> -
Mixed reset: This type of reset moves the
HEADpointer to a previous commit, and unstages the changes made in the commits after that. This means that the changes made in the later commits will not be staged, and you will have to add them again before committing. To perform a mixed reset, use the following command:git reset --mixed <commit> -
Hard reset: This type of reset moves the
HEADpointer to a previous commit, and discards the changes made in the commits after that. This means that the changes made in the later commits will be permanently lost. To perform a hard reset, use the following command:git reset --hard <commit>
It’s important to note that git reset can be a dangerous command, especially when used with the --hard option, as it can permanently delete changes that cannot be recovered. Therefore, it’s recommended to use it with caution and only when you fully understand its consequences.
Stashing changes and applying them later with Git stash
In Git, stashing is the process of temporarily saving changes that are not yet committed. This can be useful when you need to switch branches or work on something else temporarily without committing your changes. Git stash allows you to store these changes and apply them later when you’re ready to work on them again.
To stash changes in Git, you can use the git stash command followed by any options you want to use. By default, git stash will stash all changes to tracked files in your working directory, including changes in the staging area. Here’s an example:
$ git stash
Saved working directory and index state WIP on feature-branch: 1234567 Add new featureThis will create a new stash with a default message indicating that the working directory and index state have been saved. The message will also include the name of the branch you’re currently on and the hash of the most recent commit on that branch.
If you want to provide your own message, you can use the -m or --message option followed by your message. For example:
git stash save -m "Save changes before switching branches"To apply your stashed changes, you can use the git stash apply command followed by the name of the stash you want to apply. For example:
git stash apply stash@{0}By default, git stash apply will apply the most recent stash. If you have multiple stashes, you can specify which one to apply by using the stash reference syntax (stash@{n}) where n is the number of the stash you want to apply.
You can also use the git stash pop command to apply and remove the most recent stash. This is equivalent to running git stash apply followed by git stash drop.
If you want to view your stashes, you can use the git stash list command. This will show you a list of all your stashes, including their reference names, messages, and the branch they were created on. For example:
$ git stash list
stash@{0}: WIP on feature-branch: 1234567 Add new feature
stash@{1}: WIP on master: 2345678 Fix bugTo remove a stash, you can use the git stash drop command followed by the name of the stash you want to remove. For example:
git stash drop stash@{1}This will remove the second stash from the list. If you want to remove all stashes, you can use the git stash clear command. This will delete all stashes and cannot be undone, so be careful when using it.
Recovering lost commits and data with Git reflog and Git fsck
Git reflog and Git fsck are useful commands for recovering lost commits and data in Git.
Git reflog is a command that shows a log of all the changes to the Git HEAD pointer, including commits, branch creations and deletions, and merges. This can be useful for recovering lost commits that were accidentally deleted or lost due to a Git history rewrite.
To use Git reflog, simply type git reflog in the terminal in your Git repository. This will show a list of all the changes to the Git HEAD pointer. You can then use the commit hash of the lost commit to recover it.
Git fsck is a command that checks the integrity of your Git repository and can help recover lost or corrupted data. Git fsck checks for missing or corrupt objects in the Git object database, and can also check for dangling commits or unreachable branches.
To use Git fsck, type git fsck in the terminal in your Git repository. This will show a list of any missing or corrupt objects in your Git object database. If Git fsck finds any issues, it will report them and suggest ways to recover the lost data.
It’s important to note that both Git reflog and Git fsck should be used with caution, as they can make changes to your Git repository. It’s recommended to create a backup of your Git repository before using these commands, and to seek the assistance of an experienced Git user if you’re not familiar with their usage. Branching and merging Branching and merging are core concepts in Git, and they are essential to working with Git effectively. Branching allows developers to create a copy of the codebase that can be modified independently without affecting the main codebase. Merging allows developers to combine changes made in separate branches into a single branch, which helps maintain the integrity of the codebase.
In Git, a branch is simply a pointer to a specific commit. When a new branch is created, Git creates a new pointer to the current commit, and all subsequent changes are recorded on that branch. Developers can switch between branches to work on different features or fixes, and merge changes from one branch into another.
Here are some key Git commands related to branching and merging:
git branch: This command is used to create a new branch or list existing branches.git checkout: This command is used to switch between branches.git merge: This command is used to combine changes from one branch into another.git merge --no-ff: This command is used to force Git to create a new merge commit even if the changes could be fast-forwarded.git rebase: This command is used to apply changes from one branch onto another branch.
When using Git for branching and merging, it’s important to follow best practices to ensure the integrity of the codebase. Here are a few best practices:
- Create branches for new features or fixes.
- Merge changes from a branch into the main branch as soon as they are ready to minimize conflicts.
- Use descriptive branch names to make it easy to understand the purpose of the branch.
- Use merge commits to preserve a clear history of changes made to the codebase.
- Avoid using
git mergeto merge changes from the main branch into a feature branch; instead, usegit rebase. - Use
git merge --no-ffto create a new merge commit even if the changes could be fast-forwarded. This helps preserve a clear history of changes made to the codebase.
By following these best practices, developers can use Git effectively to manage code changes and ensure the integrity of the codebase. Creating and managing Git branches In Git, a branch is a separate line of development that diverges from the main codebase, allowing you to work on new features or bug fixes without affecting the main codebase. You can create new branches, switch between them, and merge them to incorporate changes into the main branch. Here are the basic Git commands for creating and managing branches:
-
git branch: This command shows a list of all the branches in your repository. The current branch is indicated with an asterisk. -
git branch <branch-name>: This command creates a new branch with the given name. -
git checkout <branch-name>: This command switches to the branch with the given name. You can also create and switch to a new branch in one step withgit checkout -b <new-branch-name>. -
git merge <branch-name>: This command merges the changes from the specified branch into the current branch. -
git branch -d <branch-name>: This command deletes the specified branch. Note that you can’t delete the branch you’re currently on, so you need to switch to another branch first. -
git branch -m <old-branch-name> <new-branch-name>: This command renames the specified branch.
In addition to these basic commands, Git provides a range of options and flags for more advanced branch management, such as rebasing, cherry-picking, and resolving conflicts during merges. It’s important to understand the implications of each of these commands and to use them carefully, as incorrect use can lead to data loss or other issues.
Recovering lost commits and data with Git reflog and Git fsck
Git reflog is a powerful tool that can help recover lost commits and data. It keeps track of all the changes that have been made to a repository, including commits that have been deleted or otherwise lost.
To access the reflog, use the command git reflog. This will display a list of all the commits and other actions that have been performed on the repository. Each entry in the reflog will have a unique identifier, which can be used to restore lost data.
If a commit has been deleted or lost, you can use the reflog to find the commit’s identifier and then use the git cherry-pick command to restore the commit to the repository.
In some cases, the lost data may not be recoverable using the reflog. In these situations, the git fsck command can be used to check the repository’s object database for any corrupted or missing data.
To use the git fsck command, simply run git fsck in the repository’s root directory. This will perform a check on the object database and report any issues that are found. If any missing or corrupted data is found, it may be possible to recover it using other methods.
Remember that it is always best to avoid losing data in the first place by regularly committing changes, pushing to remote repositories, and backing up your work. However, if data is lost, Git provides several powerful tools that can help recover it.
Branching and merging
Branching and merging are two of the most important features of Git. They allow multiple developers to work on different features or bug fixes simultaneously without interfering with each other’s work.
A branch is essentially a copy of the main codebase that developers can work on independently. By default, Git creates a branch called “master” when a new repository is created. Developers can create new branches using the git branch command, specifying a name for the new branch.
To switch to a different branch, use the git checkout command followed by the name of the branch. For example, to switch to a branch called “feature-branch”, use git checkout feature-branch.
Once work is complete on a branch, it can be merged back into the main codebase using the git merge command. To merge a branch into the current branch, use git merge branch-name.
If multiple developers are working on the same codebase, it’s important to ensure that changes don’t conflict with each other when merging branches. This can be achieved by regularly pulling changes from the main codebase using git pull and resolving any conflicts that arise.
If conflicts are found during a merge, Git will prompt the developer to resolve them. The git mergetool command can be used to launch a graphical tool to help with the resolution of conflicts.
By using branching and merging effectively, developers can collaborate on codebases more efficiently and avoid conflicts that can cause delays and errors.
Creating and managing Git branches
Creating and managing Git branches is an important part of working with Git. Branches allow developers to work on different features or bug fixes independently without affecting the main codebase.
To create a new branch, use the git branch command followed by the name of the new branch. For example, to create a new branch called “feature-branch”, use git branch feature-branch.
To switch to the new branch, use the git checkout command followed by the name of the branch. For example, to switch to the “feature-branch”, use git checkout feature-branch.
To delete a branch, use the git branch -d command followed by the name of the branch. For example, to delete the “feature-branch”, use git branch -d feature-branch. Note that you cannot delete the branch you are currently on.
To see a list of all branches in the repository, use the git branch command without any arguments. The current branch will be highlighted with an asterisk.
It’s a good practice to regularly merge changes from the main codebase into your branch to keep it up to date. This can be achieved using the git merge command. For example, to merge changes from the “main” branch into the current branch, use git merge main.
If multiple developers are working on the same codebase, it’s important to ensure that changes don’t conflict with each other when merging branches. This can be achieved by regularly pulling changes from the main codebase using git pull and resolving any conflicts that arise.
By using branches effectively, developers can work on codebases more efficiently and avoid conflicts that can cause delays and errors.
Switching between branches with Git checkout
In Git, switching between branches is done using the git checkout command. This command allows you to switch between existing branches, create new branches, and discard changes made to files.
To switch to an existing branch, use git checkout followed by the name of the branch. For example, to switch to a branch called “feature-branch”, use git checkout feature-branch.
If you have uncommitted changes in your current branch, Git will prevent you from switching to another branch until those changes are either committed or discarded. You can discard changes to a file using the git checkout command followed by the name of the file. For example, to discard changes to a file called “index.html”, use `git checkout index..
To create a new branch and switch to it at the same time, use git checkout -b followed by the name of the new branch. For example, to create a new branch called “new-branch” and switch to it, use git checkout -b new-branch.
If you want to switch to a specific commit or tag, use git checkout followed by the commit or tag name. For example, to switch to a commit with the hash “123456”, use git checkout 123456.
It’s important to note that when you switch between branches, any changes you made in the previous branch will not be carried over to the new branch. If you want to carry over changes, you must commit them first and then merge or rebase them into the new branch.
By using the git checkout command effectively, you can switch between branches, create new branches, and discard changes as needed.
Merging Git branches with Git merge and Git rebase
Merging branches is an essential part of working with Git. It allows developers to combine changes made on different branches into a single branch, ensuring that all changes are integrated correctly. Git provides two main commands for merging branches: git merge and git rebase.
The git merge command combines changes from one branch into another. To merge a branch into the current branch, use git merge branch-name. For example, to merge changes from a branch called “feature-branch” into the current branch, use git merge feature-branch.
When you merge a branch, Git creates a new commit that combines the changes from the merged branch with the current branch. This creates a “merge commit” that records the fact that the branches were merged.
The git rebase command is an alternative to git merge. It allows you to move the changes made on one branch to another branch, effectively “replaying” the changes on top of the target branch. To rebase a branch onto another branch, use git rebase target-branch. For example, to rebase changes from a branch called “feature-branch” onto the current branch, use git rebase feature-branch.
When you rebase a branch, Git creates new commits that apply the changes from the rebased branch on top of the target branch. This creates a linear history, which can make it easier to understand the sequence of changes made to the codebase.
It’s important to note that both git merge and git rebase can create conflicts when changes made on different branches overlap. When this happens, Git will prompt you to resolve the conflicts manually. You can use a graphical tool, such as git mergetool, to help with the resolution of conflicts.
By using git merge and git rebase effectively, developers can integrate changes from different branches into a single branch, ensuring that all changes are applied correctly and that the history of the codebase remains clear and understandable.
Handling merge conflicts and resolving them with Git mergetool
When working with Git, merge conflicts can occur when two or more developers make changes to the same file or lines of code. This can happen when merging branches, pulling changes from a remote repository, or rebasing a branch.
When a merge conflict occurs, Git will mark the affected files with conflict markers, which indicate the conflicting sections of code. It’s up to the developer to resolve the conflicts by choosing which changes to keep and which changes to discard.
One way to resolve merge conflicts is to use a graphical mergetool, such as git mergetool. This tool allows developers to view the conflicting sections of code side-by-side and choose which changes to keep or discard.
To use git mergetool, follow these steps:
-
Ensure that you have a graphical mergetool installed on your system. Some popular mergetools for Git include
meld,kdiff3, andp4merge. -
When a merge conflict occurs, run
git mergetoolfrom the command line. This will launch the graphical mergetool and display the conflicting files. -
Use the graphical interface to review the conflicting sections of code and choose which changes to keep or discard. Typically, changes from the current branch are shown on the left, changes from the merged branch are shown on the right, and the merged result is shown in the center.
-
Save the changes and close the mergetool. This will automatically update the conflicting files in your Git repository.
Alternatively, you can also manually resolve merge conflicts by editing the conflicting files directly and removing the conflict markers. Once you’ve resolved the conflicts, you can commit the changes to complete the merge.
By using git mergetool or manually resolving merge conflicts, developers can ensure that changes are integrated correctly and that the codebase remains in a working state.
Best practices for using Git branches effectively and avoiding common pitfalls
Git branches can be a powerful tool for organizing work, collaborating with others, and keeping a codebase clean and stable. However, to use branches effectively, developers should follow some best practices and avoid common pitfalls. Here are some tips:
-
Keep your branches small and focused. Branches should be used for small, incremental changes that can be easily reviewed, merged, or discarded. Avoid creating branches that are too large or complex, as they can be difficult to manage and merge.
-
Use descriptive branch names. Branch names should be meaningful and descriptive, so that other developers can understand what changes the branch contains. Avoid using generic names like “feature” or “fix”, as they can be confusing and ambiguous.
-
Merge frequently. It’s a good practice to merge your changes frequently, especially if you’re working on a shared repository. This will help prevent conflicts and ensure that your changes are integrated smoothly with other developers’ changes.
-
Use pull requests for code review. Pull requests allow other developers to review and comment on your changes before they are merged into the main branch. This can help catch errors and improve the quality of the codebase.
-
Avoid long-lived branches. Long-lived branches can be difficult to maintain and merge, as they may accumulate conflicts and become out of date with the main branch. Try to avoid keeping branches around for too long, and consider merging or discarding them once they’ve served their purpose.
-
Use branch protection to prevent accidental changes. Branch protection can prevent accidental changes to important branches, such as the main branch or release branches. This can help ensure that the codebase remains stable and free from errors.
By following these best practices, developers can use Git branches effectively and avoid common pitfalls that can lead to errors, conflicts, and confusion.
Rewriting Git history
Rewriting Git history can be a useful technique for fixing mistakes, cleaning up a codebase, or preparing a repository for public release. However, it should be used with caution, as it can have unintended consequences and affect the work of other developers.
Here are some common ways to rewrite Git history:
-
Amending commits: The
git commit --amendcommand allows you to modify the most recent commit in your local branch. This is useful for fixing small mistakes or adding missing information to a commit message. -
Rebasing: Rebasing allows you to change the order or contents of commits in your branch. This can be useful for integrating changes from other branches or cleaning up a messy history. However, it can also create conflicts and should be used carefully.
-
Squashing commits: The
git rebase -icommand allows you to interactively squash multiple commits into a single commit. This is useful for cleaning up a messy history or preparing a branch for public release. However, it can also make it difficult to track changes and should be used with care. -
Filtering history: The
git filter-branchcommand allows you to rewrite history by filtering out or modifying commits based on certain criteria. This can be useful for removing sensitive data or cleaning up a repository before public release. However, it can also be complex and should be used with caution.
When rewriting Git history, it’s important to communicate any changes with other developers and ensure that the changes don’t cause conflicts or affect the work of others. It’s also a good practice to make a backup copy of the repository before making any significant changes.
Reordering and editing commits with Git rebase
Git rebase is a powerful tool that allows you to reorder and edit commits in your branch’s history. Here are some common use cases for Git rebase:
-
Squashing commits: If you have multiple small commits that are related to the same change, you can use Git rebase to squash them into a single commit. This can help keep your commit history clean and easy to understand.
-
Editing commit messages: If you notice a mistake or typo in a commit message, you can use Git rebase to edit the message. This can be done by running the command
git rebase -i HEAD~n, wherenis the number of commits you want to edit. In the interactive editor that opens, you can change the word “pick” to “reword” for the commit message you want to edit. -
Rearranging commits: If you have commits in your branch that are in the wrong order, you can use Git rebase to reorder them. This can be done by running the command
git rebase -i HEAD~n, wherenis the number of commits you want to reorder. In the interactive editor that opens, you can simply move the lines representing each commit to the desired order. -
Splitting commits: If you have a large commit that contains multiple unrelated changes, you can use Git rebase to split it into multiple smaller commits. This can be done by running the command
git rebase -i HEAD~n, wherenis the number of commits you want to split. In the interactive editor that opens, you can change the word “pick” to “edit” for the commit you want to split, and then use the commandgit reset HEAD^to unstage the changes. You can then usegit addto stage the changes you want to keep in the first commit, and then usegit committo create a new commit with the remaining changes.
It’s important to note that Git rebase rewrites history, so it should be used with care. If you are working on a shared branch or repository, it’s a good practice to communicate any changes with your team and make sure that your changes don’t conflict with the work of others.
Squashing and splitting commits with Git interactive rebase
Git interactive rebase is a powerful tool that allows you to edit, rearrange, squash, and split commits in your Git history. Here’s how to use interactive rebase to squash and split commits:
-
Squashing commits: To squash multiple commits into a single commit, you can use the
squashorfixupcommand in the interactive rebase editor. Run the commandgit rebase -i HEAD~nwherenis the number of commits you want to edit. In the interactive editor that opens, change the word “pick” to “squash” or “fixup” for the commits you want to squash. The difference betweensquashandfixupis thatsquashwill prompt you to edit the commit message, whilefixupwill use the original commit message. -
Splitting commits: To split a commit into multiple commits, you can use the
editcommand in the interactive rebase editor. Run the commandgit rebase -i HEAD~nwherenis the number of commits you want to edit. In the interactive editor that opens, change the word “pick” to “edit” for the commit you want to split. Git will then pause the rebase process at that commit, and you can make changes to the working directory as needed. Once you have made your changes, usegit addto stage the changes you want to keep in the first commit, and then usegit committo create a new commit with the remaining changes. You can then usegit rebase --continueto resume the interactive rebase process.
When using Git interactive rebase to modify commits, it’s important to keep in mind that this will change the commit history of your branch. If you are working with a team, it’s a good practice to communicate any changes with your team and make sure that your changes don’t conflict with the work of others.
Amending and updating commits with Git commit —amend and Git commit —fixup
Git commit —amend and Git commit —fixup are two powerful commands that allow you to amend and update commits in your Git history. Here’s how to use them:
-
Amending commits with Git commit —amend: If you need to make a small change to the most recent commit, you can use Git commit —amend. Simply make the desired changes to your files and stage them with
git add. Then, run the commandgit commit --amendto modify the most recent commit. Git will open your default text editor so that you can modify the commit message as well. When you save and close the editor, Git will create a new commit with the updated changes and message, and replace the old commit with the new one. -
Updating commits with Git commit —fixup: If you need to update a previous commit, you can use Git commit —fixup. This is useful if you have noticed a bug or made a mistake in a previous commit. Simply make the desired changes to your files and stage them with
git add. Then, run the commandgit commit --fixup <commit-id>where<commit-id>is the ID of the commit you want to update. Git will create a new commit with the updated changes, but with a special commit message that indicates that it is a “fixup” commit. You can then use Git rebase to apply the fixup commit to the original commit. For example, run the commandgit rebase -i --autosquash HEAD~nwherenis the number of commits you want to edit. Git will open the interactive rebase editor, where you can verify that the fixup commit is in the correct location. Save and close the editor, and Git will apply the fixup commit to the original commit, effectively updating it.
It’s important to keep in mind that Git commit —amend and Git commit —fixup will rewrite your Git history, so it’s important to use them with care. If you are working on a shared branch or repository, it’s a good practice to communicate any changes with your team and make sure that your changes don’t conflict with the work of others.
Rebasing and merging Git branches to maintain a clean and linear Git history
Maintaining a clean and linear Git history is important for the readability and manageability of your project. Rebasing and merging are two common techniques used to achieve this. Here’s how to use rebasing and merging to maintain a clean and linear Git history:
-
Rebasing branches: Rebasing involves applying the changes of one branch onto another branch. This creates a linear history, which can make it easier to understand the sequence of changes. To rebase a branch, run the command
git rebase <branch>where<branch>is the branch you want to apply the changes to. Git will apply the changes of your current branch on top of the target branch. If there are conflicts, you will need to resolve them manually. -
Merging branches: Merging combines the changes of two or more branches into a single branch. This creates a non-linear history, which can make it more difficult to understand the sequence of changes. To merge a branch, run the command
git merge <branch>where<branch>is the branch you want to merge into your current branch. Git will combine the changes from both branches and create a new commit that represents the merged state.
When deciding between rebasing and merging, consider the following:
- Rebasing can create a cleaner and more linear history, but it can also be more complex and result in more conflicts.
- Merging can create a more complex history, but it can also be simpler and result in fewer conflicts.
In general, it’s a good practice to use rebasing for your own local branches, and merging for shared branches with your team. This allows you to maintain a clean and linear history in your personal work, while also allowing your team to easily collaborate and understand the changes.
Chapter 3: Advanced Git Operations
Rebasing
Rebasing is a Git operation that allows you to apply the changes of one branch onto another branch. Rebasing creates a linear history, which can make it easier to understand the sequence of changes. Here’s how to use rebasing in Git:
-
Checkout the branch you want to rebase: Run the command
git checkout <branch>where<branch>is the branch you want to apply changes to. -
Start the rebase: Run the command
git rebase <target-branch>where<target-branch>is the branch you want to apply the changes from. -
Resolve conflicts: If there are conflicts between the changes of your current branch and the target branch, Git will pause the rebase and ask you to resolve the conflicts. To resolve conflicts, edit the files that have conflicts, stage the changes with
git add, and then continue the rebase withgit rebase --continue. -
Finish the rebase: Once all conflicts are resolved, Git will apply the changes of your current branch on top of the target branch. The rebase is complete.
It’s important to keep in mind that rebasing will rewrite the history of your branch, so it’s important to use it with care. If you have already pushed your branch to a remote repository and others have cloned it, it’s generally not recommended to rebase that branch, as it can create conflicts and confusion for others. In general, it’s a good practice to use rebasing for your own local branches, and merging for shared branches with your team.
Understanding Git rebase and how it differs from Git merge
Git rebase and Git merge are two different techniques to combine changes from one branch to another. Here’s how Git rebase and Git merge differ:
Git Merge:
- Git merge combines the changes of two or more branches into a single branch.
- When you merge a branch, Git creates a new commit that represents the merged state, with two parent commits (the latest commit of each branch).
- This creates a non-linear history, which can make it more difficult to understand the sequence of changes.
- Merging is best used when you want to combine changes from multiple branches that have independent commits and you want to preserve their individual histories.
Git Rebase:
- Git rebase applies the changes of one branch onto another branch.
- When you rebase a branch, Git applies the changes of your current branch on top of the target branch, effectively replaying your branch’s changes on top of the target branch’s changes.
- This creates a linear history, which can make it easier to understand the sequence of changes.
- Rebasing is best used when you want to incorporate changes from one branch into another branch, and you want to keep a clean and linear history.
In summary, the main difference between Git merge and Git rebase is how they handle the commit history. Git merge creates a new commit that represents the merged state, while Git rebase replays the changes of one branch on top of another branch, effectively creating a new branch history. The choice between Git merge and Git rebase will depend on the specific use case and the goals of the project.
Rebasing to integrate changes from one branch to another
Rebasing is a Git operation that can be used to integrate changes from one branch to another by applying the changes of one branch onto another. Here’s how to use rebasing to integrate changes from one branch to another:
-
Checkout the branch you want to apply changes to: Run the command
git checkout <target-branch>where<target-branch>is the branch you want to apply the changes to. -
Start the rebase: Run the command
git rebase <source-branch>where<source-branch>is the branch that contains the changes you want to apply. -
Resolve conflicts: If there are conflicts between the changes of your current branch and the source branch, Git will pause the rebase and ask you to resolve the conflicts. To resolve conflicts, edit the files that have conflicts, stage the changes with
git add, and then continue the rebase withgit rebase --continue. -
Finish the rebase: Once all conflicts are resolved, Git will apply the changes of your source branch on top of the target branch. The rebase is complete.
After the rebase is complete, the target branch will contain the changes of the source branch on top of its own changes. This can create a clean and linear history, which can make it easier to understand the sequence of changes.
It’s important to note that rebasing will rewrite the history of your branch, so it’s important to use it with care. If you have already pushed your branch to a remote repository and others have cloned it, it’s generally not recommended to rebase that branch, as it can create conflicts and confusion for others. In general, it’s a good practice to use rebasing for your own local branches, and merging for shared branches with your team.
Interactive rebasing for more complex operations such as squashing and editing commits
Git’s interactive rebase is a powerful tool that allows you to make more complex changes to your Git history, such as squashing and editing commits. Here’s how to use interactive rebase for these operations:
-
Start the interactive rebase: Run the command
git rebase -i <commit>where<commit>is the commit you want to start the rebase from. This will open an editor with a list of commits starting from the given commit. -
Choose the commits to edit, squash or re-order: In the editor, you can choose which commits to edit, squash, re-order or skip. To edit a commit, change the command from “pick” to “edit”. To squash commits, change the command from “pick” to “squash” or “fixup”. To re-order commits, simply re-order them in the list.
-
Edit the commits: If you chose to edit a commit, Git will stop the rebase at that commit and allow you to make changes. After you make the changes, stage them with
git addand rungit rebase --continueto proceed with the rebase. -
Finish the rebase: After you’ve made all the desired changes, save and exit the editor. Git will apply your changes and complete the rebase.
Interactive rebasing can be a very powerful tool, but it’s important to use it with care. Rewriting history can create confusion and conflicts for other users, so it’s generally not recommended to rebase commits that have been pushed to a shared repository. In general, it’s best to use interactive rebase for your own local branches, and use other techniques such as merging for shared branches with your team.
Handling conflicts during rebasing
Rebasing can sometimes result in conflicts, especially when you are trying to apply changes from one branch onto another. Here’s how to handle conflicts during rebasing:
-
Resolve conflicts: When Git encounters conflicts during a rebase, it will pause the rebase and inform you about the conflict. The files with conflicts will have conflict markers (
<<<<<<<,=======, and>>>>>>>) indicating where the conflicts occurred. Edit the files to resolve the conflicts, keeping only the changes that you want to keep. Save the file. -
Add the resolved files: Once the conflicts are resolved, stage the changes using
git addto mark the resolved files as resolved. -
Continue the rebase: Run the command
git rebase --continueto resume the rebase process. Git will apply the changes from the source branch onto the target branch. -
Repeat if necessary: If there are more conflicts, repeat the above steps until all conflicts are resolved.
It’s important to note that rebasing can rewrite the history of your branch, so it’s important to use it with care. If you have already pushed your branch to a remote repository and others have cloned it, it’s generally not recommended to rebase that branch, as it can create conflicts and confusion for others. In general, it’s a good practice to use rebasing for your own local branches, and merging for shared branches with your team.
Cherry-picking
Cherry-picking is a Git command that allows you to apply a specific commit from one branch onto another branch. It’s useful when you want to bring in a specific change from one branch to another, without having to merge the entire branch. Here’s how to use cherry-pick:
-
Identify the commit: First, identify the commit that you want to cherry-pick. You can use
git logorgitkto view the commit history and find the commit you want to cherry-pick. Take note of the commit hash. -
Switch to the target branch: Switch to the branch where you want to apply the changes.
-
Cherry-pick the commit: Run the command
git cherry-pick <commit-hash>, where<commit-hash>is the hash of the commit you want to cherry-pick. Git will apply the changes from that commit onto the current branch. -
Resolve conflicts: If there are conflicts during the cherry-pick, resolve them as you would during a merge or rebase.
-
Commit the changes: After the cherry-pick is complete and conflicts are resolved, commit the changes with
git commit.
It’s important to note that cherry-picking can introduce conflicts if the changes in the cherry-picked commit are dependent on other changes in the source branch. In general, cherry-picking should be used sparingly and for small changes that are easy to isolate. For larger changes, it’s usually better to use other methods such as merging or rebasing.
Understanding Git cherry-pick and when to use it
Git cherry-pick is a command that allows you to apply a specific commit from one branch to another. You may want to use cherry-pick in situations where you want to apply a specific change or set of changes from one branch onto another, without having to merge the entire branch.
Here are some common use cases for Git cherry-pick:
-
Applying a bug fix: Suppose you have a bug fix in one branch that you want to apply to another branch. Instead of merging the entire branch, you can cherry-pick the specific commit that contains the bug fix.
-
Applying a feature: If you have a new feature in one branch that you want to apply to another branch, you can cherry-pick the commit that contains the changes for that feature.
-
Reverting a commit: If you need to revert a commit from a branch, you can cherry-pick the commit that reverts the changes from the original commit.
-
Backporting changes: If you need to apply a change to an older branch that does not have the change, you can cherry-pick the commit that contains the change.
It’s important to note that cherry-picking can introduce conflicts if the changes in the cherry-picked commit are dependent on other changes in the source branch. It’s also important to use cherry-pick sparingly and only for small changes that are easy to isolate. For larger changes or complex changes, it’s generally better to use other methods such as merging or rebasing.
In summary, Git cherry-pick can be a useful tool in certain situations, but it should be used with caution and only for specific, isolated changes.
Picking individual commits from one branch and applying them to another
Picking individual commits from one branch and applying them to another can be done using Git cherry-pick command. Here are the steps:
-
Identify the commit(s) to be cherry-picked: First, identify the commit(s) that you want to cherry-pick. You can use
git logorgitkto view the commit history and find the commit you want to cherry-pick. Take note of the commit hash. -
Switch to the target branch: Switch to the branch where you want to apply the changes.
-
Cherry-pick the commit(s): Run the command
git cherry-pick <commit-hash>, where<commit-hash>is the hash of the commit you want to cherry-pick. If you want to cherry-pick multiple commits, you can list their hashes separated by a space. -
Resolve conflicts: If there are conflicts during the cherry-pick, resolve them as you would during a merge or rebase.
-
Commit the changes: After the cherry-pick is complete and conflicts are resolved, commit the changes with
git commit.
It’s important to note that cherry-picking individual commits can lead to inconsistencies in the commit history, especially if the cherry-picked commit(s) are dependent on other changes in the source branch. Additionally, cherry-picking should be used sparingly and only for small changes that are easy to isolate. For larger or more complex changes, it’s generally better to use other methods such as merging or rebasing.
Handling conflicts during cherry-picking
When cherry-picking individual commits from one branch to another, it’s possible to encounter conflicts if the changes in the cherry-picked commit are dependent on other changes in the source branch. Here are the steps to handle conflicts during cherry-picking:
-
Identify the conflicting files: When Git encounters a conflict during cherry-picking, it will mark the conflicting files in the working directory with conflict markers. Use
git statusto identify the files that have conflicts. -
Resolve the conflicts: Open the conflicting files in a text editor and resolve the conflicts manually. The conflict markers in the file indicate the conflicting changes from both the source and target branches. Edit the file to keep the changes you want and remove the conflict markers. Save the file after resolving the conflict.
-
Add the changes: After resolving the conflicts, add the changes to the staging area using
git add. -
Continue the cherry-pick: Use the command
git cherry-pick --continueto continue the cherry-pick process after resolving the conflicts. -
Repeat as needed: If there are multiple conflicting files, repeat steps 2-4 for each file until all conflicts are resolved.
-
Commit the changes: After resolving all conflicts, commit the changes with
git commit.
It’s important to review the changes carefully after resolving conflicts to ensure that the cherry-picked commit(s) did not introduce any unintended changes or regressions.
Stashing
Git stash is a command that allows you to save changes that are not yet ready to be committed and revert to a clean working directory. This can be useful if you need to switch to a different branch to work on another feature or fix an urgent issue, but don’t want to commit your current changes yet. Here are the basic steps to use Git stash:
-
Stash changes: Run the command
git stashto stash your current changes. This will remove the changes from the working directory and store them in the Git stash. -
Switch branches or perform other actions: After stashing your changes, you can switch to a different branch, perform other actions, or work on other features.
-
Unstash changes: To unstash your changes, run the command
git stash apply. This will apply the stashed changes to the working directory. If you have multiple stashes, you can specify which stash to apply by providing the stash reference as an argument (e.g.,git stash apply stash@{2}). -
Discard stash: If you no longer need the stashed changes, you can discard them with the command
git stash drop. If you want to discard all stashed changes, you can run the commandgit stash clear.
Git stash can also be used to temporarily store changes while resolving merge conflicts or to apply changes from one branch to another using the git stash branch command. However, it’s important to use Git stash carefully and avoid stashing changes for extended periods of time, as this can lead to confusion and merge conflicts later on.
Understanding Git stash and when to use it
Git stash is a powerful command that allows you to temporarily store changes that are not yet ready to be committed. You can think of Git stash as a stack of saved changes. You can stash your changes at any time, switch to a different branch or commit, and then apply the stashed changes when you’re ready. Here are some scenarios where Git stash can be helpful:
-
Switching branches: If you have uncommitted changes in your working directory and need to switch to a different branch to work on a different feature or fix an urgent issue, you can use Git stash to temporarily store your changes and switch to the new branch.
-
Pulling changes from upstream: If you have local changes that conflict with changes from upstream, you can use Git stash to temporarily store your changes, pull changes from upstream, resolve any conflicts, and then apply your stashed changes.
-
Resolving merge conflicts: If you encounter merge conflicts during a merge or rebase operation, you can use Git stash to temporarily store your changes, resolve the conflicts, and then apply your stashed changes.
-
Experimenting with changes: If you want to experiment with changes but don’t want to commit them yet, you can use Git stash to temporarily store your changes, experiment with different changes, and then apply your stashed changes.
-
Saving work-in-progress: If you’re working on a feature that’s not yet complete and you need to switch to a different task, you can use Git stash to temporarily store your changes and return to them later.
It’s important to use Git stash carefully and avoid stashing changes for extended periods of time. Stashing changes for too long can lead to confusion and merge conflicts later on. Always make sure to apply your stashed changes as soon as possible and review them carefully before committing.
Stashing changes temporarily to switch branches or work on other tasks
Sure, here’s an example of how to use Git stash to temporarily store changes while you switch branches or work on other tasks:
-
Make changes to your working directory:
$ vim myfile.txt $ git status On branch main Changes not staged for commit: modified: myfile.txt -
Stash your changes:
$ git stash Saved working directory and index state WIP on main: abcd1234 Fix bug #123This command saves your changes to a stack of stashes and reverts your working directory to the last committed state.
-
Switch to a different branch:
git checkout feature-branch -
Do some work on the feature branch:
$ vim anotherfile.txt $ git status On branch feature-branch Changes not staged for commit: modified: anotherfile.txt -
Switch back to the original branch and apply the stash:
git checkout main git stash applyThis command applies the top stash in the stack (the most recently stashed changes) to your working directory.
-
Review the changes and commit:
$ git status On branch main Changes not staged for commit: modified: myfile.txt $ git add myfile.txt $ git commit -m "Fix bug #123"
Remember that stashing changes is a temporary solution and should be used carefully. Always make sure to apply your stashed changes as soon as possible and review them carefully before committing.
Retrieving stashed changes and resolving conflicts
Sure, here’s an example of how to retrieve stashed changes and resolve conflicts:
-
Create some changes in your working directory:
echo "Hello world" > myfile.txt git add myfile.txt git commit -m "Add greeting" -
Stash your changes:
$ git stash Saved working directory and index state WIP on main: abcd1234 Add greeting -
Make some conflicting changes in your working directory:
echo "Goodbye world" > myfile.txt -
Try to apply the stash:
$ git stash apply Auto-merging myfile.txt CONFLICT (content): Merge conflict in myfile.txtThis command applies the top stash in the stack, but a conflict occurs because the changes you stashed conflict with the changes you made in your working directory.
-
Resolve the conflict:
git mergetoolThis command opens your preferred merge tool to help you resolve the conflict. Follow the prompts to choose which changes to keep.
-
Add and commit the resolved changes:
git add myfile.txt git commitThis command creates a new commit with the changes from the stash and the changes you made in your working directory.
Remember that stashing changes is a temporary solution and should be used carefully. Always make sure to apply your stashed changes as soon as possible and review them carefully before committing. Additionally, be aware that stashing only saves changes to tracked files, so any new untracked files you created will not be saved.
Best practices for using Git stash effectively and avoiding data loss
Here are some best practices for using Git stash effectively and avoiding data loss:
- Only use Git stash for temporary storage of changes that are not ready to be committed or pushed. Stashing should not be used as a substitute for proper branching and version control practices.
- Use descriptive stash messages to make it easier to remember what changes are in each stash. You can add a message to a stash with the
git stash save "message"command. - Always review your stashed changes before applying them to make sure you don’t accidentally lose any data. You can list your stashes with
git stash listand view the changes in a stash withgit stash show. - Always apply your stashed changes as soon as possible to avoid conflicts with other changes that may have been made in the meantime. You can apply the top stash with
git stash applyor apply a specific stash withgit stash apply stash@{n}. - If you want to temporarily switch to another branch while you have stashed changes, it is generally safer to create a new branch instead of switching branches directly. This will allow you to switch back to your original branch and apply your stashed changes without losing any data.
- Be aware that stashing only saves changes to tracked files, so any new untracked files you created will not be saved. You can use the
--include-untrackedor--alloptions with thegit stashcommand to include untracked files in the stash, but use these options carefully to avoid accidentally stashing sensitive or irrelevant data. - If you want to permanently discard a stash, use the
git stash dropcommand. Be careful when using this command, as it will permanently delete the stash and you will not be able to recover it. - If you want to keep a stash around but remove it from the stash stack, use the
git stash branch <branchname> <stash>command to create a new branch based on the changes in the specified stash. This will apply the changes in the stash to the new branch and remove the stash from the stash stack.
By following these best practices, you can use Git stash effectively and avoid losing any important data.
Aliases and custom Git commands
Aliases and custom Git commands can be very useful for simplifying common or repetitive Git commands, as well as for creating shortcuts or custom workflows tailored to your specific needs. Here are some tips for creating and using Git aliases and custom commands:
-
Creating aliases: Aliases are simple shortcuts for longer Git commands. You can create an alias with the
git config --global alias.<alias-name> <git-command>command. For example, to create an alias for thegit statuscommand, you can rungit config --global alias.st status. You can then use the new alias by runninggit stinstead ofgit status. -
Using shell commands in aliases: You can also include shell commands in Git aliases. For example, to create an alias that shows the current Git branch and the status of the repository, you can run
git config --global alias.bs 'echo "Current branch: $(git branch --show-current)"; echo ""; git status'. You can then rungit bsto see the current branch and repository status. -
Creating custom Git commands: Custom Git commands are more complex than aliases and can include multiple Git commands or shell commands. To create a custom Git command, you can create a script file with the desired commands and save it in a location in your system’s PATH. For example, you can create a script called
git-publishthat pushes the current branch to a remote repository and opens a pull request in GitHub. You can then save the script in a directory in your system’s PATH, such as/usr/local/bin, and make it executable withchmod +x git-publish. You can then run thegit publishcommand from any Git repository to push and open a pull request. -
Sharing aliases and custom commands: If you want to share your aliases or custom commands with others, you can store them in a Git repository or a dotfiles repository on GitHub or GitLab. You can also create a script that installs your aliases and custom commands automatically, which can be useful when setting up a new development environment.
By using aliases and custom Git commands, you can simplify your Git workflow and save time on common or repetitive tasks. Just be careful not to create too many aliases or custom commands, as this can make your Git configuration difficult to maintain and remember.
Creating and using Git aliases for frequently used commands and options
Creating Git aliases is a great way to save time and improve productivity by creating shorter versions of commonly used Git commands and options. Here are some tips for creating and using Git aliases effectively:
-
Creating Git aliases: You can create Git aliases by using the
git configcommand with thealiasoption. For example, to create an alias for thegit statuscommand, you can use the following command:git config --global alias.st status. This will create a new alias calledstthat you can use instead of typinggit status. -
Using Git aliases: To use a Git alias, simply type the alias instead of the full Git command. For example, if you created an alias called
cofor thegit checkoutcommand, you can usegit coinstead ofgit checkout. -
Creating aliases for frequently used options: You can also create aliases for frequently used options. For example, if you frequently use the
--alloption with thegit fetchcommand, you can create an alias calledfetchallthat includes the--alloption. To create this alias, you can use the following command:git config --global alias.fetchall "fetch --all". -
Using aliases for commonly used workflows: You can also create aliases for commonly used workflows. For example, if you frequently merge the
developbranch into thefeaturebranch, you can create an alias calledmergedevthat does this for you. To create this alias, you can use the following command:git config --global alias.mergedev "merge develop feature". -
Customizing aliases: You can customize your Git aliases to suit your needs. For example, you can include shell commands in your aliases or create aliases that take arguments. To include shell commands in your aliases, enclose the commands in backticks. For example, to create an alias that shows the top five branches by commit count, you can use the following command:
git config --global alias.top5branches "for-each-ref --sort=-committerdate --count=5 --format='%(refname:short)' refs/heads/ | xargs -L1 -I {} sh -c 'echo {} ; git log --format=\"%Cgreen%h%Creset %s %Cblue(%an)%Creset\" --no-merges {}' | column -t". This alias uses thefor-each-refcommand to list the top five branches by commit count, and then runs agit logcommand on each branch to show the commit hash, commit message, and author.
By creating and using Git aliases, you can save time and improve your productivity by reducing the amount of typing and remembering required for frequently used Git commands and options. Just be sure to use aliases judiciously and avoid creating aliases that are too complex or difficult to remember.
Customizing Git behavior with Git configuration and hooks
Git configuration allows you to customize Git’s behavior according to your needs. Git configuration can be done at different levels: system-wide, user-specific, and repository-specific. Git configuration can be done using the git config command.
Git hooks are scripts that can be executed before or after certain Git actions, such as committing or pushing changes. Git hooks can be used to enforce certain standards, automate tasks, or integrate with other tools.
Here are some examples of how to use Git configuration and hooks:
- Set user name and email:
git config --global user.name "Your Name"
git config --global user.email "your.email@example.com"- Set default branch name:
git config --global init.defaultBranch main- Set default merge strategy:
git config --global merge.ff false- Create a custom Git command:
git config --global alias.st statusThis creates an alias st for the status command. Now you can use git st instead of git status.
- Create a pre-commit hook:
#!/bin/bash
# Check for trailing whitespace
if git diff --check --cached | grep "^[+-][[:space:]]*$" --quiet; then
echo "Commit rejected: trailing whitespace found."
exit 1
fiSave this script as .git/hooks/pre-commit in your repository. Now, whenever you try to commit changes, Git will execute this script first and reject the commit if it finds any trailing whitespace.
Note that Git configuration and hooks can be very powerful tools, but they can also cause problems if not used correctly. Always test your configurations and hooks before using them in production.
Writing and sharing custom Git commands with Git plugins and scripts
In addition to creating Git aliases, you can also write custom Git commands using Git plugins and scripts. This can be useful if you need to perform complex operations or automate certain tasks.
Git plugins are extensions to Git that provide additional functionality. They can be written in any programming language and can be used to perform a wide range of tasks. Git plugins can be installed using package managers such as Homebrew or npm, or they can be installed manually.
Scripts are simple programs written in Bash, Python, or another scripting language. They can be used to automate repetitive tasks or perform complex operations. Scripts can be executed using Git aliases or as standalone programs.
Here are some examples of how to write and share custom Git commands using Git plugins and scripts:
- Writing a Git plugin:
#!/usr/bin/env node
const git = require('isomorphic-git')
const http = require('isomorphic-git/http/node')
module.exports = async function clone(repo, dir) {
await git.clone({
fs,
http,
dir,
url: repo,
corsProxy: 'https://cors.isomorphic-git.org',
})
console.log(`Cloned ${repo} to ${dir}`)
}This plugin uses the isomorphic-git library to clone a Git repository. The clone function can be invoked from the command line using the git clone command.
- Writing a Git script:
#!/bin/bash
set -e
remote=$(git remote get-url origin)
slug=$(echo "$remote" | cut -d':' -f2 | sed 's/.git$//')
issues_url="https://github.com/$slug/issues/new"
open "$issues_url"This script opens a new issue on GitHub for the current repository. It can be invoked using a Git alias or as a standalone program.
- Sharing Git plugins and scripts: Git plugins and scripts can be shared on public repositories such as GitHub or GitLab. They can also be distributed as packages using package managers such as npm or PyPI.
To install a Git plugin, use a package manager such as npm:
npm install -g git-cloneThis installs the git-clone plugin globally, making it available as a Git command.
To install a Git script, copy it to a directory in your PATH, such as /usr/local/bin:
sudo cp my-script.sh /usr/local/bin
sudo chmod +x /usr/local/bin/my-script.shThis installs the my-script command, making it available as a Git command.
Note that when writing and sharing custom Git commands, it is important to follow best practices for coding and documentation. This includes writing clear and concise code, providing documentation and examples, and testing your code thoroughly.
Best practices for managing Git configuration and customizations across different environments and systems
When it comes to managing Git configuration and customizations across different environments and systems, there are a few best practices that can help:
-
Use a version-controlled dotfiles repository: Keeping your Git configuration and customizations in a version-controlled repository, such as a dotfiles repository, can make it easy to manage and sync them across different systems. You can use tools like dotbot or yadm to automate the process of setting up your dotfiles on new systems.
-
Use conditional configurations: Git allows you to set up different configurations for different environments or systems using conditional configurations. For example, you can set up different email addresses or signing keys for your work and personal Git repositories. This can help avoid mistakes and prevent data leakage.
-
Use Git hooks to automate tasks: Git hooks can be used to automate repetitive or error-prone tasks, such as running tests or linting code before committing changes. You can use pre-commit hooks to enforce code quality standards or pre-push hooks to prevent pushing code that doesn’t meet certain criteria.
-
Use a centralized Git server: If you work in a team, using a centralized Git server can help ensure that everyone has access to the same Git configuration and customizations. This can also help prevent conflicts and ensure that changes are properly reviewed and approved.
-
Document your customizations: Finally, it’s important to document any customizations you make to Git configuration or behavior, especially if you’re sharing them with others. This can help ensure that everyone is on the same page and can make it easier to troubleshoot any issues that arise.
Git submodules and subtrees
Git submodules and subtrees are two ways of managing dependencies in a Git repository. They allow you to include code from other repositories within your own repository, and keep it up to date with changes in those repositories.
Git Submodules
A Git submodule is a separate Git repository that is included as a subdirectory within another Git repository. When you add a submodule to a repository, you create a link to the other repository that can be used to track changes and update the submodule to the latest version. This allows you to include external libraries, frameworks, or other code in your own repository.
To add a submodule to a Git repository, you use the git submodule add command followed by the URL of the repository you want to include. This creates a .gitmodules file in the root directory of your repository, which contains information about the submodule.
Git Subtrees
A Git subtree is similar to a submodule, but instead of including a separate repository as a subdirectory, it allows you to include a specific directory or subdirectory from another repository directly within your own repository. This can be useful if you only need a small portion of another repository, or if you want to keep the history of the external code within your own repository.
To add a subtree to a Git repository, you use the git subtree add command followed by the URL of the repository and the directory or subdirectory you want to include. This creates a new commit in your repository that includes the contents of the external directory.
Best Practices
When using Git submodules or subtrees, there are a few best practices that can help:
- Be careful when updating submodules or subtrees, as changes in the external repository can affect your own repository.
- Use a consistent naming convention for submodules or subtrees to make it clear where external code is coming from.
- Document any external dependencies and how to update them in your repository’s README file.
- Consider using automation tools, such as Git subrepo, to simplify the management of submodules or subtrees.
Understanding Git submodules and subtrees
Git submodules and subtrees are two different ways to incorporate a repository into another repository.
Git submodules are a way to include one repository as a subdirectory of another repository. Submodules allow you to keep the two repositories separate, while still being able to use and update the contents of the submodule. When you add a submodule to a repository, you include a reference to the submodule’s commit hash, so you can ensure that you always have a consistent view of the submodule’s contents.
Git subtrees are another way to incorporate one repository into another repository. With Git subtrees, you merge the contents of one repository into a subdirectory of another repository. The merged-in repository becomes a part of the parent repository’s history. Git subtrees are useful when you want to keep the contents of the merged-in repository in sync with the parent repository, and you don’t need to maintain a separate copy of the merged-in repository.
In summary, Git submodules allow you to incorporate a separate repository as a subdirectory within your repository, while Git subtrees allow you to merge the contents of a separate repository into a subdirectory of your repository.
Adding and updating submodules and subtrees in a Git repository
To add a submodule to a Git repository, you can use the git submodule add command. For example, if you wanted to add a submodule for a repository named “my-submodule” to your current repository:
git submodule add https://github.com/user/my-submodule.gitThis will clone the submodule repository into a new subdirectory within your repository, and add a reference to the submodule’s commit hash in your repository’s .gitmodules file.
To update the contents of a submodule, you can use the git submodule update command. This will update the submodule to the latest commit of the branch that is referenced in the .gitmodules file. For example:
git submodule update --remoteThis will update the submodule to the latest commit of the remote branch.
To add a subtree to a Git repository, you can use the git subtree add command. For example, if you wanted to add a subtree for a repository named “my-subtree” to your current repository:
git subtree add --prefix=subdirectory https://github.com/user/my-subtree.git master --squashThis will merge the contents of the “my-subtree” repository into a new subdirectory called “subdirectory” within your repository, and squash the subtree’s commits into a single commit in your repository.
To update the contents of a subtree, you can use the git subtree pull command. For example:
git subtree pull --prefix=subdirectory https://github.com/user/my-subtree.git master --squashThis will pull the latest changes from the “my-subtree” repository into the “subdirectory” subtree, and squash the subtree’s commits into a single commit in your repository.
In summary, adding and updating submodules and subtrees in a Git repository involves using specific commands such as git submodule add, git submodule update, git subtree add, and git subtree pull. These commands allow you to add and update the contents of separate repositories in your main repository, either as submodules or subtrees, depending on your needs.
Working with submodules and subtrees from different repositories
When working with submodules or subtrees from different repositories, the basic workflow is similar to working with them within a single repository. However, there are a few differences to keep in mind.
To add a submodule or subtree from a different repository, you will need to use the URL of the remote repository instead of the path to the local repository. For example, to add a submodule from a remote repository, you can use the following command:
git submodule add <remote repository URL> <path to submodule directory>Similarly, to add a subtree from a remote repository, you can use the following command:
git subtree add --prefix=<path to subtree directory> <remote repository URL> <branch>Note that you will need to have the necessary permissions to access the remote repository.
When you clone a repository that contains submodules, the submodules will be initialized but not updated by default. To update the submodules to their latest version, you can use the following command:
git submodule update --init --recursiveFor subtrees, you can update them using the same command you would use for updating a subtree within a single repository:
git subtree pull --prefix=<path to subtree directory> <remote repository URL> <branch>Again, you will need to have the necessary permissions to access the remote repository.
It’s also worth noting that when you push changes to a repository that contains submodules or subtrees, the changes to the submodules or subtrees will not be pushed automatically. Instead, you will need to push the changes to the submodules or subtrees separately. To do this, you can navigate to the directory of the submodule or subtree and push the changes from there using standard Git commands.
Overall, working with submodules and subtrees from different repositories requires some extra attention to ensure that the necessary permissions are in place and that changes are pushed and pulled correctly. However, the basic workflow is similar to working with them within a single repository.
Best practices for using Git submodules and subtrees effectively and avoiding common issues
Git submodules and subtrees can be powerful tools for managing complex project dependencies, but they can also introduce some challenges if not used correctly. Here are some best practices to follow when working with Git submodules and subtrees:
-
Plan ahead: Before adding a submodule or subtree, think carefully about the project’s future needs and whether the added complexity is justified. If in doubt, start with a simpler solution and refactor later if necessary.
-
Keep submodules and subtrees up to date: It’s important to regularly update submodules and subtrees to ensure that your project is using the latest versions of its dependencies. Use Git commands like
git submodule updateandgit subtree pullto keep your submodules and subtrees up to date. -
Document your submodules and subtrees: Make sure to document which submodules and subtrees your project depends on and how to set them up. This will make it easier for other developers to get up and running with your project.
-
Be careful with submodule and subtree removal: Removing a submodule or subtree can be tricky and may result in data loss if not done carefully. Make sure to read the Git documentation on submodule and subtree removal and test your changes thoroughly before committing.
-
Use Git hooks to automate submodule and subtree updates: Git hooks can be used to automatically update submodules and subtrees when changes are made to the parent repository. This can help to avoid errors and ensure that dependencies are always up to date.
By following these best practices, you can ensure that your Git submodules and subtrees are managed effectively and minimize the risk of issues arising in your project.
Git workflows for large projects
Git workflows for large projects typically involve multiple developers working on different features or components of the project simultaneously. Here are some commonly used Git workflows for large projects:
-
Centralized Workflow: In this workflow, there is a central repository where all the code is stored. Developers clone the repository, make changes, and push their changes back to the central repository. This workflow is simple and easy to manage, but it can be slow when multiple developers are working on the same codebase simultaneously.
-
Feature Branch Workflow: In this workflow, developers work on features or components in separate branches. They make changes, commit them to their local branch, and push the branch to the central repository. When the feature is complete, it is merged into the main branch. This workflow is more flexible than the centralized workflow, but it can become complex when there are many developers working on different features.
-
Gitflow Workflow: This workflow is an extension of the feature branch workflow. It adds two long-lived branches: the develop branch, where ongoing development takes place, and the master branch, which stores the stable code. Feature branches are created from the develop branch, and when they are complete, they are merged back into the develop branch. When a stable release is ready, the develop branch is merged into the master branch. This workflow is useful for managing multiple releases of a project simultaneously.
-
Forking Workflow: In this workflow, each developer creates a fork of the central repository. They make changes in their fork, commit them, and create pull requests to merge their changes into the central repository. This workflow is commonly used for open-source projects, as it allows developers to contribute without needing write access to the central repository.
These are just a few of the many Git workflows available for large projects. The best workflow depends on the specific needs of the project and the development team.
Using Git in a large project with multiple contributors and complex dependencies
When working on a large project with multiple contributors and complex dependencies, it’s important to establish a clear Git workflow to ensure that the project stays organized and everyone is on the same page. Here are some steps you can take to create an effective Git workflow:
-
Define the repository structure: Determine how the repository will be organized, including how many branches will be used, what the naming convention for branches will be, and how code will be reviewed and merged.
-
Set up branching strategy: Determine how branches will be used to support the development process. For example, you may use a “develop” branch for integrating features and bug fixes, and a “master” branch for stable releases.
-
Establish guidelines for committing code: Set guidelines for how often code should be committed, how descriptive commit messages should be, and how much code should be included in each commit.
-
Implement code review process: Establish a process for reviewing code changes, including who is responsible for reviewing changes, how changes will be reviewed, and what criteria will be used to approve changes.
-
Use Git hooks: Git hooks can be used to enforce rules and automate tasks. For example, you can use hooks to run automated tests before a commit is allowed or to automatically format code to conform to specific standards.
-
Use Git submodules or subtrees: If your project has complex dependencies, consider using Git submodules or subtrees to manage them.
Strategies for managing Git branches, merges, and releases in a large project
Managing Git branches, merges, and releases in a large project can be challenging. Here are some strategies that can help:
-
Adopt a branching strategy: A branching strategy defines how code changes are organized in Git branches. Some popular branching strategies for large projects include GitFlow, GitHub Flow, and Trunk-based development. It’s important to choose a branching strategy that suits your team’s needs and workflow.
-
Use pull requests for code review: Pull requests provide a way to review code changes before they are merged into a branch. This is especially important in a large project with multiple contributors. Pull requests also help ensure that changes are tested and meet the project’s standards before they are merged.
-
Use continuous integration and deployment: Continuous integration (CI) and continuous deployment (CD) help automate the testing and deployment of code changes. This can help catch bugs and errors early on and ensure that changes are deployed quickly and consistently.
-
Use tags and releases for versioning: Tags and releases provide a way to mark specific points in the project’s history and track changes over time. This can be especially useful in a large project with multiple releases and versions.
-
Use Git hooks for automation: Git hooks are scripts that run automatically when certain Git events occur. For example, you can use pre-commit hooks to check code formatting or pre-push hooks to run tests before pushing changes to a remote branch. Git hooks can help automate repetitive tasks and ensure that code changes meet the project’s standards.
-
Communicate and document changes: Communication is key in a large project with multiple contributors. It’s important to document changes and communicate them clearly to the team. This can help avoid confusion and ensure that everyone is on the same page.
These are just some strategies that can help manage Git branches, merges, and releases in a large project. The key is to choose a workflow that works for your team and to continually evaluate and adjust your processes as needed.
Best practices for communication, collaboration, and conflict resolution in a large Git project
When working on a large Git project with multiple contributors, effective communication and collaboration are essential for ensuring a smooth workflow and avoiding conflicts. Here are some best practices for communication, collaboration, and conflict resolution in a large Git project:
-
Establish clear guidelines: Establish clear guidelines and best practices for how to use Git in the project. This can include things like branch naming conventions, merge policies, and code review processes.
-
Use pull requests for code review: Use pull requests as a way to facilitate code review and collaboration between team members. This allows other team members to review and provide feedback on code changes before they are merged into the main branch.
-
Use issue trackers: Use issue trackers to track bugs, feature requests, and other tasks. This can help to ensure that everyone is on the same page and that tasks are not duplicated or missed.
-
Communicate frequently: Communication is key when working on a large Git project. Use tools like chat apps and video conferencing to stay in touch with other team members and to discuss any issues or concerns.
-
Resolve conflicts quickly: Conflicts are bound to arise when working on a large Git project, but it’s important to resolve them quickly to avoid delays and maintain a smooth workflow. Use tools like Git mergetool to help resolve conflicts and communicate with team members to ensure that everyone is on the same page.
-
Document everything: Document everything, including processes, workflows, and best practices. This can help to ensure that everyone is on the same page and can reference the documentation if they have any questions or concerns.
By following these best practices, you can help to ensure that your team is working together effectively and efficiently, and that your Git project is a success.
Chapter 4: Collaborating with Git
Setting up a remote repository
To set up a remote repository, you can follow these steps:
-
Choose a remote repository hosting service, such as GitHub, GitLab, or Bitbucket.
-
Create an account on the hosting service and sign in.
-
Create a new repository on the hosting service by clicking the “New Repository” button or similar.
-
Choose a name for your repository and specify whether it should be public or private.
-
Copy the remote repository URL provided by the hosting service. This URL will be used to link your local repository to the remote repository.
-
In your local repository, use the
git remote addcommand to add the remote repository URL as a new remote. For example, if your remote repository is on GitHub, you would use the following command:git remote add origin https://github.com/your-username/your-repo.git. This will add the remote repository URL as a new remote named “origin”. -
Push your local repository changes to the remote repository using the
git pushcommand. For example, if you want to push changes from the “master” branch to the “master” branch on the remote repository, you would use the following command:git push origin master. -
Verify that your changes have been successfully pushed to the remote repository by visiting the repository page on the hosting service.
-
To keep your local repository in sync with the remote repository, use the
git fetchandgit pullcommands to fetch and merge changes from the remote repository.
Note that the exact steps may vary depending on the hosting service and the Git client you are using. It’s also important to ensure that you have appropriate permissions and access to the remote repository before attempting to push or pull changes.
Understanding remote repositories and how they work with Git
In Git, a remote repository is a copy of a Git repository that is hosted on a server and can be accessed by multiple developers. It allows developers to collaborate on a project by sharing changes and updates to the codebase without having to be in the same physical location.
When you set up a remote repository, you create a link between your local repository and the remote repository, allowing you to push changes from your local repository to the remote repository and pull changes from the remote repository to your local repository.
By default, Git creates a remote repository named “origin” when you clone a repository from a remote location. However, you can also set up additional remote repositories to collaborate with other developers or to store backup copies of your codebase.
Creating a remote repository on a Git hosting service such as GitHub or GitLab
To create a remote repository on a Git hosting service such as GitHub or GitLab, follow these steps:
- Create an account on the Git hosting service if you don’t have one already.
- Log in to your account and navigate to the dashboard or main page.
- Click on the “New Repository” or “Create Repository” button.
- Enter a name for your repository and choose whether it should be public or private.
- Optionally, add a description for your repository and select any other settings or options that are available.
- Click the “Create Repository” button to create your new remote repository.
Once you have created a remote repository, you can push your local repository to it using the git push command. First, add the remote repository as a remote to your local repository using the git remote add command:
git remote add origin <remote_repository_url>Replace <remote_repository_url> with the URL of your remote repository. Then, push your local repository to the remote repository using the git push command:
git push -u origin masterThis will push the master branch of your local repository to the origin remote repository. If your local repository has multiple branches, you can push them to the remote repository by specifying the branch name instead of master.
Cloning a remote repository to a local machine with Git clone
To clone a remote repository to a local machine, you can use the git clone command followed by the URL of the remote repository. Here are the steps to follow:
-
Open a terminal or command prompt on your local machine.
-
Navigate to the directory where you want to clone the remote repository.
-
Use the
git clonecommand followed by the URL of the remote repository.For example, if you want to clone a repository named “my-repo” on GitHub, you can use the following command:
git clone https://github.com/username/my-repo.gitReplace
usernamewith your GitHub username. -
Press Enter to execute the command.
Git will download the contents of the remote repository and create a local copy on your machine. By default, Git will create a directory with the same name as the remote repository. You can also specify a different directory name by adding it as an argument to the git clone command.
Once the repository is cloned, you can use the git status command to see the current status of the repository.
Configuring remote repositories and managing access and permissions
When working with remote repositories, it is important to manage access and permissions to ensure that only authorized users can make changes to the repository. Here are some best practices for configuring remote repositories and managing access and permissions:
-
Use strong authentication: Make sure that all users accessing the repository are using strong authentication methods, such as SSH keys or two-factor authentication.
-
Limit access to authorized users: Ensure that only authorized users have access to the repository. You can do this by using access controls provided by the Git hosting service, such as GitHub or GitLab, or by configuring access controls on your own Git server.
-
Use branch protections: Set up branch protections to prevent accidental changes or force certain policies, such as requiring code reviews or ensuring that tests pass before merging.
-
Use pull requests: Require that changes to the repository be made through pull requests, which allow for review and approval of changes before they are merged.
-
Review and audit access regularly: Regularly review and audit the access to the repository to ensure that only authorized users have access and that access controls are working as intended.
By following these best practices, you can help ensure that your remote repository is secure and that changes are made in a controlled and auditable manner.
Pushing and pulling changes
In Git, pushing and pulling refer to the act of synchronizing changes between a local repository and a remote repository.
Pushing Changes
Pushing changes means sending the changes made in the local repository to the remote repository. This is done using the git push command followed by the name of the remote repository and the branch that the changes should be pushed to. For example, to push the changes made to the local master branch to the remote origin repository, the command would be:
git push origin masterIf the local repository is ahead of the remote repository, meaning there are changes in the local repository that have not been pushed to the remote repository, Git will reject the push with an error message. To resolve this, the --force option can be added to the push command:
git push --force origin masterHowever, it’s important to use this option with caution, as it can overwrite changes in the remote repository.
Pulling Changes
Pulling changes means getting the changes made in the remote repository and applying them to the local repository. This is done using the git pull command followed by the name of the remote repository and the branch that the changes should be pulled from. For example, to pull changes made to the master branch in the origin repository, the command would be:
git pull origin masterIf there are conflicts between the changes in the local repository and the changes being pulled from the remote repository, Git will prompt the user to resolve the conflicts manually.
In some cases, it may be necessary to fetch changes from the remote repository without applying them to the local repository. This can be done using the git fetch command, followed by the name of the remote repository and the branch that the changes should be fetched from:
git fetch origin masterThis will download the changes from the remote repository, but will not apply them to the local repository. To apply the changes, the git merge or git rebase command can be used, depending on the desired merging strategy.
Understanding Git push and Git pull and how they work with remote repositories
Git push and Git pull are two fundamental commands used to synchronize changes between a local repository and a remote repository.
Git push is used to upload local changes to a remote repository. It transfers the committed changes from the local repository to the remote repository, making them available to others who have access to that repository. Git push can be used to send changes to an existing branch, or to create a new branch in the remote repository.
Git pull is used to download changes from a remote repository into a local repository. It fetches the changes made in the remote repository and merges them into the local repository. Git pull can also be used to update the current branch with changes made in the remote repository.
In summary, Git push is used to upload local changes to a remote repository, and Git pull is used to download changes from a remote repository into a local repository. These commands are essential for collaboration in a team environment where multiple developers are working on the same codebase.
Pushing changes to a remote repository with Git push
Pushing changes to a remote repository with Git push involves sending your local changes to a remote repository so that others can access them. Here are the general steps for pushing changes to a remote repository:
-
First, make sure that you have committed your changes locally using the
git commitcommand. -
Next, use the
git pushcommand to push your changes to the remote repository. The syntax for the command isgit push <remote> <branch>, where<remote>is the name of the remote repository and<branch>is the name of the branch you want to push to.
For example, if you want to push your changes to a remote repository named “origin” and the branch you want to push to is named “main”, you would run the command git push origin main.
-
If you are pushing changes to a branch for the first time, you may need to use the
--set-upstreamoption to set the upstream branch. This allows Git to remember the relationship between your local branch and the corresponding remote branch. You can use the commandgit push --set-upstream <remote> <branch>to do this. -
If there are any conflicts between your local changes and changes that have been made to the remote branch since you last pulled from it, you will need to resolve the conflicts before you can push your changes.
-
Once you have pushed your changes, other contributors can access them by pulling from the remote repository using the
git pullcommand.
It’s important to note that you should always pull changes from the remote repository before you push your own changes, to avoid conflicts and ensure that you are working with the most up-to-date version of the code.
Pulling changes from a remote repository with Git pull
When you have a local repository that is connected to a remote repository, you can use git pull to retrieve changes from the remote repository and merge them into your local branch.
Here’s how the git pull command works:
-
Fetching changes from the remote repository:
git pullstarts by fetching the changes from the remote repository usinggit fetch. This command downloads all the new commits from the remote branch to your local repository, but it does not merge them into your local branch. -
Merging changes into your local branch: Once the changes are fetched,
git pullthen merges the changes into your local branch using the default merge strategy. If there are conflicts, Git will pause the merge process and ask you to resolve the conflicts manually.
The git pull command is a convenient way to keep your local repository in sync with the remote repository. However, it’s important to keep in mind that it automatically performs a merge, which can sometimes result in conflicts that need to be resolved.
Alternatively, you can use git fetch to download the changes from the remote repository without merging them into your local branch. This gives you the opportunity to review the changes before merging them manually using git merge or git rebase. This approach can help you avoid unexpected merge conflicts and gives you more control over the merge process.
Handling conflicts during push and pull operations
Conflicts can occur during push and pull operations when changes made to the same file or lines of code conflict with each other. Git provides several tools and strategies for resolving conflicts.
When pulling changes from a remote repository, Git will attempt to merge the changes with the local repository. If there are conflicts, Git will pause the merge process and mark the conflicted files. You can then use a text editor or a merge tool to manually resolve the conflicts. Once the conflicts are resolved, you can stage the changes and commit them.
When pushing changes to a remote repository, Git will check if the changes conflict with any other changes made to the remote repository since the last time the local repository was synced with the remote. If there are conflicts, Git will reject the push and prompt you to pull the latest changes from the remote repository and resolve any conflicts before attempting to push again.
Here are some best practices for handling conflicts during push and pull operations:
-
Pull often: To minimize the likelihood of conflicts, it’s a good idea to pull changes from the remote repository frequently. This ensures that your local repository is always up to date with the latest changes made to the remote repository.
-
Use descriptive commit messages: When committing changes, make sure to use descriptive commit messages that clearly explain the changes you made. This makes it easier for other contributors to understand your changes and resolve conflicts if they arise.
-
Use a merge tool: When resolving conflicts, consider using a merge tool instead of manually editing the conflicted files. A merge tool can highlight the differences between the conflicting changes and make it easier to decide how to resolve the conflicts.
-
Communicate with other contributors: If you’re working on a project with multiple contributors, it’s important to communicate with them about the changes you’re making and any potential conflicts that may arise. This can help prevent conflicts from occurring in the first place and make it easier to resolve conflicts if they do occur.
Resolving merge conflicts
Merge conflicts can occur when Git is unable to automatically merge changes from different branches or commits. In such situations, Git will stop the merge process and ask the user to resolve the conflicts manually.
Here are the general steps to resolve merge conflicts:
- Identify the conflicted files: Git will mark the files with conflicts with conflict markers. These are typically highlighted in the code, and look something like this:
<<<<<<< HEAD
Changes from the current branch
=======
Changes from the branch being merged
>>>>>>> other-branch-
Open the conflicted file in an editor: The conflicted file can be opened in a text editor or an integrated development environment (IDE) that supports Git conflict resolution.
-
Resolve the conflicts: Review the changes made in both branches and decide how to resolve the conflicts. This can involve editing the code to manually merge the changes, or choosing to accept one set of changes over the other.
-
Remove the conflict markers: Once the conflicts have been resolved, the conflict markers need to be removed. This involves deleting the lines containing
<<<<<<< HEAD,=======, and>>>>>>> other-branchfrom the conflicted file. -
Stage the changes: Once the conflict markers have been removed, the changes need to be staged for commit.
-
Commit the changes: Finally, commit the changes to complete the merge process.
It is important to carefully review and test the changes after resolving merge conflicts to ensure that the code works as intended. Additionally, it is a good practice to communicate with other team members who might have contributed to the conflicting changes to ensure that everyone is on the same page.
Understanding merge conflicts and how to avoid them
A merge conflict occurs when Git is unable to automatically resolve differences between two branches or commits that are being merged. It happens when two or more people work on the same file at the same time and make changes to the same lines of code.
Git tries to merge changes automatically and creates a new merge commit if there are no conflicts. However, if there are conflicts, Git cannot merge the changes automatically, and it requires manual intervention to resolve them.
To avoid merge conflicts, it is best to follow some best practices, including:
-
Pull frequently: Pulling regularly from the remote repository can help you keep your local repository up to date with the latest changes, reducing the likelihood of conflicts.
-
Keep commits small and focused: Commits should be small and focused on a single task, making it easier to merge them into other branches and reducing the likelihood of conflicts.
-
Use feature branches: Creating feature branches for new features or bug fixes can isolate changes from the main codebase, reducing the likelihood of conflicts with other developers’ changes.
-
Communicate with your team: Communicate with your team to ensure everyone is aware of changes and avoid working on the same code at the same time.
If a merge conflict occurs, it is essential to resolve it as soon as possible. The following steps can help in resolving merge conflicts:
-
Identify the conflicted files: Git will indicate which files have conflicts that need to be resolved.
-
Edit the conflicted files: Open the files in a text editor and look for the sections with conflict markers that indicate where the conflicts occurred.
-
Resolve the conflicts: Edit the conflicting sections manually, or choose one of the versions to keep and discard the others.
-
Add the changes and commit: After resolving the conflicts, stage the changes and commit the merge.
-
Push the changes: Finally, push the changes to the remote repository to complete the merge.
By following these best practices and resolving conflicts as soon as they occur, you can ensure that your Git repository is always up to date, and changes can be merged seamlessly.
Resolving merge conflicts with Git merge and Git mergetool
When Git merges two branches with conflicting changes, it may not be able to automatically resolve the differences, resulting in a merge conflict. Git will signal the conflict and leave the conflicting changes in the working tree and index.
To resolve the conflict, the developer must manually edit the affected files, choose which changes to keep, and remove the conflict markers added by Git. The conflict markers are typically surrounded by <<<<<<<, =======, and >>>>>>> characters, indicating the two versions of the code that Git was unable to reconcile.
Here are the steps to resolve a merge conflict with Git merge:
- Use
git statusto check which files have conflicts. - Open each file with a merge conflict in a text editor and manually resolve the conflicts by editing the file. Remove the conflict markers added by Git and choose which version of the code to keep. Save the changes.
- After resolving all conflicts, stage the modified files with
git add. - Use
git committo create a new commit that records the merge result. - If necessary, use
git pushto update the remote repository with the new commit.
Alternatively, you can use git mergetool to launch a visual merge tool that helps resolve the conflicts. The git mergetool command automatically opens the configured merge tool (e.g., Beyond Compare, KDiff3, or vimdiff) and presents a three-way merge view that shows the original file, the current version, and the conflicting changes. You can then use the merge tool to manually edit the file and resolve the conflicts.
Here are the steps to resolve a merge conflict with git mergetool:
- Use
git statusto check which files have conflicts. - Use
git mergetoolto launch the configured merge tool. - In the merge tool, edit the file and resolve the conflicts. Save the changes.
- Use
git mergetool --continueto mark the file as resolved and move to the next file with conflicts. - After resolving all conflicts, use
git committo create a new commit that records the merge result. - If necessary, use
git pushto update the remote repository with the new commit.
It is essential to resolve conflicts promptly and communicate with other developers to avoid conflicts in the future. One way to minimize conflicts is to use feature branches and merge them frequently into the main branch to ensure that changes are integrated early and often. It’s also important to establish clear guidelines and best practices for version control, such as avoiding large commits or conflicting changes, reviewing code before merging, and using automated tests and code quality tools.
Strategies for communicating and collaborating with team members to resolve conflicts
Resolving conflicts in Git is an essential part of collaborating with a team, especially when working on a shared codebase. Communication and collaboration are crucial to ensure everyone is aware of the conflicts and can work together to resolve them effectively. Here are some strategies for communicating and collaborating with team members to resolve conflicts:
-
Use a shared communication channel: Use a shared communication channel, such as a chat app, email, or issue tracker, to notify team members of conflicts and their resolution. This ensures everyone is aware of the changes and avoids any duplication of effort.
-
Document the resolution: Document the resolution of conflicts, including the steps taken to resolve them and any decisions made. This helps avoid the same conflicts in the future and provides a reference for future team members.
-
Assign roles and responsibilities: Assign roles and responsibilities to team members involved in resolving conflicts, such as the person responsible for identifying the conflicts, the person responsible for resolving them, and the person responsible for testing the changes.
-
Collaborate in real-time: Collaborate in real-time using pair programming or screen sharing to work on resolving conflicts together. This allows team members to discuss the conflicts, identify the best solutions, and resolve them quickly.
-
Use version control tools: Use version control tools such as Git to track changes and resolve conflicts. Git provides tools such as merge, rebase, and cherry-pick to resolve conflicts effectively.
-
Encourage open communication: Encourage open communication among team members to ensure everyone feels comfortable asking questions, providing feedback, and sharing their perspectives on the conflicts. This helps build a culture of collaboration and promotes a positive team dynamic.
Git workflows for team collaboration
There are several Git workflows that teams can use to collaborate effectively on a project. Here are a few of the most common ones:
-
Centralized workflow: In this workflow, all team members work on a single branch and push their changes to a central repository. This is a simple and straightforward approach, but it can lead to conflicts if multiple team members are working on the same file at the same time.
-
Feature branch workflow: In this workflow, each feature or task is developed on a separate branch, which is then merged into the main branch once it is complete. This allows team members to work on separate features without interfering with each other’s work.
-
Gitflow workflow: This workflow is based on the feature branch workflow but adds additional branches for releases and hotfixes. It includes a “develop” branch for ongoing development and a “release” branch for preparing releases.
-
Forking workflow: In this workflow, each team member forks the main repository to their own personal account, develops their changes on a separate branch, and then creates a pull request to merge their changes back into the main repository. This approach allows for a high degree of parallel development and is often used in open source projects.
-
Pull request workflow: In this workflow, team members create feature branches, make changes, and then create a pull request to merge their changes into the main branch. This approach adds an additional layer of review and approval before changes are merged into the main branch.
Ultimately, the right Git workflow will depend on the specific needs and goals of your team. It’s important to choose a workflow that fits the size and complexity of your project, as well as the communication and collaboration style of your team.
Understanding different Git workflows for team collaboration such as Gitflow and GitHub flow
Different Git workflows are methodologies that teams use to organize their development and collaboration using Git. These workflows provide guidelines on how to structure the Git repositories, branches, and releases to ensure efficient collaboration and code quality.
Two popular Git workflows are Gitflow and GitHub flow:
-
Gitflow: This workflow emphasizes the importance of having a clear branching strategy and release cycle. It is a branch-based workflow that uses two primary branches: master and develop. The master branch is used for stable releases, while the develop branch is where the team collaborates and integrates new features. Feature branches are created off the develop branch, and pull requests are used to merge them back into the develop branch once they are complete. When a release is ready, a release branch is created from the develop branch, and bug fixes are made on this branch until it is ready for deployment.
-
GitHub flow: This workflow is a simplified version of Gitflow that focuses on continuous deployment and rapid iteration. It is a branch-based workflow that uses only one primary branch: master. All changes are made in feature branches that are created off the master branch. Once a feature is complete, a pull request is created to merge the changes into the master branch. Automated testing and code review are used to ensure code quality before merging. Once merged, the changes are automatically deployed to production.
Both workflows have their advantages and disadvantages, and choosing the right one for a team depends on their specific needs and goals. It is also possible to customize these workflows or create a new one that suits the team’s needs.
Choosing a Git workflow that fits the needs of the team and project
Choosing the right Git workflow depends on the specific needs and goals of the team and project. Some common Git workflows for team collaboration include:
-
Centralized Workflow: This is a simple workflow in which all developers work on a single branch, usually the master branch. Developers clone the repository, make changes, commit them, and push them to the remote repository. This workflow is best suited for small teams working on small projects.
-
Feature Branch Workflow: This is a popular workflow in which each feature or change is developed in a separate branch. Developers create a new branch for each feature, make changes, commit them, and push them to the remote repository. Once the feature is complete, the branch is merged into the master branch. This workflow is best suited for medium to large teams working on projects with multiple features or changes.
-
Gitflow Workflow: This is a more complex workflow in which the development process is divided into two main branches: the master branch and the develop branch. The master branch contains the stable, production-ready code, while the develop branch contains the latest code that is still being developed. Developers create feature branches off the develop branch, make changes, commit them, and push them to the remote repository. Once the feature is complete, the branch is merged back into the develop branch. This workflow is best suited for larger teams working on complex projects with multiple features and releases.
-
GitHub Flow: This is a simplified workflow that is commonly used in open-source projects hosted on GitHub. Developers create a new branch for each feature or change, make changes, commit them, and push them to the remote repository. Once the feature is complete, a pull request is created and reviewed by other team members. Once the pull request is approved, the branch is merged into the master branch. This workflow is best suited for small to medium teams working on open-source projects.
When choosing a Git workflow, it’s important to consider factors such as the size and complexity of the project, the size of the team, and the level of collaboration and communication required. It’s also important to regularly review and adapt the workflow as the project and team evolve.
Implementing and enforcing Git workflows with tools such as Git hooks and pull request reviews
Implementing and enforcing Git workflows can help ensure consistent and efficient collaboration within a team. There are several tools and practices that can be used to help enforce these workflows:
-
Git hooks: Git hooks can be used to run custom scripts or commands before or after certain Git actions, such as committing or pushing changes. These hooks can be used to enforce certain workflows or conventions, such as requiring certain commit message formats or checking for code quality issues before allowing changes to be pushed.
-
Pull request reviews: Pull request reviews can be used to enforce certain workflows or conventions for merging changes into the main branch. For example, a team may require that changes be reviewed by at least two team members before being merged, or that certain tests or checks pass before allowing changes to be merged.
-
Continuous integration/continuous delivery (CI/CD) pipelines: CI/CD pipelines can be used to automate the process of building, testing, and deploying changes. These pipelines can be configured to enforce certain workflows or conventions, such as requiring certain tests to pass before allowing changes to be merged or automatically deploying changes to production after they have been reviewed and approved.
-
Documentation: Clear and comprehensive documentation can help ensure that team members understand and follow the established workflows. This documentation should include information on the expected Git workflow, the tools and practices used to enforce it, and any relevant conventions or guidelines.
Ultimately, the choice of tools and practices for enforcing Git workflows will depend on the needs and preferences of the team and project. The key is to establish clear expectations and guidelines for collaboration, and to use tools and practices that support those expectations and make it easy for team members to follow them.
Best practices for communication, collaboration, and conflict resolution in a team using Git
Effective communication, collaboration, and conflict resolution are crucial for teams using Git to work on projects together. Here are some best practices to keep in mind:
-
Establish clear communication channels: Make sure team members know how to communicate with each other, whether it’s through email, chat, video conferencing, or in-person meetings. Establishing clear communication channels can help prevent misunderstandings and ensure that everyone is on the same page.
-
Use a shared understanding of project goals: Make sure everyone on the team understands the project goals and what is expected of them. This can help ensure that everyone is working towards the same objectives and can help prevent conflicts and misunderstandings.
-
Establish clear roles and responsibilities: Define clear roles and responsibilities for each team member, including who is responsible for what tasks, who makes decisions, and who is responsible for resolving conflicts. This can help prevent misunderstandings and ensure that everyone knows what is expected of them.
-
Use a Git workflow that fits the team’s needs: Choose a Git workflow that fits the team’s needs and the project’s requirements. This can help ensure that everyone knows how to use Git effectively and can help prevent conflicts and misunderstandings.
-
Enforce code reviews and pull requests: Use code reviews and pull requests to ensure that all code changes are reviewed and approved by other team members before being merged into the main branch. This can help ensure that code quality is maintained and can help prevent conflicts and misunderstandings.
-
Resolve conflicts quickly: If conflicts do arise, it’s important to resolve them quickly and effectively. This may involve bringing in a third party to mediate or finding a compromise that works for all parties involved.
-
Foster a culture of open communication and feedback: Encourage team members to communicate openly and provide feedback to each other. This can help prevent conflicts and misunderstandings and can help the team work more effectively together.
By following these best practices, teams can effectively communicate, collaborate, and resolve conflicts when using Git to work on projects together.
Git hooks and automation
Git hooks and automation can greatly improve the efficiency and consistency of a Git workflow by automating certain tasks and enforcing best practices. Git hooks are scripts that are run automatically by Git in response to certain events, such as committing changes or pushing to a remote repository. There are two types of Git hooks: client-side hooks, which are run on the developer’s local machine, and server-side hooks, which are run on the remote repository.
Here are some ways Git hooks and automation can be used:
-
Enforcing code quality standards: Git hooks can be used to enforce coding standards such as formatting, linting, and testing. For example, a pre-commit hook can be used to ensure that code is formatted correctly before it is committed.
-
Automating repetitive tasks: Git hooks can be used to automate repetitive tasks such as building and deploying the code. For example, a post-commit hook can be used to trigger a build process after changes are committed.
-
Enforcing security policies: Git hooks can be used to enforce security policies such as requiring commit messages to include a specific prefix or suffix. For example, a pre-commit hook can be used to ensure that commit messages include a ticket number.
-
Customizing Git behavior: Git hooks can be used to customize Git behavior. For example, a post-checkout hook can be used to automatically install dependencies when switching branches.
To use Git hooks, simply create a script and save it in the appropriate directory in the Git repository’s .git/hooks folder. The script must be executable, and the name of the script must match the name of the hook. For example, to create a pre-commit hook, create a script called pre-commit and save it in the .git/hooks folder.
It’s important to note that Git hooks are not a substitute for good communication and collaboration practices. While Git hooks can help enforce best practices and automate certain tasks, it’s still important for team members to communicate and collaborate effectively to ensure that everyone is working towards the same goals and objectives.
Understanding Git hooks and how they work
Git hooks are scripts that Git executes automatically at specific points in the Git workflow. Git hooks can be used to automate tasks such as running tests, formatting code, or sending notifications. Git hooks are stored in the .git/hooks directory of a Git repository, and are run locally on the user’s machine.
There are two types of Git hooks: client-side and server-side. Client-side hooks are run on the user’s local machine, while server-side hooks are run on the Git server.
Git provides a set of sample hooks that can be used as a starting point for creating custom hooks. The sample hooks are stored in the .git/hooks directory with a .sample extension.
To use a Git hook, simply create a script with the appropriate name in the .git/hooks directory, and make sure it is executable. When Git reaches the appropriate point in the workflow, it will run the corresponding hook.
Some common use cases for Git hooks include:
- Running tests before commits are made
- Enforcing code formatting standards
- Notifying team members of changes to the repository
- Automatically generating documentation or release notes
- Enforcing commit message guidelines
Overall, Git hooks can be a powerful tool for automating repetitive tasks and ensuring consistency in a team’s workflow.
Creating and using Git hooks for automating repetitive tasks and enforcing Git policies
Git hooks are scripts that can be run automatically by Git when certain events occur. These scripts can be used to automate repetitive tasks, enforce Git policies, or perform other custom actions. Git supports two types of hooks: client-side and server-side.
Client-side hooks are scripts that run on the local machine of each Git user. They are stored in the .git/hooks directory of each Git repository, but are not committed to the repository itself. Client-side hooks can be used to enforce certain policies or automate certain tasks for each user, such as running code linting or testing before each commit.
Server-side hooks are scripts that run on the Git server when certain Git events occur, such as receiving a push or receiving a pull request. They are stored in the hooks directory of the Git server and apply to all users who interact with the repository. Server-side hooks can be used to enforce more strict policies, such as rejecting pushes that do not meet certain criteria or automatically triggering certain actions upon certain events.
To create a Git hook, simply create a script file with the appropriate name in the .git/hooks directory of a Git repository. Git will automatically run the script when the corresponding Git event occurs. For example, to run a script before each commit, create a file named pre-commit in the .git/hooks directory and make it executable.
It is important to note that Git hooks are not meant to be used as a security mechanism, as they can be easily bypassed by a determined user. Instead, they should be used as a tool for automating tasks and enforcing policies. It is also important to communicate clearly with team members about the use of Git hooks and any policies they enforce to avoid confusion or frustration.
Examples of useful Git hooks such as pre-commit hooks and post-receive hooks
Sure! Here are some examples of useful Git hooks:
-
Pre-commit hook: This hook is triggered before a commit is made and can be used to run automated tests, linters, and other checks on the code being committed. This helps catch errors early on and ensures that the code is of high quality before it is committed.
-
Post-commit hook: This hook is triggered after a commit is made and can be used to perform tasks such as sending notifications or updating documentation.
-
Pre-push hook: This hook is triggered before changes are pushed to a remote repository and can be used to run additional tests or checks to ensure that the code being pushed meets certain quality standards.
-
Post-merge hook: This hook is triggered after a merge is completed and can be used to run additional checks on the merged code or perform other tasks such as updating dependencies.
-
Post-receive hook: This hook is triggered on the remote repository after changes are received and can be used to perform tasks such as deploying the updated code to a production server.
Overall, Git hooks are a powerful tool for automating repetitive tasks and ensuring that team members follow certain Git policies and practices.
Best practices for using Git hooks effectively and avoiding common issues
Here are some best practices for using Git hooks effectively:
-
Understand the different types of Git hooks: Git has several types of hooks, such as pre-commit, pre-push, post-commit, post-merge, etc. Each hook is triggered at a specific point in the Git workflow, and you can use them to automate repetitive tasks, enforce policies, or run tests.
-
Write clear and concise scripts: When creating a Git hook, write a clear and concise script that does only one thing. Avoid complex scripts that are difficult to understand and maintain.
-
Use version control: Git hooks are stored in the
.git/hooksdirectory of your local repository. However, it’s a good practice to store them in version control, so you can share them with your team and keep track of changes. -
Test your hooks: Before deploying a Git hook, test it thoroughly to make sure it works as expected. You can use a test repository to test your hooks, and make sure they don’t interfere with other Git workflows.
-
Document your hooks: When creating a Git hook, document its purpose and how to use it. This will make it easier for other developers to understand and use your hook.
-
Consider using pre-commit hooks: Pre-commit hooks are a useful type of Git hook that runs before a commit is created. You can use pre-commit hooks to check for formatting errors, run tests, or enforce coding standards.
-
Use Git hooks in combination with other tools: Git hooks can be used in combination with other tools to automate tasks or enforce policies. For example, you can use a pre-commit hook to check code formatting, and a continuous integration (CI) system to run tests.
-
Don’t rely solely on Git hooks for security: Git hooks can be used to enforce security policies, such as preventing sensitive information from being committed. However, they should not be the only line of defense. You should also use other security measures, such as access controls and encryption.
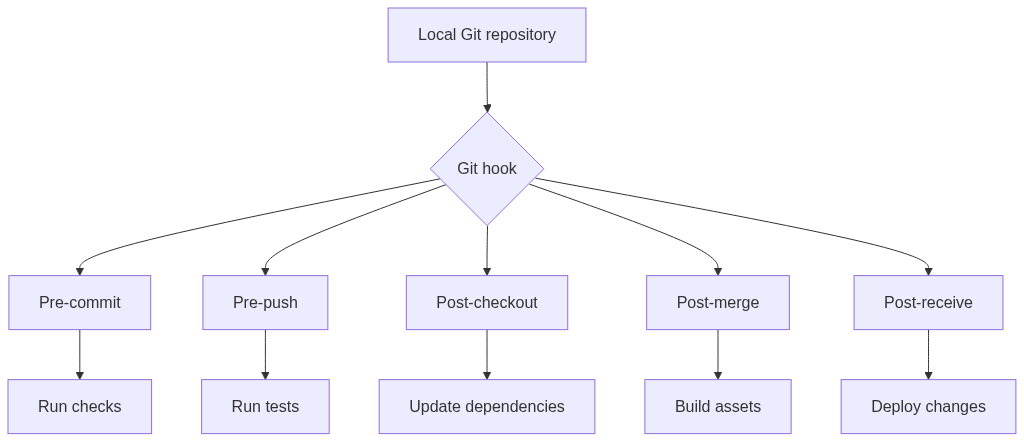
By following these best practices, you can use Git hooks effectively and avoid common issues.
Git hosting and CI/CD integration
Git hosting and CI/CD integration are two essential components of modern software development. Git hosting platforms provide a centralized location for storing and managing Git repositories, while CI/CD tools automate the process of building, testing, and deploying software. In this way, Git hosting and CI/CD integration work together to streamline the development process and ensure that software is delivered quickly and reliably.
There are many Git hosting platforms available, including GitHub, GitLab, Bitbucket, and more. These platforms provide features such as issue tracking, pull request reviews, and team collaboration tools, in addition to Git repository management.
CI/CD tools, such as Jenkins, Travis CI, and CircleCI, provide automation for building, testing, and deploying software. These tools integrate with Git hosting platforms, allowing developers to trigger builds and deployments based on changes to a Git repository.
Best practices for Git hosting and CI/CD integration include:
-
Choose a Git hosting platform that fits the needs of your team and project. Consider factors such as pricing, features, and integrations with other tools.
-
Use version control best practices, such as creating feature branches, using pull requests for code reviews, and enforcing code quality standards.
-
Implement CI/CD pipelines that build and test code automatically when changes are pushed to the repository. Use automated tests to catch bugs early in the development process.
-
Use deployment pipelines to automate the process of deploying code to production environments. Use tools like canary releases and blue/green deployments to minimize downtime and risk.
-
Integrate security testing into your CI/CD pipelines to ensure that software is secure and compliant with industry standards.
-
Use automation to enforce Git policies, such as commit message formatting, code style guidelines, and branch naming conventions.
-
Provide documentation and training for team members on Git hosting and CI/CD best practices to ensure that everyone is following the same processes and standards.
Integrating Git with continuous integration and continuous deployment (CI/CD) tools
Continuous Integration (CI) and Continuous Deployment (CD) are practices that aim to improve the speed and quality of software development by automating the process of building, testing, and deploying software. Git plays a critical role in the CI/CD pipeline, as it provides a way to manage changes and collaborate on code across the development team.
There are several ways to integrate Git with CI/CD tools, including:
-
Git hosting platforms such as GitHub, GitLab, and Bitbucket provide built-in integration with popular CI/CD tools such as Jenkins, Travis CI, and CircleCI. These integrations typically allow you to trigger builds and deployments automatically when new code is pushed to a repository.
-
Many CI/CD tools offer their own Git clients that can be used to clone, checkout, and pull code from a Git repository. This allows you to automate the process of building, testing, and deploying code without having to manually interact with Git.
-
Git hooks can be used to trigger custom scripts that automate specific tasks in the CI/CD pipeline, such as running tests or deploying code to a production environment. This allows you to customize the CI/CD process to fit the needs of your specific project.
When integrating Git with CI/CD tools, it’s important to follow best practices for security and version control. For example, you should ensure that access to your Git repository is limited to authorized users, and that all changes are tracked and reviewed using Git’s version control features. Additionally, you should implement automated testing and deployment processes to ensure that code changes are thoroughly tested and deployed in a controlled and consistent manner.
Understanding Git hosting and how it works with Git repositories
Git hosting refers to the storage and management of Git repositories on a remote server. Git hosting services such as GitHub, GitLab, and Bitbucket provide a centralized location for storing and sharing Git repositories with team members and collaborators. These services offer features such as access control, issue tracking, pull request reviews, and integration with other tools.
Git hosting services also provide APIs and webhooks that enable integration with continuous integration and continuous deployment (CI/CD) tools. CI/CD tools automate the build, testing, and deployment processes of software projects. By integrating with Git hosting services, CI/CD tools can automatically trigger builds and deployments based on changes pushed to Git repositories.
Some popular CI/CD tools that integrate with Git hosting services include Travis CI, CircleCI, Jenkins, and GitLab CI/CD. These tools offer a variety of features such as customizable pipelines, automatic testing, and deployment to various environments.
Examples of popular Git hosting and CI/CD platforms such as GitHub, GitLab, and Travis CI
Sure! Here are some popular Git hosting and CI/CD platforms:
-
GitHub: A web-based hosting service for Git repositories. It provides collaboration features like bug tracking, feature requests, task management, and wikis. GitHub also offers a built-in continuous integration and deployment platform called GitHub Actions.
-
GitLab: A web-based Git repository manager that provides source code management, continuous integration and deployment, and team collaboration features. GitLab offers both on-premise and cloud-based options.
-
Bitbucket: A web-based hosting service for Git repositories that provides collaboration features and continuous integration and deployment tools. It also supports Mercurial repositories.
-
Travis CI: A cloud-based continuous integration and deployment platform that integrates with GitHub and GitLab repositories. Travis CI can automatically build, test, and deploy your code to multiple platforms and environments.
-
Jenkins: An open-source automation server that supports continuous integration and deployment. Jenkins can be integrated with Git repositories and other tools to automate the software delivery process.
-
CircleCI: A cloud-based continuous integration and deployment platform that integrates with GitHub and Bitbucket repositories. CircleCI can automatically build, test, and deploy your code to multiple platforms and environments.
-
AWS CodeCommit: A managed Git hosting service provided by Amazon Web Services (AWS). CodeCommit provides a secure, scalable, and highly available repository that can be integrated with AWS CodePipeline for continuous delivery.
There are many other Git hosting and CI/CD platforms available, and choosing the right one depends on your specific needs and requirements.
Best practices for using Git hosting and CI/CD integration to improve collaboration and streamline development processes
Here are some best practices for using Git hosting and CI/CD integration effectively:
-
Choose a platform that fits your needs: There are many Git hosting and CI/CD platforms available, and each has its own set of features and pricing models. Consider factors such as cost, scalability, ease of use, and integration with other tools when selecting a platform.
-
Use a consistent naming convention: Use a consistent naming convention for your repositories, branches, and tags. This will make it easier for team members to find and understand the purpose of each repository, branch, and tag.
-
Keep your repositories organized: Keep your repositories organized by using a folder structure that reflects the different parts of your project. Use submodules or subtrees for dependencies that are shared across multiple repositories.
-
Use pull requests for code reviews: Use pull requests to review and approve changes before they are merged into the main branch. This helps to catch errors and ensure that the code meets the team’s standards and best practices.
-
Automate your workflow: Automate your workflow as much as possible using Git hooks, CI/CD pipelines, and other tools. This helps to ensure that your code is consistently tested, built, and deployed in a predictable and repeatable way.
-
Test your code thoroughly: Test your code thoroughly using automated tests and manual testing. Use code coverage tools to measure how much of your code is being tested and to identify areas that require more testing.
-
Monitor your deployments: Monitor your deployments using tools such as logs, metrics, and alerts. This helps to identify issues early and ensure that your code is running smoothly in production.
-
Communicate effectively: Communicate effectively with your team members using tools such as chat, email, and issue trackers. Use a consistent format for commit messages, pull request descriptions, and other forms of communication to ensure that everyone understands what is happening in the project.
By following these best practices, you can use Git hosting and CI/CD integration to improve collaboration and streamline development processes.
Chapter 5: Git Branching Strategies
The importance of branching in Git
In Git, branching is a powerful feature that allows developers to create new branches of code from an existing codebase. This enables multiple developers to work on different features or bug fixes simultaneously without interfering with each other’s work.
Branching allows developers to work on code changes in isolation without affecting the main codebase. They can experiment with new features or fix bugs without worrying about breaking the existing code. Once the changes have been tested and reviewed, they can be merged back into the main codebase.
Branching also enables developers to maintain multiple versions of their code. They can create branches for different releases or environments, such as development, staging, and production. This makes it easier to deploy code changes to different environments and to revert changes if necessary.
In summary, branching is an important aspect of Git because it allows developers to work collaboratively, experiment with new features, and maintain multiple versions of their codebase.
Understanding the benefits of using branching in Git
Using branching is one of the key benefits of using Git as a version control system. Branching allows multiple parallel versions of code to be developed and maintained independently of each other. This can be extremely useful in a number of scenarios, such as:
-
Feature development: Branching can be used to isolate the work on a new feature, allowing the developer to make changes to the code without affecting the main codebase.
-
Bug fixing: Branching can be used to isolate the work on a bug fix, allowing the developer to make changes to the code without affecting the main codebase.
-
Experimentation: Branching can be used to try out new ideas and experimental features, without affecting the stability of the main codebase.
-
Collaboration: Branching can be used to allow multiple developers to work on the same codebase at the same time, without stepping on each other’s toes.
-
Releases: Branching can be used to create stable versions of the code, which can be released to users.
Overall, branching allows for a more flexible and efficient development process, as it allows developers to work independently and in parallel, while still maintaining a coherent codebase.
How branching allows for experimentation and feature development without affecting the main codebase
In Git, branching allows developers to create parallel versions of the codebase, known as branches, that can be modified independently without affecting the main codebase. This provides a number of benefits, including:
-
Experimentation: Branching allows developers to experiment with new features or ideas without affecting the stability of the main codebase. They can create a new branch, make changes, test them, and discard the branch if the changes don’t work out.
-
Feature development: Branching also enables developers to work on new features or bug fixes in isolation, without worrying about how their changes will impact other parts of the codebase. They can create a new branch, make changes, test them, and then merge the branch back into the main codebase once the changes have been reviewed and tested.
-
Collaboration: Branching also makes it easier for multiple developers to work on the same codebase simultaneously. Each developer can create their own branch to work on their changes, and then merge those changes back into the main codebase once they’re ready.
-
Code review: Branching also facilitates code reviews by allowing developers to create a branch specifically for review. This makes it easier for reviewers to see the changes that have been made and provide feedback.
Overall, branching is a powerful feature of Git that enables developers to work more efficiently, collaborate more effectively, and experiment with new ideas without risking the stability of the main codebase.
How branching enables collaboration and parallel development workflows
Branching enables collaboration and parallel development workflows by allowing developers to work on different features or bug fixes independently in their own branches. This allows for multiple team members to work on different parts of a project simultaneously without interfering with each other’s work.
For example, a team can have a main branch that represents the production-ready codebase. Developers can create separate branches from the main branch to work on specific features or fixes. Once a feature or fix is complete, it can be merged back into the main branch for integration and testing.
This approach allows teams to develop new features and fix bugs in parallel, without worrying about conflicting changes or causing regressions in the main codebase. It also allows for experimentation and testing of new ideas without affecting the main codebase. Overall, branching helps teams to work more efficiently and effectively together.
Git flow
Git flow is a branching model and set of conventions for using Git, designed to facilitate parallel development and easy release management for software projects. It was created by Vincent Driessen and has become a popular and widely-used approach to managing Git repositories.
At a high level, Git flow involves creating several long-lived branches for different purposes:
- Master: the main branch that always reflects the current state of production-ready code.
- Develop: a branch for integrating features and changes that are not yet production-ready.
- Feature branches: created off of the develop branch and used for developing new features or making changes to existing ones.
- Release branches: created off of the develop branch when it’s time to prepare a new release.
- Hotfix branches: created off of the master branch to fix critical bugs in production.
The basic workflow involves developers creating feature branches off of the develop branch, making changes and committing them to their feature branch, and then merging their feature branch back into develop when the changes are complete and tested. When it’s time to release new changes, a release branch is created from the develop branch and tested thoroughly. Once it’s ready, the release branch is merged into both master and develop, and tagged with a version number.
Hotfixes are handled similarly to releases, with a hotfix branch being created off of the master branch and then merged back into both master and develop once the fix is complete and tested.
The Git flow approach can help teams manage complex software projects with multiple contributors and dependencies, by providing a clear and well-defined structure for development and release management. However, it may not be the best fit for all projects and teams, and there are alternative branching models and workflows that can also be effective.
Understanding Git flow and its purpose
Git flow is a branching model for Git that helps teams manage their codebase and collaborate more effectively. Its purpose is to provide a consistent workflow for creating and merging branches, making it easier to keep track of changes and collaborate on code.
The Git flow model defines two main branches: master and develop. The master branch represents the official release history of the project, while the develop branch is used for ongoing development work.
New features are developed in separate branches off the develop branch, and when they are complete, they are merged back into develop. When it is time to release a new version of the software, a release branch is created off develop, and bug fixes are applied to this branch. Once the release is ready, it is merged into master, and the cycle starts again.
By using Git flow, teams can work on features in isolation without worrying about disrupting the rest of the codebase. It also provides a clear path for releasing software, making it easier to manage and track changes over time.
The different branches used in Git flow such as master, develop, feature, release, and hotfix branches
Git flow defines several types of branches that are used in the branching model:
-
masterbranch: Represents the official release history of the project. It should always contain the latest stable version of the software. -
developbranch: Used for ongoing development work. It should always contain the latest development changes that are not yet ready for release. -
featurebranches: Used to develop new features for the software. Each feature is developed in its own branch, which is based off thedevelopbranch. Once the feature is complete, it is merged back intodevelop. -
releasebranches: Used to prepare a new release of the software. A release branch is created off thedevelopbranch, and any final bug fixes or changes are applied to this branch. Once the release is ready, it is merged intomasteranddevelop. -
hotfixbranches: Used to quickly fix critical bugs in the software. A hotfix branch is created off themasterbranch, and the fix is applied to this branch. Once the fix is complete, it is merged back intomasteranddevelop.
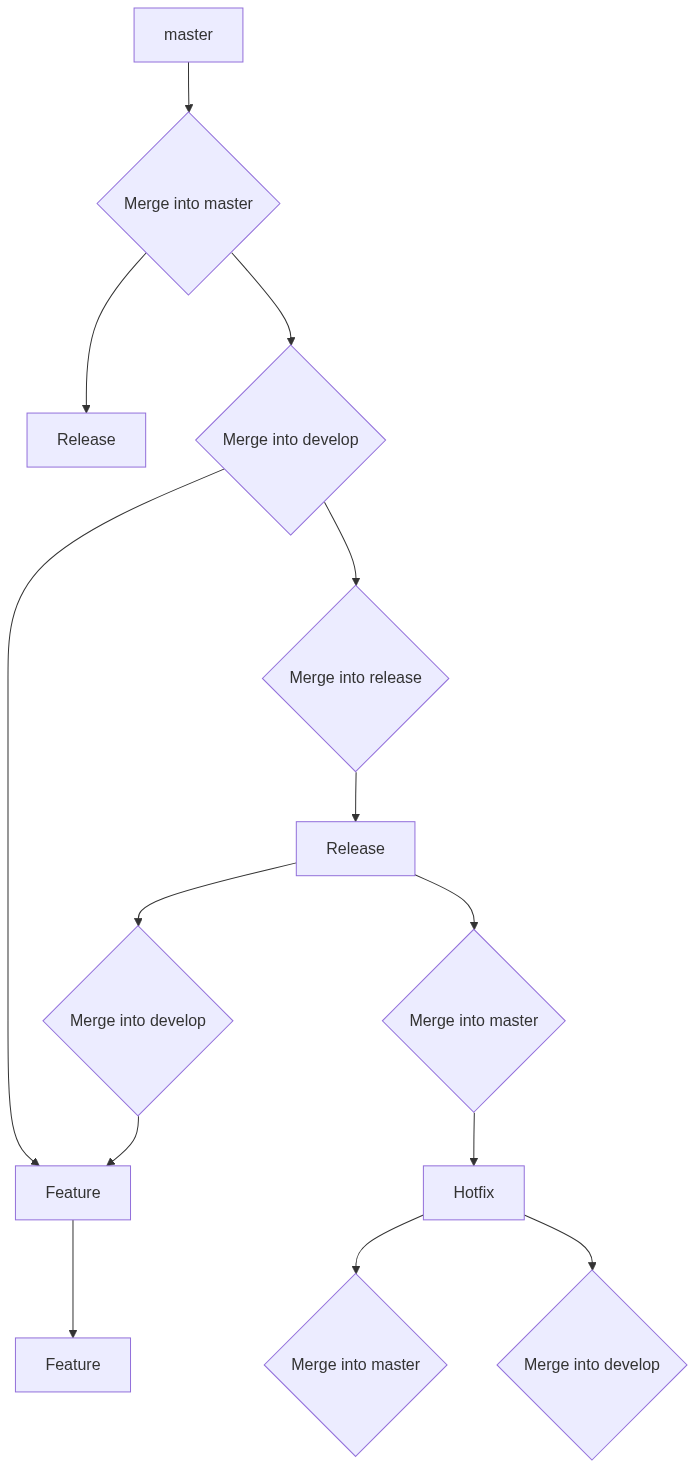
Each type of branch has a specific purpose in the Git flow model and helps teams collaborate more effectively on their codebase.
How to use Git flow to manage software releases and feature development
Here are the general steps to use Git flow to manage software releases and feature development:
-
Initialize Git flow: To start using Git flow, you need to initialize it in your repository using the command
git flow init. This command will set up the main branches (masteranddevelop) and the default prefixes for feature, release, and hotfix branches. -
Create a feature branch: When you want to add a new feature to your software, create a new branch using the command
git flow feature start <feature-name>. This will create a new branch based on thedevelopbranch and switch you to that branch. -
Develop your feature: Once you are on the feature branch, you can start developing your feature. Commit your changes as you go, using descriptive commit messages.
-
Finish the feature: When your feature is complete, use the command
git flow feature finish <feature-name>to merge the feature branch back into thedevelopbranch and delete the feature branch. -
Create a release branch: When you are ready to release a new version of your software, create a new release branch using the command
git flow release start <release-version>. This will create a new branch based on thedevelopbranch and switch you to that branch. -
Prepare the release: On the release branch, you can make any final bug fixes or changes needed for the release. Once everything is ready, use the command
git flow release finish <release-version>to merge the release branch back into bothmasteranddevelopbranches, tag the release with the version number, and delete the release branch. -
Create a hotfix branch: If a critical bug is found in your software that needs to be fixed immediately, create a new hotfix branch using the command
git flow hotfix start <version>. This will create a new branch based on themasterbranch and switch you to that branch. -
Fix the bug: On the hotfix branch, fix the critical bug and commit your changes.
-
Finish the hotfix: Once the bug is fixed, use the command
git flow hotfix finish <version>to merge the hotfix branch back into bothmasteranddevelopbranches, tag the release with the version number, and delete the hotfix branch.
These are the basic steps to use Git flow to manage software releases and feature development. By following this workflow, you can ensure that your codebase is always in a stable state and that releases are well-managed and well-documented.
Best practices for using Git flow in a team environment
Here are some best practices for using Git flow in a team environment:
-
Use descriptive branch names: When creating new branches, use descriptive names that indicate the purpose of the branch. This will make it easier for other team members to understand what the branch is for and whether it is safe to merge.
-
Follow the Git flow model strictly: To ensure consistency and prevent mistakes, it’s important to follow the Git flow model strictly. This means always creating feature branches off the
developbranch, release branches off thedevelopbranch, and hotfix branches off themasterbranch. -
Keep branches up-to-date: Make sure to regularly pull changes from the main branches (
masteranddevelop) to keep your feature or release branch up-to-date. This will prevent conflicts when it’s time to merge your branch back into the main branch. -
Review code before merging: Before merging a branch back into the main branch, make sure to review the code and ensure that it meets the team’s standards and guidelines. This will help catch any errors or issues before they are integrated into the main codebase.
-
Use tags for releases: When a release is complete, make sure to tag it with the version number using the command
git tag. This will make it easier to reference and track releases in the future. -
Communicate with your team: Communication is key when using Git flow in a team environment. Make sure to keep your team informed of any changes you make and any issues you encounter. Use tools like GitLab, GitHub, or Bitbucket to track and manage changes and collaborate with your team.
By following these best practices, you can ensure that your team is using Git flow effectively and efficiently, and that your codebase is well-managed and well-documented.
GitHub flow
GitHub flow is a simplified version of Git flow that is specifically designed for GitHub’s collaborative platform. It is based on the concept of “feature branching” and emphasizes continuous integration and continuous deployment.
Here are the basic steps of GitHub flow:
-
Create a branch: To add a new feature or make changes to the codebase, create a new branch off of the main branch (
masterormain). Give your branch a descriptive name that indicates the purpose of the branch. -
Add commits: Make changes to the code on your branch and commit them regularly with clear and descriptive commit messages.
-
Open a pull request: When you are ready to merge your changes back into the main branch, open a pull request. This will create a discussion thread where team members can review the code and provide feedback.
-
Discuss and review the code: Team members can review the code on the pull request and provide comments, suggestions, or requests for changes. You can continue to make changes to your branch and add new commits to address the feedback.
-
Merge the code: Once the code has been reviewed and approved by the team, you can merge the code back into the main branch. This will automatically close the pull request and add the new changes to the main branch.
-
Deploy the code: With GitHub flow, the code is deployed continuously, meaning that any changes that are merged into the main branch are immediately available for use. This allows for rapid iteration and continuous improvement.
GitHub flow is a simple and streamlined workflow that is well-suited for small teams or teams that are new to Git. However, it may not be suitable for more complex projects or teams that require more structure and control over the development process.
Understanding GitHub flow and its purpose
GitHub flow is a lightweight, branch-based workflow that is designed to simplify the process of collaborating on code changes and deploying them to production. It is specifically tailored to the GitHub platform and emphasizes continuous integration and continuous deployment.
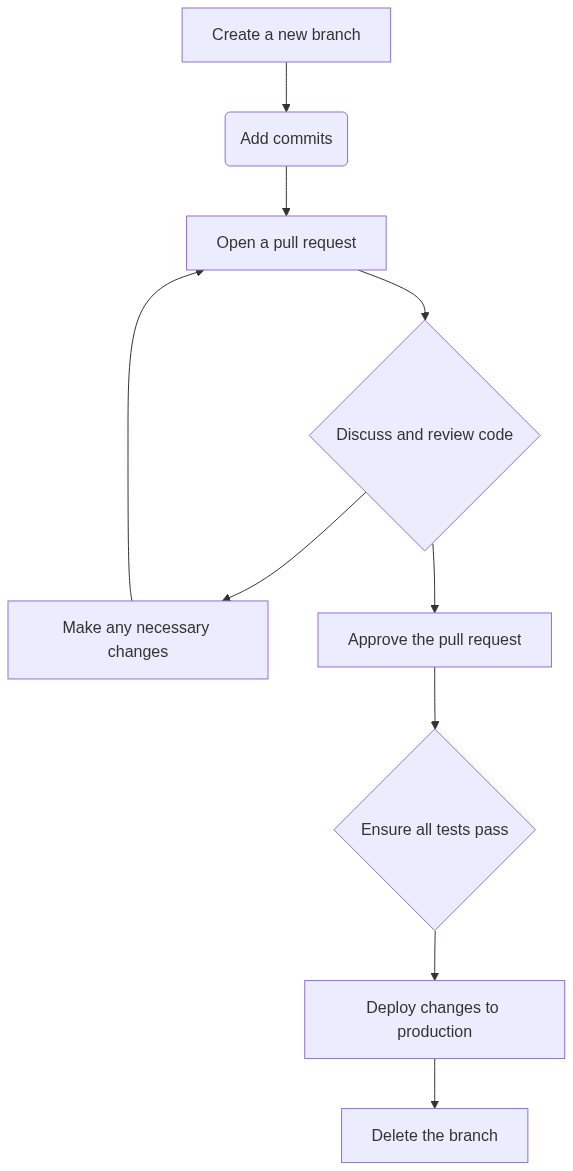
The main purpose of GitHub flow is to provide a simple and streamlined workflow that allows teams to collaborate on code changes and deploy them quickly and efficiently. By using feature branches and pull requests, team members can review each other’s code and provide feedback before merging the changes into the main branch.
GitHub flow also emphasizes continuous integration and continuous deployment, which means that changes are automatically deployed to production as soon as they are merged into the main branch. This allows teams to rapidly iterate and improve their codebase, while also ensuring that changes are thoroughly tested and reviewed before they are released.
Overall, GitHub flow is a flexible and adaptable workflow that can be used by teams of all sizes and levels of experience. It provides a simple and intuitive way to manage code changes and collaborate on code, while also ensuring that code is thoroughly reviewed and tested before it is released to production.
The basic workflow of GitHub flow, including creating a branch, making changes, creating a pull request, and merging changes
The basic workflow of GitHub flow consists of the following steps:
-
Create a branch: To start working on a new feature or bugfix, create a new branch in the repository. The branch should be based on the latest code in the main branch (
masterormain). -
Make changes: Once you have created a new branch, make your changes to the code. Commit your changes frequently with clear and concise commit messages.
-
Create a pull request: When you are ready to merge your changes into the main branch, create a pull request. This will open a discussion thread where other team members can review your code and suggest changes.
-
Discuss and review the changes: Other team members can review your code and provide feedback using the comments feature in the pull request. You can also make changes to your code in response to feedback and commit them to the same branch.
-
Merge the changes: Once the code has been reviewed and approved, merge the changes into the main branch. This will incorporate your changes into the main codebase and make them available to all users.
-
Deploy changes: With GitHub flow, changes are continuously deployed to production as soon as they are merged into the main branch. This ensures that changes are rapidly tested and reviewed, and that the codebase is always up-to-date.
By following this basic workflow, teams can work collaboratively on code changes and ensure that changes are thoroughly reviewed and tested before they are released to production. This helps to prevent errors and bugs, and ensures that the codebase remains stable and reliable over time.
How to use GitHub flow to manage software releases and feature development
To use GitHub flow to manage software releases and feature development, you can follow these general steps:
-
Create a new branch for each feature or bugfix: To start working on a new feature or bugfix, create a new branch in the repository. The branch should be based on the latest code in the main branch (
masterormain). -
Make changes and commit frequently: Once you have created a new branch, make your changes to the code. Commit your changes frequently with clear and concise commit messages.
-
Open a pull request for code review: When you are ready to merge your changes into the main branch, open a pull request. This will open a discussion thread where other team members can review your code and suggest changes.
-
Merge the changes into the main branch: Once the code has been reviewed and approved, merge the changes into the main branch. This will incorporate your changes into the main codebase and make them available to all users.
-
Deploy changes to production: With GitHub flow, changes are continuously deployed to production as soon as they are merged into the main branch. This ensures that changes are rapidly tested and reviewed, and that the codebase is always up-to-date.
-
Tag releases for version control: To keep track of software releases, you can use Git tags to mark specific commits as releases. This allows you to easily roll back to previous versions if necessary, and helps to maintain a clear version history.
By following these general steps, you can use GitHub flow to manage software releases and feature development in a collaborative and efficient manner. GitHub flow is particularly useful for smaller teams or projects, as it provides a simple and streamlined workflow that is easy to use and understand.
Best practices for using GitHub flow in a team environment
Here are some best practices for using GitHub flow in a team environment:
-
Create small, focused pull requests: To make the review process easier and faster, it’s best to keep your pull requests small and focused. Each pull request should contain changes related to a specific feature or bugfix, rather than multiple unrelated changes.
-
Review each other’s code: Code reviews are an important part of GitHub flow. Be sure to review your team members’ code thoroughly and provide constructive feedback. This will help to catch any errors or issues before they are merged into the main branch.
-
Use GitHub’s built-in tools: GitHub provides several built-in tools to help with code reviews, such as inline comments and review requests. Be sure to use these tools to their fullest extent to make the review process more efficient and effective.
-
Automate testing and deployment: To ensure that changes are thoroughly tested and deployed quickly, it’s best to automate as much of the testing and deployment process as possible. Use tools such as continuous integration (CI) and continuous deployment (CD) to automate these tasks.
-
Use Git tags for version control: To keep track of software releases, use Git tags to mark specific commits as releases. This allows you to easily roll back to previous versions if necessary, and helps to maintain a clear version history.
-
Communicate regularly: Communication is key in any team environment. Be sure to communicate regularly with your team members to ensure that everyone is on the same page and aware of any changes or issues.
By following these best practices, you can use GitHub flow to manage code changes and releases effectively in a team environment. This will help to ensure that your codebase remains stable and reliable over time, while also allowing your team to collaborate more efficiently and effectively.
GitLab flow
GitLab flow is a workflow that is based on GitLab’s built-in features and capabilities, and is similar to GitHub flow in many respects. However, there are a few key differences that make GitLab flow unique.
The basic workflow of GitLab flow includes the following steps:
-
Create a branch for each feature or bugfix: Similar to GitHub flow, each new feature or bugfix should be developed in its own branch. This helps to keep the codebase organized and makes it easier to track changes.
-
Make changes and commit frequently: Once you have created a new branch, make your changes to the code. Commit your changes frequently with clear and concise commit messages.
-
Open a merge request for code review: In GitLab, the equivalent of a pull request is called a merge request. When you are ready to merge your changes into the main branch, open a merge request. This will open a discussion thread where other team members can review your code and suggest changes.
-
Merge the changes into the main branch: Once the code has been reviewed and approved, merge the changes into the main branch. This will incorporate your changes into the main codebase and make them available to all users.
-
Run automated tests and deploy to production: GitLab provides built-in tools for continuous integration (CI) and continuous deployment (CD). These tools can be used to automate the testing and deployment process, making it faster and more reliable.
-
Tag releases for version control: To keep track of software releases, you can use Git tags to mark specific commits as releases. This allows you to easily roll back to previous versions if necessary, and helps to maintain a clear version history.
Some best practices for using GitLab flow in a team environment include:
-
Use GitLab’s built-in tools: GitLab provides a wide range of built-in tools for code review, testing, and deployment. Be sure to use these tools to their fullest extent to make the development process more efficient and effective.
-
Create a well-defined workflow: To ensure that everyone on the team understands the development process, it’s important to create a well-defined workflow that outlines each step of the process.
-
Communicate regularly: As with any team environment, communication is key. Be sure to communicate regularly with your team members to ensure that everyone is on the same page and aware of any changes or issues.
-
Use feature flags: GitLab provides feature flags, which allow you to control the visibility of new features as they are developed. This can be useful for testing and gradual rollouts.
By following these best practices, you can use GitLab flow to manage code changes and releases effectively in a team environment. This will help to ensure that your codebase remains stable and reliable over time, while also allowing your team to collaborate more efficiently and effectively.
-
Monitor performance and analytics: GitLab also offers powerful performance monitoring and analytics tools that can help you track the performance of your application over time. Use these tools to identify areas for improvement and to ensure that your code is performing as expected.
-
Encourage collaboration and feedback: One of the benefits of using GitLab flow is that it encourages collaboration and feedback among team members. Encourage your team members to review each other’s code and provide feedback, and be open to suggestions and improvements from others.
-
Document everything: To ensure that everyone on the team is on the same page, it’s important to document everything related to the development process, including workflows, processes, and coding standards. This documentation should be easily accessible and regularly updated.
-
Use issue tracking: GitLab provides a robust issue tracking system that can be used to track bugs, feature requests, and other issues. Use this system to keep track of issues and to ensure that they are resolved in a timely manner.
By following these best practices, you can use GitLab flow to manage code changes and releases effectively in a team environment. This will help you to build a stable and reliable codebase over time, while also enabling your team to work more efficiently and collaboratively.
Understanding GitLab flow and its purpose
GitLab flow is a software development workflow that is based on GitLab, a web-based Git repository manager that provides a complete set of tools for version control, code review, testing, and continuous integration and deployment. GitLab flow is designed to help development teams manage software releases and feature development in a collaborative and efficient manner.
The purpose of GitLab flow is to provide a streamlined and standardized development process that can be used by development teams of all sizes. GitLab flow provides a clear and well-defined workflow for creating, reviewing, and merging code changes, and includes built-in tools for testing, deployment, and performance monitoring.
The key benefits of using GitLab flow include:
-
Better collaboration: GitLab flow encourages collaboration among team members by providing a clear workflow for creating and reviewing code changes. This makes it easier for team members to work together and share knowledge.
-
Increased efficiency: By automating many of the tedious and time-consuming tasks involved in software development, GitLab flow helps to increase efficiency and reduce the time it takes to develop and deploy new features.
-
Improved quality: GitLab flow includes built-in tools for testing and code review, which help to ensure that the code is of high quality and that bugs are caught early in the development process.
-
Greater visibility: GitLab flow provides greater visibility into the development process by providing detailed logs and analytics that can be used to track progress, identify issues, and measure performance.
Overall, GitLab flow is a powerful and flexible workflow that can help development teams to work more collaboratively and efficiently, while also improving the quality and reliability of their software.
The basic workflow of GitLab flow, including creating a branch, making changes, creating a merge request, and merging changes
The basic workflow of GitLab flow includes the following steps:
-
Create a branch: To start working on a new feature or bug fix, create a new branch in GitLab. This branch should be based on the latest version of the main branch (usually called “master” or “main”).
-
Make changes: Make the necessary changes to the code in your branch, using your preferred code editor or integrated development environment (IDE).
-
Commit changes: Once you have made your changes, commit them to your branch using Git. Be sure to include a clear and descriptive commit message that explains what changes you made and why.
-
Create a merge request: When you are ready to merge your changes back into the main branch, create a merge request in GitLab. This request should include a description of the changes you made, as well as any relevant documentation or test cases.
-
Review changes: The merge request will be automatically assigned to one or more reviewers, who will review the changes and provide feedback. You can also request reviews from specific team members if necessary.
-
Make changes based on feedback: If the reviewers identify any issues or suggest changes, make the necessary changes to your code and commit them to your branch.
-
Merge changes: Once the reviewers approve the changes, you can merge them into the main branch. GitLab will automatically update the main branch with your changes and close the merge request.
By following these steps, you can use GitLab flow to manage code changes and releases in a collaborative and efficient manner.
How to use GitLab flow to manage software releases and feature development
To use GitLab flow to manage software releases and feature development, follow these best practices:
-
Create a project structure: Define a clear and organized project structure that reflects your development workflow. This should include separate branches for development, staging, and production, as well as any feature or bug fix branches.
-
Use milestones: Use GitLab’s milestone feature to set goals and track progress for each release cycle. This will help you stay on track and ensure that you are delivering software on schedule.
-
Use issue tracking: Use GitLab’s issue tracking feature to track bugs and feature requests. This will help you prioritize issues and ensure that you are addressing the most important issues first.
-
Use automated testing: Use GitLab’s built-in testing features to automate your testing process. This will help you catch bugs and issues early in the development process, before they become more difficult and time-consuming to fix.
-
Use continuous integration and deployment (CI/CD): Use GitLab’s CI/CD features to automate your deployment process. This will help you deliver new features and bug fixes to your users more quickly and reliably.
-
Review code: Use GitLab’s merge request feature to review code changes and ensure that all code is of high quality and follows best practices.
By following these best practices, you can use GitLab flow to manage software releases and feature development in a more streamlined and efficient manner.
Best practices for using GitLab flow in a team environment
Here are some best practices for using GitLab flow in a team environment:
-
Establish clear naming conventions for branches: Use clear and descriptive names for your branches, such as “feature/add-user-profile-page” or “bugfix/fix-404-error-page”. This will help your team members quickly understand the purpose of each branch.
-
Establish clear merge request guidelines: Establish guidelines for creating and reviewing merge requests, including guidelines for writing descriptive commit messages, updating documentation, and adding test cases. This will help ensure that all code changes are of high quality and meet your team’s standards.
-
Use labels and milestones: Use GitLab’s label and milestone features to organize and track issues and merge requests. This will help you stay on top of your development process and ensure that you are delivering software on schedule.
-
Use automated testing and deployment: Use GitLab’s built-in testing and deployment features to automate your development process. This will help you catch issues early and deliver new features and bug fixes more quickly and reliably.
-
Conduct code reviews: Conduct code reviews on all merge requests to ensure that all code changes meet your team’s standards for quality and best practices.
-
Communicate effectively: Use GitLab’s built-in communication features, such as comments and notifications, to communicate effectively with your team members. This will help ensure that everyone is on the same page and that all issues and questions are addressed in a timely manner.
By following these best practices, your team can use GitLab flow to manage code changes and releases in a collaborative and efficient manner, while ensuring that all code is of high quality and meets your team’s standards.
Other Git branching strategies
Apart from Git flow and GitHub flow, there are several other Git branching strategies that teams can use depending on their specific needs and workflows. Here are a few:
-
Trunk-Based Development: In this strategy, all changes are made directly on the main branch (usually the “master” branch). Feature flags are used to selectively enable or disable new features until they are ready for release. This strategy is best suited for teams that want to release frequently and minimize the number of branches they have to manage.
-
Feature Branching: This strategy is similar to Git flow, but with fewer branches. Each feature is developed on a separate branch, and merged back into the main branch (usually “master”) when ready. This strategy is best suited for smaller teams with a less complex development process.
-
GitLab Flow: This strategy is similar to GitHub flow, but with some additional features such as the ability to use protected branches and approvals. This strategy is best suited for teams that are already using GitLab for their development process.
-
GitOps: This strategy is an extension of DevOps that involves using Git as the single source of truth for your infrastructure and configuration. All changes to your infrastructure are made through Git branches, and automated tools are used to manage deployment and rollbacks. This strategy is best suited for teams that are using infrastructure-as-code tools like Kubernetes and Terraform.
-
Git-based Code Review: In this strategy, all code changes are made directly on the main branch, but each change is reviewed and approved before it is merged into the main branch. This strategy is best suited for smaller teams that want to keep things simple and focus on code quality.
Each of these strategies has its own strengths and weaknesses, and teams should choose the one that best fits their needs and workflows.
Feature branching
Feature branching is a popular Git branching strategy where developers create a separate branch for each feature or user story they are working on. Each feature branch contains code changes specific to that feature, and is merged back into the main branch (usually “master” or “develop”) when the feature is completed.
Here are the basic steps involved in feature branching:
-
Create a new branch: Create a new branch for the feature you are working on. The branch name should be descriptive and indicate the feature you are implementing.
-
Make changes: Make the necessary code changes on the feature branch.
-
Test your changes: Test your changes locally to ensure they work as expected.
-
Push your branch: Push your branch to the remote repository so that other team members can access it.
-
Create a pull request: When you have completed the feature, create a pull request to merge the changes back into the main branch.
-
Review and merge: Review the changes in the pull request and merge them into the main branch if they meet your team’s quality standards.
-
Clean up: Once the feature branch has been merged, delete the branch to keep your repository clean and tidy.
Feature branching is a flexible strategy that can be adapted to different workflows and team sizes. It allows developers to work independently on different features without interfering with each other’s code, and promotes code quality by allowing for thorough testing and code reviews before merging changes into the main branch.
Trunk-based development
Trunk-based development is a Git branching strategy where developers make all changes directly on the main branch (usually “master” or “trunk”) instead of creating feature branches. This approach encourages developers to commit small, frequent changes to the main branch, and to use feature toggles to selectively enable or disable new features until they are ready for release.
Here are some of the key characteristics of trunk-based development:
-
Continuous Integration: Trunk-based development relies heavily on continuous integration (CI) practices to ensure that changes are integrated and tested frequently.
-
Small, frequent commits: Developers are encouraged to make small, frequent commits to the main branch to reduce the risk of merge conflicts and to make it easier to identify and fix issues.
-
Feature toggles: Instead of creating separate feature branches, developers use feature toggles to selectively enable or disable new features until they are ready for release. This allows teams to test features in production without impacting end-users.
-
Code reviews: Code reviews are still an important part of trunk-based development to ensure that changes are reviewed and approved by other team members before they are merged into the main branch.
Trunk-based development is best suited for teams that want to release frequently and minimize the number of branches they have to manage. It can be particularly effective for smaller teams or projects where the development process is relatively simple. However, it may not be as effective for larger teams or more complex projects where multiple features are being developed simultaneously.
Release branching
Release branching is a Git branching strategy where developers create a new branch specifically for the purpose of preparing a release. This branch is typically named after the release version number (e.g., “release-1.0”) and is created from the main branch (usually “master” or “develop”) when the release is ready to be tested and prepared for deployment.
Here are the basic steps involved in release branching:
-
Create a new branch: Create a new branch for the release and give it a descriptive name that indicates the version number.
-
Freeze the code: Once the release branch has been created, freeze the code to prevent further changes from being made until the release is complete. This helps to ensure that the release is stable and consistent.
-
Test the release: Test the release branch to ensure that it meets the necessary quality standards and is ready for deployment.
-
Bug fixing: If any bugs are discovered during testing, they can be fixed on the release branch and merged back into the main branch.
-
Release deployment: Once the release has been tested and approved, it can be deployed to the production environment.
-
Merge back: Once the release is complete, the release branch can be merged back into the main branch to incorporate any bug fixes or improvements that were made during the release process.
Release branching is a useful strategy for managing the release process and ensuring that code changes are properly tested and validated before being deployed. It can also help to keep the main branch clean and stable by allowing for the creation of a separate branch for release-specific changes. However, it can also be complex to manage and requires careful coordination between developers and release managers.
Pros and cons of each strategy and how to choose the right one for your project and team
Each Git branching strategy has its own set of pros and cons, and the right choice depends on your project’s needs and the characteristics of your team. Here are some factors to consider when choosing a branching strategy:
-
Project complexity: If your project is complex and involves many features and changes, a branching strategy that allows for separate feature branches (such as Git flow) may be more appropriate.
-
Team size: If you have a larger team, a branching strategy that allows for separate feature branches may also be more effective for managing multiple developers working on different features simultaneously.
-
Release frequency: If your project requires frequent releases, a branching strategy that allows for continuous integration (such as Trunk-based development) may be more effective for minimizing the time required to merge and test changes.
-
Quality control: If your project requires rigorous quality control and testing, a branching strategy that involves a separate release branch (such as Release branching) may be more effective for ensuring that code changes are properly validated before being deployed.
Here are some of the pros and cons of each strategy:
- Git flow
- Pros: Separation of features into their own branches can make it easier to manage multiple developers and features simultaneously. Clear separation of code into main, develop, and feature branches.
- Cons: Can be complex to manage, especially for smaller projects with simpler development requirements.
- GitHub flow
- Pros: Simple and streamlined workflow, easy to manage for smaller teams or projects. Allows for quick iterations and frequent releases.
- Cons: May not be as effective for larger teams or more complex projects with multiple features being developed simultaneously.
- GitLab flow
- Pros: Provides a balance between the simplicity of GitHub flow and the complexity of Git flow. Allows for flexible management of multiple features and release branches.
- Cons: May be more complex to manage than GitHub flow for smaller teams or simpler projects.
- Trunk-based development
- Pros: Simple and streamlined workflow that encourages frequent commits and continuous integration. Reduces the risk of merge conflicts and simplifies code management.
- Cons: May not be as effective for complex projects with multiple features being developed simultaneously.
- Release branching
- Pros: Provides a clear separation between code that is being prepared for release and code that is still in development. Allows for rigorous quality control and testing.
- Cons: Can be complex to manage, especially for larger projects with many developers and features being developed simultaneously.
Ultimately, the right Git branching strategy for your project and team will depend on your specific requirements and development workflow. It may be helpful to experiment with different strategies and workflows to determine which approach works best for your team.
It’s also important to note that different strategies can be combined to create a custom approach that meets your specific needs. For example, a team may use a combination of Git flow and Trunk-based development to manage feature development and continuous integration. Alternatively, a team may use GitHub flow for smaller projects and Git flow for larger, more complex projects.
Whichever strategy you choose, it’s important to establish clear guidelines and best practices for your team to follow. This includes establishing naming conventions for branches, defining when and how often to merge changes, and establishing standards for code review and testing.
Regular communication and collaboration within the team is also essential for successful implementation of any Git branching strategy. This includes regular stand-up meetings to discuss progress and identify any roadblocks, as well as continuous feedback and code review to ensure that all code changes meet the team’s quality standards.
In conclusion, choosing the right Git branching strategy requires careful consideration of your project’s needs, team size, and development workflow. By experimenting with different strategies and workflows, establishing clear guidelines and best practices, and fostering regular communication and collaboration within the team, you can create an effective Git branching strategy that supports your team’s goals and objectives.
Git branching best practices
Here are some best practices for Git branching that can help your team manage code changes and collaborate effectively:
-
Keep your branching strategy simple: Choose a branching strategy that is simple and easy to understand. Complex branching strategies can lead to confusion, mistakes, and wasted time.
-
Use descriptive branch names: Use descriptive branch names that reflect the purpose of the branch. This can make it easier to identify branches, track changes, and manage merge conflicts.
-
Keep branches short-lived: Create branches for specific features or bug fixes, and merge them back into the main branch as soon as possible. This can help minimize merge conflicts and make it easier to track changes.
-
Use pull requests for code review: Use pull requests to facilitate code review and collaboration. This can help catch errors and improve code quality, while also promoting collaboration and knowledge sharing within the team.
-
Review code thoroughly: Conduct thorough code reviews to ensure that all code changes meet the team’s quality standards. This can help prevent bugs, improve code readability, and promote best practices.
-
Use automation to simplify workflows: Use automation tools to simplify common workflows, such as running tests, building code, and deploying changes. This can help reduce manual errors and save time.
-
Communicate frequently and openly: Encourage open communication and collaboration within the team. This can help ensure that everyone is on the same page, and can help identify and address issues more quickly.
By following these best practices, your team can create a more effective and efficient Git branching workflow that supports collaboration and code quality.
Naming conventions for branches
Using consistent and descriptive names for branches can help you and your team keep track of code changes and make it easier to identify the purpose of each branch. Here are some common naming conventions for branches:
-
Feature branches: Use a prefix such as “feature/” followed by a brief description of the feature. For example, “feature/login-page” or “feature/payment-processing”.
-
Bug fix branches: Use a prefix such as “bugfix/” followed by a brief description of the bug. For example, “bugfix/404-error-page” or “bugfix/payment-processing-error”.
-
Hotfix branches: Use a prefix such as “hotfix/” followed by a brief description of the issue. For example, “hotfix/security-vulnerability” or “hotfix/payment-processing-bug”.
-
Release branches: Use a prefix such as “release/” followed by the version number. For example, “release/1.0” or “release/2.1.4”.
-
Main branch: Use a branch name such as “main”, “master”, or “trunk” for the main development branch.
-
Development branch: Use a branch name such as “develop” or “dev” for the branch where all feature branches are merged.
It’s important to establish clear naming conventions for branches and ensure that all team members follow them consistently. This can help reduce confusion and make it easier to track changes and manage merge conflicts.
Merging vs. rebasing
Merging and rebasing are two different ways of integrating changes from one branch into another.
Merging combines changes from one branch into another by creating a new commit that has two parent commits, one from the source branch and one from the target branch. This creates a “merge commit” that includes all the changes from both branches. Merging is a simple and safe way to integrate changes, and it preserves the entire history of both branches.
Rebasing, on the other hand, rewrites the commit history of a branch by moving all the changes from one branch onto another. It essentially replays the changes from the source branch on top of the target branch, creating a linear history. Rebasing can make the history of a project cleaner and easier to understand, but it can be risky if not done properly, as it can rewrite commit history and potentially cause conflicts.
Choosing between merging and rebasing depends on the situation and the preferences of the team. Here are some general guidelines:
- Use merging when working on public branches (like main or develop) or when collaborating with other team members on a shared branch.
- Use rebasing when working on private feature branches or when working on a branch that you don’t plan to share with others.
- Use caution when rebasing, as it can rewrite commit history and potentially cause conflicts if not done properly.
Ultimately, the best practice is to discuss with your team and establish a consistent approach to merging and rebasing that works for your project and workflow.
Branch management and cleanup
Good branch management is important to keep your Git repository organized and avoid clutter. Here are some best practices for branch management and cleanup:
-
Delete merged branches: Once a branch has been merged into the target branch (like main or develop), it is safe to delete the source branch to keep the repository clean. You can do this manually or use automation tools to delete branches automatically once they are merged.
-
Use descriptive names: Use clear and descriptive names for your branches to make it easy to understand their purpose and avoid confusion. For example, use feature/ for feature branches, bugfix/ for bug fix branches, and release/ for release branches.
-
Use prefixes: Use prefixes to group related branches and make it easy to distinguish between different types of branches. For example, you could use feature/ for feature branches, hotfix/ for urgent bug fixes, and release/ for release branches.
-
Limit the number of open branches: Avoid having too many open branches at the same time to prevent confusion and make it easier to manage the repository. Encourage team members to finish their work on a branch and merge it as soon as possible.
-
Regularly clean up your repository: Regularly review and clean up your repository to remove unnecessary branches and keep the repository organized. Set up a schedule to periodically review and delete merged branches.
By following these best practices, you can keep your Git repository organized and avoid clutter, making it easier for you and your team to collaborate and maintain the codebase over time.
Best practices for working with remote branches
Working with remote branches can be challenging, especially in a team environment where multiple developers are collaborating on a project. Here are some best practices to help you work effectively with remote branches:
-
Keep your local repository up-to-date: Before you start working on a new branch, make sure to pull the latest changes from the remote repository. This ensures that your local repository is up-to-date and avoids conflicts when you try to merge your changes back into the remote repository.
-
Use descriptive names: Use descriptive names for your remote branches that clearly indicate their purpose and make it easy for other team members to understand their function.
-
Use feature flags: When working on a new feature or change that is not yet ready for production, use feature flags to isolate the changes from the rest of the codebase. This makes it easier to test and deploy the changes without affecting other parts of the application.
-
Use pull requests: When you’re ready to merge your changes back into the main codebase, use pull requests to review and approve the changes before merging them into the remote repository. This allows other team members to review and provide feedback on the changes, ensuring that they meet the project’s quality standards.
-
Delete merged branches: Once a remote branch has been merged into the main codebase, it is safe to delete it to avoid clutter and confusion. You can do this manually or use automation tools to delete merged branches automatically.
By following these best practices, you can work effectively with remote branches and collaborate with other team members on a project.
Strategies for avoiding merge conflicts and minimizing risks
Merge conflicts can be frustrating and time-consuming, and can lead to delays in project delivery. Here are some strategies for avoiding merge conflicts and minimizing risks:
-
Use small, focused commits: Instead of making large, sweeping changes in a single commit, break your changes into smaller, focused commits. This makes it easier to review and merge changes, and reduces the likelihood of conflicts.
-
Communicate with team members: If you’re working on a shared codebase, it’s important to communicate with other team members about the changes you’re making. This can help avoid conflicts and ensure that everyone is on the same page.
-
Use feature flags: Feature flags are a great way to isolate changes from the rest of the codebase, making it easier to test and deploy changes without affecting other parts of the application.
-
Use branching strategies: Git branching strategies, such as GitFlow or GitHub Flow, can help minimize conflicts by providing clear guidelines for how changes should be made and merged.
-
Run automated tests: Automated tests can help catch conflicts and other issues early on, before they become bigger problems. Make sure to run tests regularly and integrate them into your development workflow.
-
Use code review: Code review is an important part of the development process, as it helps catch issues before they are merged into the main codebase. Make sure to review code thoroughly and provide feedback to team members.
By following these strategies, you can minimize the risk of merge conflicts and ensure that your development process runs smoothly.
Chapter 6: Git Hooks
What are Git hooks and why are they useful?
Git hooks are scripts that are triggered by specific actions in Git, such as committing or merging code. These scripts can be used to perform a wide range of tasks, such as running tests, enforcing code quality standards, and notifying team members about changes.
Git hooks are useful for a number of reasons:
-
Automation: Git hooks allow you to automate repetitive tasks, such as running tests or performing code analysis, without requiring manual intervention.
-
Consistency: By enforcing code quality standards through Git hooks, you can ensure that all code that is committed to the repository meets the same standards, regardless of who is committing the code.
-
Collaboration: Git hooks can be used to notify team members about changes or to enforce team-specific policies, such as requiring code reviews or approvals before changes can be merged.
-
Security: Git hooks can be used to enforce security policies, such as ensuring that all code is signed or encrypted before being committed to the repository.
Overall, Git hooks are a powerful tool that can help streamline the development process, improve code quality, and enhance collaboration and security.
Understanding Git hooks and how they can automate tasks and enforce standards in your Git workflow
Git hooks are scripts that are triggered automatically by specific Git events, such as committing, pushing, or merging code. They are a powerful tool for automating tasks and enforcing standards in your Git workflow.
There are two types of Git hooks: client-side and server-side. Client-side hooks run on the local Git client, while server-side hooks run on the Git server.
Some examples of tasks that can be automated using Git hooks include:
-
Running automated tests: You can configure a pre-commit hook to run automated tests on your code before it is committed to the repository. This ensures that the code is functional and meets the required standards.
-
Enforcing code quality standards: You can use a pre-commit hook to enforce code quality standards, such as code formatting or syntax rules. This ensures that all code in the repository is consistent and readable.
-
Enforcing security policies: You can use a pre-commit hook to enforce security policies, such as ensuring that code is signed or encrypted before it is committed to the repository. This helps to protect sensitive data and ensure that the code is secure.
-
Notifying team members about changes: You can use a post-commit hook to notify team members about changes to the repository, such as sending an email or message to a chat channel. This helps to keep everyone up-to-date and ensures that team members are aware of important changes.
By using Git hooks to automate tasks and enforce standards, you can ensure that your Git workflow is efficient, consistent, and high-quality.
Benefits of using Git hooks for code quality, security, and productivity
Using Git hooks can bring many benefits to your team’s workflow, including improvements in code quality, security, and productivity. Here are some specific benefits:
-
Code quality: Git hooks can help enforce code quality standards by automatically checking code formatting, syntax rules, and other quality criteria. This ensures that all code in the repository is consistent and readable, which can reduce errors and improve maintainability.
-
Security: Git hooks can help enforce security policies, such as ensuring that code is signed or encrypted before it is committed to the repository. This helps to protect sensitive data and ensure that the code is secure. For example, you can use a pre-commit hook to scan code for security vulnerabilities, ensuring that these are caught early and not introduced into the codebase.
-
Productivity: Git hooks can automate repetitive tasks, such as running tests or generating documentation, freeing up time for developers to focus on more valuable tasks. This can improve productivity and reduce the risk of human error.
-
Standardization: Git hooks can help enforce standardized practices, such as commit message format or code review requirements. This ensures that all team members follow the same practices and reduces the risk of inconsistencies or mistakes.
-
Communication: Git hooks can help keep team members informed about changes to the repository, such as sending notifications or alerts. This ensures that everyone is up-to-date and can respond quickly to important changes.
Overall, using Git hooks can bring many benefits to your team’s workflow, making it more efficient, secure, and productive.
Types of Git hooks
There are two types of Git hooks: client-side hooks and server-side hooks.
-
Client-side hooks: These hooks run on the local client machine where the developer is working. They are triggered by specific Git actions such as committing changes, merging branches, or checking out a branch. Examples of client-side hooks include pre-commit, pre-push, and post-checkout.
-
Server-side hooks: These hooks run on the Git server and are triggered by actions such as receiving a push or accepting a pull request. Examples of server-side hooks include pre-receive, post-receive, and update.
Git comes with a set of pre-configured hook templates that can be customized to suit your team’s specific requirements. Some common use cases for hooks include running automated tests, validating code formatting, checking for security vulnerabilities, and enforcing commit message standards.
Hooks can be written in any programming language, making them highly flexible and customizable. When a hook is triggered, it executes a script or program defined by the user, allowing you to automate various tasks and enforce standards within your team’s Git workflow.
Pre-commit hooks
Pre-commit hooks are a type of client-side Git hook that run before a developer’s changes are committed to the repository. These hooks can be used to automate tasks such as linting, code formatting, and running tests.
By using pre-commit hooks, teams can ensure that all code committed to the repository meets certain quality and formatting standards. This can help to prevent common errors and issues from being introduced into the codebase, and can improve the overall maintainability of the code.
Examples of pre-commit hooks include:
-
Linting: A pre-commit hook can be used to automatically run a linter on the code changes to check for syntax errors, code style violations, and other issues.
-
Code formatting: A pre-commit hook can be used to automatically format the code changes according to a specific style guide or formatting convention.
-
Running tests: A pre-commit hook can be used to automatically run a suite of tests on the code changes to ensure that they do not introduce any new bugs or regressions.
By using pre-commit hooks in conjunction with a code review process, teams can ensure that all code changes are thoroughly reviewed and validated before being committed to the repository, which can help to reduce the risk of bugs and improve overall code quality.
Pre-push hooks
Pre-push hooks are a type of client-side Git hook that run before the developer’s changes are pushed to a remote repository. These hooks can be used to enforce rules or policies that must be met before the code can be pushed to the remote repository.
By using pre-push hooks, teams can ensure that all code pushed to the repository meets certain quality and formatting standards. This can help prevent common errors and issues from being introduced into the codebase, and can improve the overall maintainability of the code.
Examples of pre-push hooks include:
-
Running unit tests: A pre-push hook can be used to automatically run a suite of unit tests on the code changes to ensure that they do not introduce any new bugs or regressions.
-
Checking code coverage: A pre-push hook can be used to ensure that the code changes meet a certain level of code coverage, as defined by the team’s standards.
-
Verifying security checks: A pre-push hook can be used to verify that the code changes meet certain security requirements, such as checking for the use of unsafe functions or identifying potential vulnerabilities.
By using pre-push hooks in conjunction with a code review process, teams can ensure that all code changes are thoroughly validated before being pushed to the remote repository. This can help to reduce the risk of bugs and improve overall code quality, while also promoting good coding practices and improving team collaboration.
Post-commit hooks
Post-commit hooks are a type of Git hook that runs on the client-side after a commit has been made. They can be used to automate tasks or enforce rules that need to be applied after a commit has been made.
Some examples of tasks that can be automated using post-commit hooks include:
-
Triggering a build or deployment process: A post-commit hook can be used to automatically trigger a build or deployment process after a commit has been made. This can help to streamline the development process and reduce the amount of manual intervention required.
-
Sending notifications: A post-commit hook can be used to send notifications to team members or stakeholders after a commit has been made. This can help to keep everyone informed of the progress of the project and ensure that everyone is up-to-date with the latest changes.
-
Running code analysis tools: A post-commit hook can be used to automatically run code analysis tools, such as linters or static analysis tools, to identify potential issues with the code.
By using post-commit hooks, teams can automate routine tasks and ensure that all required rules and policies are enforced. This can help to reduce the amount of manual work required by developers, improve the overall quality of the codebase, and increase team productivity.
Post-merge hooks
Post-merge hooks are a type of Git hook that runs on the client-side after a merge has been completed. They are useful for automating tasks that need to be performed after a merge has taken place, such as updating documentation or running tests.
Some examples of tasks that can be automated using post-merge hooks include:
-
Updating documentation: A post-merge hook can be used to automatically update documentation after a merge has taken place. This can help to ensure that the documentation is always up-to-date and accurate.
-
Running tests: A post-merge hook can be used to automatically run tests after a merge has taken place. This can help to ensure that the codebase is functioning as expected after the merge.
-
Cleaning up temporary files: A post-merge hook can be used to automatically clean up temporary files that were created during the merge process.
By using post-merge hooks, teams can ensure that all necessary tasks are automatically performed after a merge has taken place. This can help to reduce the amount of manual work required by developers, ensure that the codebase is always up-to-date and functional, and increase team productivity.
Pre-receive hooks
Pre-receive hooks are a type of Git hook that runs on the server-side before the Git repository accepts a push from a client. Pre-receive hooks are used to enforce business rules or policies, ensure code quality, or perform additional checks on incoming code changes before they are accepted into the repository.
Some examples of tasks that can be performed using pre-receive hooks include:
-
Enforcing code formatting: Pre-receive hooks can check the formatting of incoming code changes and reject any that do not conform to the team’s coding standards.
-
Running security checks: Pre-receive hooks can scan incoming code changes for known security vulnerabilities and reject any that are found.
-
Enforcing branch protection: Pre-receive hooks can prevent users from pushing directly to protected branches, ensuring that changes are only made through a pull request process.
-
Running automated tests: Pre-receive hooks can run automated tests on incoming code changes and reject any that fail the tests.
By using pre-receive hooks, teams can ensure that incoming code changes conform to their standards and policies, reduce the risk of security vulnerabilities, and catch issues early in the development process.
Post-receive hooks
Post-receive hooks are a type of Git hook that runs on the server-side after the Git repository has accepted a push from a client. Post-receive hooks can be used to perform a variety of tasks, such as triggering automated deployment processes, sending notifications, or updating external systems.
Some examples of tasks that can be performed using post-receive hooks include:
-
Triggering automated deployment: Post-receive hooks can be used to trigger an automated deployment process that deploys the changes to a production environment.
-
Sending notifications: Post-receive hooks can be used to send notifications to team members or external systems, such as a chat system or issue tracker, to notify them of new changes.
-
Updating external systems: Post-receive hooks can be used to update external systems, such as a database or API, with the new changes.
By using post-receive hooks, teams can automate many of the tasks involved in deploying changes and communicating them to team members and external systems. This can help improve productivity, reduce the risk of errors, and ensure that everyone is informed about new changes.
Understanding the purpose and functionality of each hook type
Sure! Here’s a brief overview of the different types of Git hooks, their purpose, and functionality:
-
Pre-commit hooks: These hooks are run before a commit is made, and are used to enforce standards and conventions in the codebase. For example, you could use a pre-commit hook to check for trailing whitespace, enforce a consistent coding style, or check for the presence of security vulnerabilities.
-
Pre-push hooks: These hooks are run before a push is made, and are used to prevent potentially problematic changes from being pushed to the remote repository. For example, you could use a pre-push hook to check that all tests are passing, or to prevent the pushing of large binary files.
-
Post-commit hooks: These hooks are run after a commit is made, and are used to perform tasks that are related to the commit itself. For example, you could use a post-commit hook to send a notification to team members that a new commit has been made.
-
Post-merge hooks: These hooks are run after a merge has been completed, and are used to perform tasks related to the merge. For example, you could use a post-merge hook to update documentation or to trigger an automated build.
-
Pre-receive hooks: These hooks are run on the server before a push is accepted, and are used to enforce server-side policies. For example, you could use a pre-receive hook to enforce access control, or to prevent the pushing of changes to certain branches.
-
Post-receive hooks: These hooks are run on the server after a push is accepted, and are used to perform tasks related to the push. For example, you could use a post-receive hook to trigger an automated deployment process or to update an external system.
By using hooks, teams can automate many of the tasks involved in managing a Git repository, improve code quality and security, and enforce best practices and standards across the team.
Creating custom Git hooks
To create a custom Git hook, you need to first create an executable script with the appropriate code and place it in the .git/hooks directory of your Git repository. The script should be named after the specific Git hook you want it to run for (e.g., pre-commit, pre-push, etc.) and should have executable permissions.
Once you have created the script, Git will automatically run it when the corresponding Git event occurs. You can use any programming language to write your custom Git hooks, but shell scripts are the most common choice.
Here is an example of a simple pre-commit hook script that checks for whitespace errors and rejects commits that contain them:
#!/bin/sh
#
# Check for whitespace errors before committing
if git rev-parse --verify HEAD >/dev/null 2>&1; then
against=HEAD
else
# Initial commit: diff against an empty tree object
against=$(git hash-object -t tree /dev/null)
fi
# Check for whitespace errors
if ! git diff-index --check --cached $against; then
echo "Pre-commit hook failed: whitespace errors detected. Please fix and try again." >&2
exit 1
fiThis script uses the git diff-index command to check for whitespace errors in the changes being committed. If any errors are found, the hook exits with an error message.
You can customize this script to perform any other checks or tasks you want to run before committing changes to your Git repository. Just remember to make sure the script is executable and named appropriately for the Git hook you want it to run for.
How to write and test custom Git hooks using different programming languages such as bash, Python, Ruby, and more
Git hooks can be written in any programming language, but some languages like bash, Python, and Ruby are commonly used for this purpose. Here’s a general overview of how to write and test custom Git hooks using these languages:
Bash
Bash is a popular language for writing Git hooks because it is available by default on most systems. Here’s an example of a pre-commit hook written in bash that checks for trailing whitespace:
#!/bin/bash
# Remove trailing whitespace from staged files
for file in $(git diff --name-only --cached); do
sed -i 's/[[:space:]]*$//' "$file"
doneTo use this hook, save it as .git/hooks/pre-commit in your repository, and make it executable by running chmod +x .git/hooks/pre-commit.
Python
Python is a versatile language that can be used to write complex Git hooks. Here’s an example of a pre-commit hook written in Python that checks for PEP 8 compliance:
#!/usr/bin/env python
import os
import subprocess
# Check for PEP 8 compliance on staged files
for file in subprocess.check_output(['git', 'diff', '--name-only', '--cached']).splitlines():
if os.path.splitext(file)[1] == '.py':
subprocess.check_call(['pep8', file])To use this hook, save it as .git/hooks/pre-commit in your repository, and make it executable by running chmod +x .git/hooks/pre-commit.
Ruby
Ruby is a powerful language that is well-suited for writing Git hooks. Here’s an example of a pre-commit hook written in Ruby that checks for syntax errors:
#!/usr/bin/env ruby
# Check for syntax errors on staged files
`git diff --name-only --cached`.split("\n").each do |file|
if File.extname(file) == '.rb'
output = `ruby -c "#{file}" 2>&1`
unless output =~ /Syntax OK/
puts "Error in #{file}: #{output}"
exit 1
end
end
endTo use this hook, save it as .git/hooks/pre-commit in your repository, and make it executable by running chmod +x .git/hooks/pre-commit.
Testing Git hooks
Once you’ve written a Git hook, it’s important to test it thoroughly to ensure that it works as expected. To do this, you can create a test repository and add a sample file with the appropriate content to test the hook.
For example, to test the pre-commit hook that checks for trailing whitespace, you could create a test repository and add a file with trailing whitespace to the staging area. Then, you can run git commit to trigger the hook and verify that the whitespace is removed.
Similarly, you can test the other Git hooks you’ve written by creating appropriate test cases and running the Git commands that will trigger the hooks. This will help you catch any issues or bugs in the hooks before they cause problems in your production environment.
It’s important to test your custom Git hooks thoroughly to ensure they function as intended and don’t introduce any unintended consequences. One way to test your hooks is to create a mock repository and simulate different scenarios to see how your hooks respond.
You can also use Git’s built-in hook management system to help you test and manage your hooks. For example, you can use the git init command to create a new repository, then navigate to the .git/hooks directory to add and manage hooks.
When writing custom Git hooks, it’s also important to follow best practices for coding, such as writing clean and maintainable code, documenting your code, and ensuring your code is compatible with different platforms and environments.
In addition, you should consider the security implications of your Git hooks and ensure they don’t introduce any vulnerabilities into your Git workflow. For example, you should avoid executing untrusted code or commands within your hooks and ensure that your hooks don’t expose any sensitive information.
Overall, custom Git hooks can be a powerful tool for automating tasks and enforcing standards in your Git workflow. With careful planning, testing, and implementation, you can use Git hooks to improve code quality, security, and productivity in your development process.
Examples of useful custom Git hooks such as linting, formatting, security scanning, and more
There are many useful custom Git hooks that can be implemented to improve the quality, security, and productivity of your Git workflow. Here are a few examples:
-
Linting hooks: These hooks can be used to run static analysis tools on your code to catch syntax errors, style violations, and other issues before they are committed. For example, a pre-commit hook could be set up to run a linter such as ESLint or Pylint on your code before allowing the commit to proceed.
-
Formatting hooks: These hooks can be used to enforce consistent code formatting across your project. For example, a pre-commit hook could be set up to run a tool such as Black or Prettier to automatically format your code before allowing the commit to proceed.
-
Security scanning hooks: These hooks can be used to run security scanners on your code to detect vulnerabilities, such as outdated dependencies or insecure code practices. For example, a pre-push hook could be set up to run a tool such as Snyk or SonarQube on your code before allowing the push to proceed.
-
Commit message hooks: These hooks can be used to enforce standards for commit messages, such as requiring a certain format or including specific information. For example, a pre-commit hook could be set up to check that commit messages start with a ticket number and a brief summary of the changes.
-
Deployment hooks: These hooks can be used to automate the deployment process, such as triggering a build and deploy process whenever changes are pushed to a specific branch. For example, a post-receive hook could be set up to automatically deploy changes to a staging environment whenever changes are pushed to the develop branch.
These are just a few examples of the many custom Git hooks that can be implemented to improve your Git workflow. By automating tasks and enforcing standards, custom Git hooks can help to ensure that your code is high-quality, secure, and consistent.
Implementing Git hooks in your workflow
Implementing Git hooks in your workflow can vary depending on your team’s needs and processes. However, here are some general steps to follow:
- Choose the type of hook you want to implement based on your specific use case.
- Write the code for the hook in the appropriate programming language (e.g. bash, Python, Ruby).
- Save the hook code in the
.git/hooksdirectory of your Git repository with the appropriate file name and file permissions. Make sure to make the hook executable. - Test the hook by running it manually and verifying that it works as expected.
- Add the hook to your Git repository’s version control so that it is shared with your team.
- Communicate with your team about the new hook and its purpose, as well as any potential changes to their workflow.
- Monitor the hook’s execution and effectiveness, and make any necessary adjustments over time.
It is also important to note that Git hooks can be customized and combined to suit your team’s specific needs. For example, you can create a pre-commit hook that runs a linter, a formatter, and a security scanner all at once. This can help streamline your team’s development process and ensure that code quality and security standards are met.
How to add Git hooks to your local repository and share them with your team
To add Git hooks to your local repository, you need to create executable scripts in the .git/hooks directory. Here are the steps:
- Navigate to your local repository’s root directory in your terminal.
- Create a new file in the
.git/hooksdirectory with the name of the hook you want to create (e.g.pre-commit,post-merge, etc.). You can use any programming language for your hook, but it needs to be executable (e.g.chmod +x pre-commit). - Add your custom code to the script to perform the desired action(s). You can use any tool or framework you prefer in your script, as long as it is installed on your local machine.
- Save the script and exit the editor.
- Make the script executable by running
chmod +x .git/hooks/<hook-name>. - Test the hook by performing an action that triggers it (e.g. committing changes, pushing changes, merging branches, etc.).
To share your Git hooks with your team, you can add them to your project’s version control system (e.g. GitLab, GitHub, Bitbucket) and ask your team members to clone the repository. Alternatively, you can provide instructions on how to manually copy the hook scripts to their local .git/hooks directory.
It’s important to note that Git hooks are not automatically shared with others when you push your changes to a remote repository. Each developer must set up the hooks on their local machine to use them.
Best practices for using Git hooks in a team environment
Here are some best practices for using Git hooks in a team environment:
-
Define a clear and concise policy for Git hooks: It is essential to define a policy that outlines the specific hooks to be used, when they should be used, and how they should be implemented. The policy should be clear, concise, and easily understandable by all members of the team.
-
Store hooks in version control: To ensure consistency across team members, it is essential to store hooks in version control, so they are available to everyone on the team. This also ensures that the hooks are versioned and can be rolled back if needed.
-
Test hooks before deployment: Before deploying hooks, it is crucial to test them thoroughly in a staging or development environment. This helps to identify any issues or bugs that may arise before they cause problems in the production environment.
-
Provide clear error messages: Hooks should provide clear error messages to help team members understand what went wrong and how to fix it. This can help prevent frustration and delays caused by unclear error messages.
-
Document hooks: It is essential to document the hooks used in the project and how they work, including any configuration options. This documentation can help new team members quickly understand how the hooks are used in the project and how to use them correctly.
-
Regularly review and update hooks: As the project evolves, it is important to regularly review and update the hooks used in the project. This ensures that the hooks remain relevant and continue to meet the needs of the team and the project.
By following these best practices, you can ensure that Git hooks are used effectively in a team environment to improve code quality, security, and productivity.
Strategies for managing and maintaining Git hooks over time
Managing and maintaining Git hooks over time can be crucial for ensuring their continued effectiveness and usefulness. Here are some strategies for doing so:
-
Version control: Store your Git hooks in version control alongside your code. This allows you to track changes over time and revert to previous versions if necessary.
-
Documentation: Document your Git hooks to make it easier for new team members to understand how they work and how to contribute to them. This can include a README file or inline comments in the code.
-
Automated testing: Set up automated testing for your Git hooks to ensure they work as intended. This can include unit tests or integration tests that run as part of your continuous integration (CI) process.
-
Regular maintenance: Schedule regular maintenance to ensure that your Git hooks continue to work as expected. This can include updating dependencies, testing against new versions of Git, and making updates to reflect changes in your team’s workflow.
-
Code reviews: Require code reviews for any changes to your Git hooks to ensure that they meet your team’s standards and best practices.
By following these strategies, you can ensure that your Git hooks remain an effective tool for improving code quality, security, and productivity over time.
Git hooks and Continuous Integration/Continuous Deployment (CI/CD)
Git hooks can be used in conjunction with Continuous Integration/Continuous Deployment (CI/CD) to automate the build, testing, and deployment process. CI/CD is a development approach that emphasizes automating the software delivery process by regularly building, testing, and deploying code changes.
Git hooks can be used as a part of the CI/CD pipeline to ensure that certain tasks are automatically performed before or after code changes are committed, pushed, or deployed. For example, pre-commit hooks can be used to enforce code formatting, linting, or security scanning before a commit is allowed. Pre-push hooks can be used to run tests or other checks before changes are pushed to the remote repository. Post-commit hooks can be used to trigger automated builds or notifications to team members.
By integrating Git hooks with a CI/CD pipeline, teams can ensure that code changes are thoroughly tested, validated, and reviewed before being deployed to production environments. This helps to reduce the risk of errors and vulnerabilities in production systems, while also improving the speed and efficiency of the development process.
How to integrate Git hooks into your CI/CD pipeline for automated testing, building, and deployment
Integrating Git hooks into your CI/CD pipeline can help automate your software development process by enabling continuous testing, building, and deployment. Here are the general steps to integrate Git hooks into your CI/CD pipeline:
-
Define your CI/CD pipeline: Before integrating Git hooks, you should have a well-defined CI/CD pipeline that specifies the steps and tools required to build, test, and deploy your software.
-
Create your Git hooks: Once you have defined your CI/CD pipeline, you can create the Git hooks that will help enforce your development standards and automate your workflow. You can create custom hooks or use existing ones to check for code quality, security vulnerabilities, and other issues that could affect your software’s performance.
-
Configure your CI/CD tool: Next, you will need to configure your CI/CD tool to run the appropriate Git hooks as part of the pipeline. This involves specifying the hooks to run, the order in which they should be run, and any input parameters required by the hooks.
-
Run your pipeline: Once your Git hooks are configured in your CI/CD pipeline, you can run the pipeline and monitor the output for any errors or issues that need to be addressed. Any issues that are detected by the Git hooks can be automatically flagged and reported to the development team.
-
Refine and improve your pipeline: Finally, you should continuously refine and improve your pipeline to ensure that it is running efficiently and effectively. This may involve tweaking the order of the Git hooks, adding new hooks to check for additional issues, or adjusting the input parameters of the hooks.
By integrating Git hooks into your CI/CD pipeline, you can automate many of the tasks that are typically performed manually, such as testing, building, and deploying software. This can help you catch errors and bugs early in the development process, reducing the risk of issues and delays down the road. Additionally, by enforcing development standards through Git hooks, you can ensure that your team is following best practices and producing high-quality code.
Examples of using Git hooks with popular CI/CD tools such as Jenkins, GitLab CI, Travis CI, and more
Git hooks can be integrated with various CI/CD tools to automate different tasks and enforce standards in the development process. Here are some examples of how Git hooks can be used with popular CI/CD tools:
-
Jenkins: Jenkins is an open-source automation server that can be used to automate different stages of the development process. Jenkins can be configured to run Git hooks as part of a build job, allowing you to automate tasks such as running tests, code analysis, and deployment. For example, you can create a pre-commit hook to run tests and lint code, and a pre-push hook to deploy changes to a staging environment.
-
GitLab CI: GitLab CI is a powerful CI/CD tool that integrates seamlessly with GitLab. GitLab CI supports running Git hooks as part of a build job, allowing you to automate tasks such as code formatting, linting, and security scanning. For example, you can create a pre-commit hook to check for code formatting issues, and a pre-push hook to run security scans on your code before pushing changes to the repository.
-
Travis CI: Travis CI is a popular CI/CD tool that can be used to automate different stages of the development process. Travis CI supports running Git hooks as part of a build job, allowing you to automate tasks such as running tests, building Docker images, and deploying changes. For example, you can create a pre-commit hook to run unit tests and lint code, and a post-commit hook to build Docker images and push them to a container registry.
-
CircleCI: CircleCI is a cloud-based CI/CD tool that can be used to automate different stages of the development process. CircleCI supports running Git hooks as part of a build job, allowing you to automate tasks such as code analysis, testing, and deployment. For example, you can create a pre-commit hook to check for code formatting issues and run static code analysis, and a post-commit hook to deploy changes to a production environment.
Overall, integrating Git hooks with your CI/CD pipeline can help automate different tasks and enforce standards in your development process, ensuring that your code is of high quality, secure, and ready for deployment.
Chapter 7: Git Workflows for CI/CD
Continuous integration and delivery with Git
Continuous Integration (CI) and Continuous Delivery (CD) are practices used by software development teams to ensure that code changes are thoroughly tested and delivered to production in a consistent and reliable manner. These practices are often integrated with Git workflows to automate testing, building, and deployment processes.
CI involves automatically building and testing code changes as soon as they are committed to the Git repository. This helps to catch and fix issues early on, before they can cause problems down the line. CD, on the other hand, focuses on automating the deployment of tested code changes to production environments, ensuring that new features and bug fixes are delivered quickly and reliably.
To implement CI/CD with Git, teams can use various tools and services that integrate with Git repositories, such as GitLab CI, Jenkins, CircleCI, and Travis CI. These tools allow developers to define pipelines that automatically build, test, and deploy code changes based on triggers such as commits, pull requests, or tags.
In a typical CI/CD pipeline with Git, the following steps may be involved:
-
Code changes are pushed to the Git repository.
-
A CI tool automatically checks out the code changes and runs a series of tests to ensure that the changes are functional and do not introduce any new issues.
-
If the tests pass, the CI tool may then automatically build and package the application code for deployment.
-
A CD tool may then deploy the code changes to a staging environment for further testing and validation.
-
Once the changes are validated, the CD tool may then automatically deploy the changes to production.
By implementing CI/CD with Git, teams can automate many of the manual tasks involved in software development, which helps to reduce the risk of errors and improve the speed and quality of software delivery.
Understanding the benefits and importance of using Git in continuous integration and delivery workflows
Git plays a critical role in enabling continuous integration (CI) and continuous delivery/deployment (CD) workflows. CI involves integrating code changes into a shared repository frequently and automatically building and testing the code to catch issues early in the development process. CD is the practice of automating the deployment of code changes to production environments.
Using Git in CI/CD workflows provides a number of benefits, including:
-
Faster feedback: With CI, developers can get feedback on code changes within minutes, rather than waiting days or weeks for manual testing and feedback.
-
Increased quality: Automated testing and continuous integration help catch issues early in the development process, reducing the risk of bugs and errors in production.
-
Consistent builds: Using Git in a CI/CD workflow ensures that every build is consistent and reproducible, regardless of the developer or environment.
-
Greater collaboration: Git makes it easy for developers to work together on the same codebase, even when working remotely or in different time zones.
-
Faster time-to-market: Automating the build, test, and deployment process with Git can help teams release new features and updates more quickly, improving time-to-market.
Overall, using Git in a CI/CD workflow helps teams build, test, and deploy software more quickly and with greater confidence in the quality of the code.
Exploring the basics of CI/CD and how Git can be used to streamline the process
Continuous Integration (CI) and Continuous Delivery/Deployment (CD) are software development practices that aim to improve the quality and speed of software delivery by automating the process of building, testing, and deploying code changes.
CI involves automatically building and testing code changes every time they are committed to a version control system such as Git. This allows developers to catch and fix bugs and issues early in the development cycle, before they have a chance to impact other parts of the system.
CD is the practice of automatically deploying code changes to production or staging environments as soon as they pass the CI pipeline. This reduces the time between writing code and deploying it to end-users, which can be crucial in rapidly changing industries.
Git can be used to streamline the CI/CD process in a number of ways. For example, Git can be used to trigger automated build and test processes every time code is pushed to a specific branch or repository. Git can also be used to manage code versions, allowing developers to easily roll back to a previous version in the event of an issue.
In addition, Git can be integrated with a variety of CI/CD tools and platforms, such as Jenkins, Travis CI, and GitLab CI, to automate the build, test, and deployment processes. This integration allows teams to streamline the development and delivery process, reducing the likelihood of errors and improving the speed of software delivery.
Using Git in CI/CD workflows
Git plays a critical role in continuous integration and delivery workflows, as it provides version control and a reliable way to manage changes to code and other project assets. Git allows teams to work collaboratively and efficiently, making it easier to test and deploy changes to software quickly and reliably.
Here are some ways Git is used in CI/CD workflows:
-
Version control: Git provides a robust version control system that allows teams to manage changes to their codebase over time. With Git, every change made to the codebase is tracked, and a complete history of changes is maintained. This makes it easier to revert to earlier versions of the code if necessary and ensures that all changes are documented.
-
Branching and merging: Git’s branching and merging capabilities allow teams to work on multiple versions of the codebase simultaneously. This makes it easier to develop new features and make changes to the code without disrupting the main development branch. Once changes have been thoroughly tested, they can be merged back into the main branch.
-
Automated testing: Git is often used in conjunction with automated testing tools such as Jenkins, Travis CI, and GitLab CI. These tools use Git to pull code changes and automatically run tests to ensure that changes don’t introduce new bugs or issues.
-
Continuous deployment: Git is used in continuous deployment workflows to automatically deploy changes to production environments. This ensures that code changes are deployed quickly and reliably, without introducing new bugs or issues.
Overall, Git is an essential tool in modern CI/CD workflows, helping teams to work more efficiently and reliably.
Git integration with popular CI/CD tools such as Jenkins, GitLab CI, Travis CI, and CircleCI
Git integrates with popular CI/CD tools such as Jenkins, GitLab CI, Travis CI, and CircleCI to automate the build, test, and deployment processes.
Here’s a brief overview of Git integration with each of these tools:
-
Jenkins: Jenkins is an open-source automation server that can be used for continuous integration and delivery. Git can be integrated with Jenkins using the Git Plugin, which allows you to clone Git repositories and track changes to your codebase. You can configure Jenkins to trigger builds automatically whenever changes are pushed to your Git repository.
-
GitLab CI: GitLab CI is a continuous integration and delivery tool built into GitLab. It allows you to automate the build, test, and deployment processes for your code. GitLab CI integrates with Git and automatically triggers builds whenever changes are pushed to your Git repository.
-
Travis CI: Travis CI is a popular CI/CD tool that can be used to automate the build, test, and deployment processes for your code. Git integration with Travis CI is seamless, and you can configure Travis CI to automatically build and test your code whenever changes are pushed to your Git repository.
-
CircleCI: CircleCI is a cloud-based CI/CD tool that can be used to automate the build, test, and deployment processes for your code. Git integration with CircleCI is straightforward, and you can configure CircleCI to automatically build and test your code whenever changes are pushed to your Git repository.
In general, Git can be easily integrated with CI/CD tools, which allows you to automate the entire software development lifecycle and achieve faster time-to-market for your applications.
Using Git in different stages of the CI/CD pipeline, such as build, test, deploy, and more
Git can be used in different stages of the CI/CD pipeline to improve the efficiency and effectiveness of the software development process. Here are some examples:
-
Build: Git can be used to manage the source code for the software project, which is used to build the application. By using Git, developers can easily track changes to the code and collaborate on the project. Git can also be used to manage dependencies and libraries used in the build process.
-
Test: Git can be used to version control test scripts and data used for testing. Developers can create and store test cases in Git and use them to validate the functionality of the application. Git can also be used to store the results of automated tests, allowing developers to quickly identify and fix issues.
-
Deploy: Git can be used to manage deployment scripts and configurations for different environments, such as development, staging, and production. By using Git, developers can easily track changes to the deployment process and ensure that each environment is configured correctly.
-
Release: Git can be used to manage the release process for the software project. Developers can create and store release notes in Git and use them to communicate changes to users. Git can also be used to manage the distribution of the software to different platforms and channels.
Overall, using Git in the different stages of the CI/CD pipeline can help teams collaborate more effectively, track changes to the code and configurations, and ensure that the software is released quickly and reliably.
Understanding how Git can be used in containerization and orchestration tools such as Docker and Kubernetes
Git can be used in containerization and orchestration tools such as Docker and Kubernetes to manage the application code and configuration files.
With Docker, Git can be used to manage the Dockerfile, which is a text file that contains the commands used to build a Docker image. By using Git to manage the Dockerfile, changes can be tracked, reviewed, and rolled back as needed. Additionally, Docker can be integrated with GitLab CI, Jenkins, and other CI/CD tools to automate the building and testing of Docker images.
Similarly, Git can be used in Kubernetes to manage the configuration files, which are YAML files that define the desired state of the Kubernetes resources such as pods, services, and deployments. By using Git to manage the configuration files, changes can be tracked, reviewed, and rolled back as needed. Additionally, Kubernetes can be integrated with GitLab CI, Jenkins, and other CI/CD tools to automate the deployment and scaling of Kubernetes resources.
Overall, using Git in containerization and orchestration tools can improve the efficiency, reliability, and maintainability of the deployment process.
Creating a CI/CD pipeline with Git
Creating a CI/CD pipeline with Git involves a series of steps to automate the building, testing, and deployment of your application. Here is an overview of the basic steps:
-
Version Control: Store your code in a Git repository and use branches to manage changes.
-
Build: Use a build tool such as Gradle or Maven to compile and package your code into an artifact that can be deployed.
-
Test: Run automated tests on your code to ensure it meets your quality standards. This can include unit tests, integration tests, and functional tests.
-
Code Quality: Use code analysis tools to ensure your code meets your coding standards and is maintainable.
-
Deploy: Deploy your application to a test environment for further testing or to a production environment for end-users.
-
Monitoring: Monitor your application and collect data to help you identify and resolve issues.
-
Feedback: Collect feedback from end-users and stakeholders to help you identify areas for improvement and guide future development.
There are many tools available to help you create a CI/CD pipeline with Git, including Jenkins, GitLab CI/CD, Travis CI, CircleCI, and more. These tools provide integrations with Git repositories and offer features such as automatic testing, code analysis, deployment, and monitoring. To create a pipeline, you typically configure the tool to listen for changes to your Git repository, trigger builds and tests, and deploy the application as needed.
In addition to these steps, you may also want to consider implementing automation and continuous feedback loops to further streamline your pipeline. For example, you can use tools such as Git hooks, linters, and other code quality tools to automate certain tasks and ensure code quality. You can also use monitoring tools to collect feedback from end-users and stakeholders to guide future development.
Step-by-step guide to creating a CI/CD pipeline with Git and different CI/CD tools
Here’s a general step-by-step guide to creating a CI/CD pipeline with Git:
-
Define your workflow: Determine the steps involved in your pipeline, such as building, testing, and deploying your application. Decide what triggers the pipeline, such as a commit to a specific branch or a pull request.
-
Set up your Git repository: Create a Git repository and commit your code changes to the repository.
-
Choose your CI/CD tool: Choose a CI/CD tool that best fits your needs, such as Jenkins, GitLab CI, Travis CI, CircleCI, or another option.
-
Configure your CI/CD tool: Configure your chosen tool to connect to your Git repository, and set up your pipeline according to your workflow. This may involve defining stages, specifying build and test scripts, and defining deployment targets.
-
Test your pipeline: Run your pipeline and ensure that each stage is working as expected. This will help you catch any issues or bugs early in the pipeline.
-
Deploy your application: Once your pipeline is working as expected, deploy your application to your chosen environment, such as a development, staging, or production environment.
-
Monitor and maintain your pipeline: Continuously monitor your pipeline to ensure that it is running smoothly and efficiently. Make any necessary adjustments and improvements over time to keep your pipeline up-to-date and effective.
The specific steps and configurations involved in creating a CI/CD pipeline with Git will vary depending on your needs and the tools you choose. However, this general guide can help you get started and provide a framework for building a successful pipeline.
Understanding the different components of a CI/CD pipeline such as source control, building, testing, and deployment
A CI/CD pipeline typically consists of several different components that work together to automate the process of building, testing, and deploying software. Some of the main components of a CI/CD pipeline include:
-
Source control: This is where the code for the project is stored and managed. Git is often used as the source control system in CI/CD pipelines.
-
Build server: This is the server that is responsible for building the code into executable software. Tools like Jenkins, GitLab CI, and Travis CI can be used as build servers.
-
Testing: After the code has been built, it needs to be tested to ensure that it is functioning as expected. Automated testing frameworks like Selenium or JUnit can be used to perform unit, integration, and acceptance tests.
-
Deployment: Once the code has been built and tested, it can be deployed to a production environment. Tools like Docker and Kubernetes can be used to automate the process of deploying software to different environments.
-
Monitoring: Finally, the pipeline should include monitoring tools that allow you to track the performance of the software in production, and quickly identify and fix any issues that arise.
By automating these different components of the pipeline, you can significantly reduce the time and effort required to build and deploy software, while also improving the overall quality and reliability of your applications.
Best practices for creating and managing a CI/CD pipeline with Git
Here are some best practices for creating and managing a CI/CD pipeline with Git:
-
Start with a plan: Before you start building your pipeline, take the time to plan out the process. Determine the stages of the pipeline, the tools you will use, and the requirements for each stage. This will help you create a more efficient pipeline that meets your needs.
-
Use Git branching strategies: Git branching strategies like GitFlow or trunk-based development can help you manage your pipeline better. This allows you to separate your development, testing, and production codebases and ensure that code changes are properly reviewed and tested before they are merged.
-
Automate everything: Automating the pipeline is key to maintaining consistency and avoiding human error. Automate as much as possible, including building, testing, deployment, and any other necessary steps.
-
Use continuous testing: Continuous testing ensures that code is tested throughout the pipeline, from development to production. This helps catch errors early and ensures that code is thoroughly tested before it is deployed.
-
Monitor and log everything: Monitoring and logging are essential to track pipeline performance, detect issues, and troubleshoot problems. Ensure that all pipeline stages are properly logged, and use monitoring tools to keep an eye on the pipeline’s health.
-
Keep security in mind: Security should be a top priority when building a CI/CD pipeline. Ensure that your pipeline is properly secured and that all components are updated regularly to prevent security vulnerabilities.
-
Iterate and improve: A CI/CD pipeline is a continuous process, and it’s important to continuously iterate and improve. Regularly review your pipeline, identify areas for improvement, and implement changes to ensure it is meeting your needs and is as efficient as possible.
By following these best practices, you can create a robust and efficient CI/CD pipeline with Git that can help streamline your development process and improve your overall software development lifecycle.
Best practices for Git in CI/CD
Here are some best practices for using Git in a CI/CD pipeline:
-
Keep your Git repository clean: Only commit code that has been thoroughly tested and meets your team’s standards. Use Git branching and merging strategies to manage your codebase effectively.
-
Use version control tags: Use tags to identify specific versions of your codebase and track the changes between them. This can help you identify issues and roll back changes if necessary.
-
Automate testing: Use automated testing tools to verify that your code is working as expected. This can include unit tests, integration tests, and end-to-end tests.
-
Automate the build process: Use build tools such as Gradle, Maven, or Make to automate the process of building your code. This can help ensure that your code is built consistently and that all dependencies are properly resolved.
-
Automate deployments: Use tools such as Ansible, Chef, or Puppet to automate the deployment of your code to different environments. This can help ensure that your deployments are consistent and that your code is deployed in a controlled and secure manner.
-
Monitor your pipeline: Monitor your pipeline and track metrics such as build times, test coverage, and deployment success rates. This can help you identify bottlenecks and improve the overall efficiency of your pipeline.
-
Secure your pipeline: Use Git access controls to restrict access to your codebase and ensure that only authorized users can make changes. Use tools such as SonarQube or Veracode to scan your code for security vulnerabilities.
-
Document your pipeline: Document your pipeline and share it with your team. This can help ensure that everyone understands how the pipeline works and can contribute to its improvement over time.
Understanding how to use Git branches, tags, and versioning in a CI/CD workflow
In a CI/CD workflow, Git branches, tags, and versioning play an important role in managing and tracking code changes throughout the pipeline.
Git branches can be used to separate different stages of development, such as feature development, bug fixing, and release preparation. For example, a separate branch can be created for each new feature or bug fix, and then merged into the main branch (e.g. master or main) once it has been reviewed and tested.
Tags can be used to mark specific points in the code history, such as a release version or a deployment to a production environment. This makes it easier to track changes and revert to a previous state if necessary.
Versioning is another important aspect of managing code changes in a CI/CD workflow. Semantic versioning is a popular convention used for versioning software releases. It involves using three numbers separated by dots to represent major, minor, and patch versions (e.g. 1.2.3). The major version is incremented when there are significant changes to the codebase that are not backward compatible, the minor version is incremented when new features are added that are backward compatible, and the patch version is incremented for bug fixes and small improvements.
Best practices for using Git branches, tags, and versioning in a CI/CD workflow include:
-
Use a consistent naming convention for branches and tags, such as using a prefix to indicate the type of branch or tag (e.g. feature/branch-name, release/v1.0.0).
-
Use branch protection rules to ensure that code is reviewed and tested before it can be merged into the main branch.
-
Use a continuous integration tool to automatically build and test code changes as they are pushed to the repository.
-
Use semantic versioning to keep track of software releases and communicate changes to users.
-
Use a release branch to prepare code for deployment to a production environment, and use tags to mark specific releases.
By following these best practices, teams can use Git effectively in a CI/CD workflow to manage code changes, ensure code quality, and streamline the development and deployment process.
Strategies for managing Git repositories in a team environment with continuous integration and delivery
Managing Git repositories in a team environment with continuous integration and delivery involves several key strategies to ensure smooth collaboration, version control, and reliable deployment.
-
Define branching and merging strategies: Establish clear guidelines for branching and merging in your Git repositories. This helps ensure that everyone on the team is following the same process, reducing confusion and minimizing conflicts.
-
Use automation tools for testing and deployment: Automating testing and deployment can help speed up the process and reduce the risk of human error. Using tools like Jenkins, Travis CI, or CircleCI can help automate build, test, and deployment processes, so that your team can focus on writing code and not worrying about deployment logistics.
-
Implement code review processes: Code reviews are essential for maintaining code quality and ensuring that code changes are properly reviewed and approved before they are merged into the main branch. By implementing a code review process, you can catch issues early and reduce the risk of bugs and errors in your code.
-
Use Git hooks: Git hooks can help enforce coding standards and best practices, as well as automate certain tasks like linting and testing. By using Git hooks, you can ensure that all code pushed to your Git repository meets your team’s quality standards.
-
Monitor and analyze performance metrics: Monitoring performance metrics like build times, test coverage, and deployment frequency can help you identify areas for improvement in your CI/CD process. Analyzing this data can help you make data-driven decisions to optimize your CI/CD pipeline and ensure that your team is delivering quality code at a consistent pace.
-
Establish clear documentation and communication channels: Make sure that everyone on your team has access to clear documentation on your CI/CD processes, as well as channels for communication and feedback. This helps ensure that everyone is on the same page and can collaborate effectively.
By following these best practices, you can ensure that your team is using Git effectively in a CI/CD environment, leading to more efficient collaboration, higher-quality code, and faster, more reliable deployments.
Implementing Git hooks and automated testing in a CI/CD pipeline for improved code quality and security
Implementing Git hooks and automated testing in a CI/CD pipeline can significantly improve code quality and security. Here are some steps to follow:
-
Start by creating a new branch in your Git repository that will be used for development work.
-
Configure your CI/CD pipeline to automatically build and test your code whenever changes are pushed to the development branch.
-
Implement Git hooks that will run automated tests before code is committed to the development branch. This will help catch errors and bugs before they get merged into the main branch.
-
Use automated testing tools such as unit tests, integration tests, and acceptance tests to ensure that your code meets the required quality standards.
-
Implement security scanning tools that will check your code for vulnerabilities and potential security issues. This will help prevent security breaches and data leaks.
-
Once the tests and security scans have passed, merge the development branch into the main branch and trigger a deployment to your production environment.
-
Use Git tags to version your releases and make it easy to roll back to previous versions if necessary.
-
Regularly review and analyze the results of your automated tests and security scans to identify any areas that need improvement.
By following these steps, you can create a robust and efficient CI/CD pipeline that leverages Git hooks and automated testing to improve code quality, security, and productivity.
Chapter 8: Git GUIs and IDE Integrations
Overview of popular Git GUIs
Git GUIs are graphical user interfaces that allow users to interact with Git repositories through a visual interface rather than using command-line tools. They can be helpful for users who are less familiar with Git commands or prefer a more visual way of interacting with Git. Here are some popular Git GUIs:
-
GitHub Desktop: This is a free Git GUI for Windows and macOS that allows users to manage Git repositories and perform basic Git tasks such as committing, branching, and merging.
-
Sourcetree: Sourcetree is a free Git GUI for Windows and macOS that provides a user-friendly interface for managing Git repositories. It includes features such as commit histories, code diffs, and support for Git LFS.
-
GitKraken: GitKraken is a popular Git GUI for Windows, macOS, and Linux that provides a visual interface for managing Git repositories. It includes features such as code review, Git flow support, and integrations with popular development tools.
-
Tower: Tower is a Git GUI for macOS that allows users to manage Git repositories and perform basic Git tasks through a visual interface. It includes features such as a commit history graph and integrations with other tools such as Jira and Slack.
-
Git Cola: Git Cola is a free Git GUI for Windows, macOS, and Linux that provides a simple and customizable interface for managing Git repositories. It includes features such as commit editing, conflict resolution, and support for Git LFS.
-
TortoiseGit: TortoiseGit is a free Git GUI for Windows that provides a Windows Explorer integration for managing Git repositories. It includes features such as revision graphs, commit histories, and support for Git LFS.
These are just a few examples of popular Git GUIs, and there are many more available depending on your specific needs and preferences.
Integrating Git with IDEs
Git is a popular version control system that is widely used in software development. Many integrated development environments (IDEs) provide built-in Git support, making it easy to manage Git repositories within the IDE. Here are some of the most popular IDEs and how they integrate with Git:
-
Visual Studio Code: Visual Studio Code is a popular open-source code editor that supports Git integration out of the box. It includes a built-in Git client that allows you to clone, commit, push, and pull changes directly from the editor. You can view the status of your Git repository, diff changes, and resolve merge conflicts within the editor.
-
IntelliJ IDEA: IntelliJ IDEA is a popular Java IDE that provides powerful Git integration. It includes a Git tool window that allows you to manage Git repositories, view the history of commits, and perform Git operations such as commit, push, pull, merge, and rebase. You can also view and compare changes, resolve conflicts, and use Git blame to see who made changes to a file.
-
Eclipse: Eclipse is a popular open-source IDE for Java development that provides built-in Git support. It includes a Git perspective that allows you to manage Git repositories, view the history of commits, and perform Git operations such as commit, push, pull, merge, and rebase. You can also view and compare changes, resolve conflicts, and use Git blame to see who made changes to a file.
-
Xcode: Xcode is a popular IDE for developing iOS and macOS applications that provides built-in Git support. It includes a built-in Git client that allows you to clone, commit, push, and pull changes directly from the editor. You can view the status of your Git repository, diff changes, and resolve merge conflicts within the editor.
-
NetBeans: NetBeans is a popular open-source IDE for Java development that provides built-in Git support. It includes a Git tool window that allows you to manage Git repositories, view the history of commits, and perform Git operations such as commit, push, pull, merge, and rebase. You can also view and compare changes, resolve conflicts, and use Git blame to see who made changes to a file.
Overall, using an IDE with built-in Git support can help you streamline your workflow and make it easier to manage Git repositories. Whether you’re working on a small project or a large-scale software development project, Git integration in your IDE can save you time and improve your productivity.
Visual Studio Code
Visual Studio Code (VS Code) is a popular open-source code editor developed by Microsoft. It has built-in Git integration that allows developers to manage their Git repositories directly within the editor.
Some of the key features of Git integration in VS Code include:
-
Git commands in the command palette: VS Code provides a command palette that allows developers to execute various Git commands without leaving the editor. For example, developers can commit changes, create branches, and view commit history, all from within the command palette.
-
Source control panel: VS Code has a built-in source control panel that displays the current branch, changes made to files, and other relevant information. Developers can easily stage and commit changes, create branches, and merge code directly from this panel.
-
Visual diff and merge tool: VS Code has a built-in visual diff and merge tool that allows developers to compare different versions of files and merge changes easily. This tool makes it easy to resolve merge conflicts and keep code up-to-date.
-
Git blame: VS Code has a built-in Git blame feature that allows developers to see who made changes to a specific line of code and when. This information can be useful when debugging issues or identifying areas of code that need improvement.
In addition to these features, VS Code also has many extensions available that provide additional Git functionality. For example, the GitLens extension provides more detailed information about Git repositories, including commit history, blame information, and more.
IntelliJ IDEA
IntelliJ IDEA is a popular integrated development environment (IDE) for Java developers that also has support for Git integration. Here are some of the key features of Git integration in IntelliJ IDEA:
-
Visual Git history: IntelliJ IDEA provides a visual representation of the Git history, which makes it easy to see how the repository has evolved over time. You can view the history of a file, a directory, or the entire repository, and you can see who made each commit and when.
-
Branch management: IntelliJ IDEA allows you to create, switch, and delete branches with ease. You can also view the differences between branches and merge them directly from within the IDE.
-
Code review: IntelliJ IDEA has built-in support for code review, which allows you to review changes made by other developers and provide feedback. You can review changes in the context of the entire repository or just for a single file.
-
Stash support: IntelliJ IDEA allows you to stash changes and pop them later, which can be useful if you need to switch branches quickly.
-
GitHub integration: IntelliJ IDEA has support for GitHub, which allows you to create and manage pull requests directly from within the IDE. You can also view the status of your pull requests and merge them when they are ready.
-
Conflict resolution: IntelliJ IDEA provides a conflict resolution tool that makes it easy to resolve merge conflicts. You can view the differences between the conflicting versions and choose which changes to keep.
Overall, IntelliJ IDEA’s Git integration is powerful and flexible, and it can help you streamline your workflow and increase your productivity.
Eclipse
Eclipse is an open-source integrated development environment (IDE) that supports multiple programming languages, including Java, C++, Python, and more. It provides built-in support for Git, allowing developers to perform common Git operations directly within the IDE.
To use Git in Eclipse, developers need to install the EGit plugin, which is an Eclipse project that provides Git integration. EGit provides a graphical interface for performing Git operations, including committing changes, pushing and pulling from remote repositories, branching and merging, and more.
EGit also provides support for common Git workflows, such as working with feature branches, rebasing, and resolving conflicts. It integrates with the Eclipse Team Synchronization perspective, which provides a comprehensive view of the Git repository, including the current branch, local changes, and remote changes.
One of the advantages of using Git with Eclipse is the ability to perform code reviews directly within the IDE. EGit provides integration with Gerrit, a code review tool that allows developers to submit changes for review and receive feedback from other team members. EGit can also integrate with other code review tools, such as GitHub, Bitbucket, and GitLab.
Overall, Git integration with Eclipse provides a powerful and efficient workflow for developing software, collaborating with team members, and managing code changes.
Xcode
Xcode is an integrated development environment (IDE) for developing applications for macOS, iOS, iPadOS, watchOS, and tvOS. It includes support for Git version control system and provides an easy-to-use interface for common Git commands such as commit, push, pull, and branch management.
To use Git with Xcode, you need to enable version control for your project. This can be done by selecting “Create Git repository on” in the project creation dialog or by going to Source Control > Create Git Repositories. Once you have enabled version control, you can use Xcode’s built-in Git features to manage your code.
Xcode’s Source Control navigator provides a convenient way to access Git commands and see the status of your repository. The navigator shows a list of branches, tags, and commits, as well as the status of your working directory. You can use the navigator to create and switch branches, view commit history, and perform other Git operations.
Xcode also provides support for Git workflows such as Git flow. You can use Xcode to create and manage feature branches, release branches, and hotfix branches. Xcode also supports rebasing and merging, which are common operations in Git workflows.
Overall, Xcode provides a streamlined Git integration that makes it easy to manage your code and collaborate with your team.
Using Git on the command line vs. using a GUI
Git can be used both from the command line and through a graphical user interface (GUI). Both options have their advantages and disadvantages, and which one to choose depends on personal preferences, the task at hand, and the level of comfort with the command line.
Using Git on the command line provides more flexibility and control over Git commands and workflows. It also allows for greater customization and scripting of Git commands. Experienced developers often prefer the command line interface because it offers a more direct and powerful way to interact with Git.
On the other hand, using a GUI can be easier for beginners or developers who prefer a more visual interface. A GUI can simplify complex Git commands and provide more intuitive visualization of Git operations, such as branching and merging. GUIs can also provide additional features, such as visual diffs, code review tools, and integration with project management tools.
In some cases, developers may choose to use both the command line and a GUI, depending on the task they are performing. For example, they might use the command line for complex branching and merging operations and use the GUI for visualizing the repository’s history and changes.
Ultimately, the choice of using Git on the command line versus a GUI comes down to personal preference and the needs of the project and team.
Pros and cons of using a GUI
Using a graphical user interface (GUI) for Git can have several advantages, such as:
-
User-friendly interface: A GUI provides an easy-to-use interface that can be more intuitive for beginners than using the command line.
-
Visual representation of the repository: GUIs often provide a visual representation of the repository, allowing you to easily see the history, branches, and commits.
-
Easy access to Git commands: GUIs provide easy access to commonly used Git commands, such as branching, merging, and committing.
-
Built-in features: Some GUIs come with built-in features like syntax highlighting, code review tools, and conflict resolution tools that can help streamline the development process.
However, there are also some drawbacks to using a GUI:
-
Limited functionality: Some GUIs may not provide access to all of Git’s features, which can be frustrating for more experienced Git users.
-
Dependence on the GUI: Relying too heavily on a GUI can make it harder to transition to using the command line, which can be important if you need to work on a system without a GUI or if you need to perform more advanced Git operations.
-
Compatibility issues: Some GUIs may not be compatible with certain operating systems, development environments, or Git configurations.
Ultimately, the decision to use a GUI or the command line comes down to personal preference and the specific needs of your development team.
Pros and cons of using the command line
Using the command line for Git has its own advantages and disadvantages.
Pros:
- Full control and flexibility: With command-line Git, you have access to the full suite of Git commands and options. You can customize your workflow and automate repetitive tasks using scripts.
- Portability: Command-line Git can be used on any operating system, as long as Git is installed.
- Speed: Command-line Git operations tend to be faster than GUI operations, especially for larger repositories.
Cons:
- Steep learning curve: Command-line Git has a steep learning curve and can be intimidating for beginners who are not familiar with the command-line interface.
- Lack of visual representation: With command-line Git, you don’t get the benefit of visualizing your repository’s history and changes, which can make it harder to understand complex branches and merges.
- Prone to errors: Since command-line Git requires manual typing and can be complex, it is more prone to errors and mistakes, especially for beginners.
Overall, using the command line for Git is preferred by many experienced developers who want full control and flexibility over their workflow, while beginners or developers who prefer a visual interface may prefer using a GUI.
Choosing the right Git tool for your workflow
Choosing the right Git tool for your workflow depends on several factors, including your level of expertise, the complexity of your project, the size of your team, and the specific features you need. Here are some factors to consider when choosing a Git tool:
-
Command line vs. GUI: Consider whether you prefer to work with Git using the command line or a graphical user interface (GUI). If you’re comfortable with the command line and prefer a lightweight workflow, the command line might be the best choice. However, if you prefer a more visual and user-friendly experience, a GUI might be a better fit.
-
IDE integration: If you’re using an IDE for your development, it’s important to consider whether the Git tool integrates well with your IDE. Many IDEs have built-in Git support or plugins that make it easy to manage your code directly from the IDE.
-
Team collaboration: If you’re working on a large team, it’s important to choose a Git tool that supports collaboration and has features such as pull requests, code reviews, and merge conflicts resolution. Additionally, consider whether the Git tool integrates with your team’s other collaboration tools, such as project management software or chat apps.
-
Complexity of project: For complex projects with multiple branches, complex merge scenarios, and large codebases, you may need a Git tool that has advanced features such as Git submodules, Git LFS, or rebasing.
-
Platform compatibility: Consider whether the Git tool works on your platform of choice (e.g., Windows, macOS, Linux), as well as any specific requirements you might have, such as support for SSH keys, GPG signatures, or specific Git workflows.
-
Price: Finally, consider the cost of the Git tool. While Git itself is open source and free, some GUI clients or IDE plugins may require a paid license. Be sure to factor in the cost when evaluating different options.
Ultimately, the best Git tool for your workflow will depend on your individual needs and preferences. It’s a good idea to try out different tools and workflows to see what works best for you and your team.
Factors to consider when choosing a Git tool
When choosing a Git tool, there are several factors to consider, such as:
-
Ease of use: The tool should be easy to use and should have an intuitive user interface.
-
Features: The tool should have all the necessary features that you require for your project.
-
Compatibility: The tool should be compatible with the operating system and programming language used in your project.
-
Integration: The tool should integrate well with other tools that you use in your workflow, such as text editors, IDEs, and CI/CD tools.
-
Performance: The tool should be fast and efficient, and should not slow down your workflow.
-
Support: The tool should have a good support system in case you encounter any issues or need help.
-
Cost: The tool should be cost-effective and should fit within your budget.
By considering these factors, you can choose the best Git tool for your project.
Tips for evaluating Git tools
Here are some tips for evaluating Git tools:
-
Research and compare: Do your research and compare the features, compatibility, integration, performance, support, and cost of different Git tools.
-
Try before you buy: Many Git tools offer free trials or demo versions. Try out the tool before you make a purchase to see if it meets your needs.
-
Check reviews: Look for reviews of the Git tool you are considering to see what other users think of it. Pay attention to both positive and negative reviews to get a balanced view.
-
Consider your team’s needs: Consider the needs of your team when evaluating Git tools. Look for a tool that fits your team’s workflow and collaboration needs.
-
Look for extensibility: Consider the extensibility of the Git tool. Look for a tool that can be extended with plugins or other tools to meet your specific needs.
-
Consider future growth: Consider the future growth of your project and team. Look for a Git tool that can scale with your project and team as it grows.
By following these tips, you can evaluate Git tools and choose the one that best fits your needs.
Chapter 9: Git and DevOps
The role of Git in DevOps
Git plays a crucial role in DevOps by providing a version control system that enables teams to collaborate and manage changes to their code base. Here are some specific ways Git contributes to DevOps:
-
Code versioning: Git allows developers to keep track of changes to their code over time, making it easier to collaborate on projects and ensure that changes are properly managed and tracked.
-
Branching and merging: Git’s branching and merging capabilities allow teams to work on multiple versions of a code base simultaneously, making it easier to test and deploy changes without affecting the main code base.
-
Continuous Integration and Continuous Delivery (CI/CD): Git integrates with many CI/CD tools, making it easier to automate the build, test, and deployment processes.
-
Collaboration: Git enables teams to collaborate on code, making it easier to share code changes and work together on projects.
-
Rollback and recovery: Git’s version control system makes it easy to roll back changes to a previous version of the code base and recover from errors or mistakes.
-
Code reviews: Git provides a platform for code reviews, enabling teams to review and approve code changes before they are merged into the main code base.
Overall, Git helps teams to work more efficiently and effectively in DevOps environments by providing a centralized platform for version control, collaboration, and automation.
Understanding the DevOps workflow
The DevOps workflow is a set of practices and tools used by teams to develop, test, and deploy software quickly and reliably. The workflow involves several stages, each of which contributes to the overall goal of delivering high-quality software.
-
Plan: The first stage of the DevOps workflow is planning. This involves defining the requirements of the software, creating a project plan, and setting goals and objectives.
-
Code: Once the plan is in place, the development team starts writing code. This stage involves creating new features, fixing bugs, and making other changes to the code base.
-
Build: The code is then built and tested, typically using automated tools. This stage ensures that the code is error-free and ready for deployment.
-
Test: The testing stage involves validating the code to ensure that it meets the requirements of the project. This stage may involve automated testing, manual testing, or both.
-
Deploy: Once the code has been tested and validated, it is deployed to a production environment. This stage involves using tools and techniques to ensure that the deployment is reliable and error-free.
-
Operate: The operation stage involves monitoring the software in production to ensure that it is running smoothly. This stage may involve using monitoring tools and techniques to identify and fix issues as they arise.
-
Monitor: The final stage of the workflow is monitoring. This involves tracking the performance of the software over time and using data and analytics to improve its functionality and performance.
By following this DevOps workflow, teams can deliver high-quality software quickly and reliably, with a focus on collaboration, automation, and continuous improvement.
How Git enables DevOps practices
Git enables DevOps practices in several ways, including:
-
Version control: Git provides a centralized platform for version control, making it easier for teams to manage changes to their code base. By using Git, teams can track changes, collaborate on code, and roll back changes if necessary.
-
Collaboration: Git enables teams to collaborate on code, making it easier to share code changes and work together on projects. Git also provides a platform for code reviews, enabling teams to review and approve code changes before they are merged into the main code base.
-
Branching and merging: Git’s branching and merging capabilities allow teams to work on multiple versions of a code base simultaneously, making it easier to test and deploy changes without affecting the main code base.
-
Continuous Integration and Continuous Delivery (CI/CD): Git integrates with many CI/CD tools, making it easier to automate the build, test, and deployment processes. By using Git with CI/CD tools, teams can deploy changes quickly and reliably, with a focus on automation and continuous improvement.
-
Infrastructure as code: Git enables teams to manage their infrastructure as code, making it easier to version, test, and deploy infrastructure changes. By using Git for infrastructure as code, teams can ensure that their infrastructure is consistent, reliable, and repeatable.
Overall, Git plays a critical role in enabling DevOps practices by providing a centralized platform for version control, collaboration, automation, and continuous improvement. By using Git in their workflows, teams can deliver high-quality software quickly and reliably, with a focus on collaboration, automation, and continuous improvement.
Using Git with containerization technologies (Docker, Kubernetes)
Git can be used in conjunction with containerization technologies like Docker and Kubernetes to manage and deploy containerized applications. Here are some ways Git can be used with these technologies:
-
Version control for Dockerfiles: Dockerfiles are used to build Docker images, which are then used to create containers. By storing Dockerfiles in Git, teams can track changes to the files over time and collaborate on them more easily.
-
Version control for Kubernetes manifests: Kubernetes manifests describe the desired state of a Kubernetes cluster, including the deployment of pods, services, and other resources. By storing manifests in Git, teams can track changes to the cluster configuration over time and collaborate on them more easily.
-
Continuous integration and delivery with Git and Docker: Git can be used with CI/CD tools like Jenkins, CircleCI, or GitLab CI to build, test, and deploy Docker images. This enables teams to automate the build and deployment process, ensuring that changes are deployed quickly and reliably.
-
Deployment with Kubernetes: Git can also be used with Kubernetes to deploy containerized applications to a Kubernetes cluster. By storing manifests in Git, teams can automate the deployment process, ensuring that changes are deployed quickly and reliably.
-
Version control for Helm charts: Helm charts are used to deploy Kubernetes applications with predefined configurations. By storing Helm charts in Git, teams can track changes to the charts over time and collaborate on them more easily.
Overall, Git can be used with Docker and Kubernetes to enable version control, collaboration, automation, and continuous delivery for containerized applications. By using Git in conjunction with containerization technologies, teams can deploy applications more quickly and reliably, with a focus on automation and continuous improvement.
Using Git for version control of container images
Git can be used for version control of container images by storing the Dockerfiles used to create the images in a Git repository. Dockerfiles are used to build Docker images, which can be versioned and tracked in Git, allowing teams to manage changes to their container images more effectively.
Here are some benefits of using Git for version control of container images:
-
Version control: By storing Dockerfiles in Git, teams can track changes to their container images over time and easily revert to previous versions if necessary.
-
Collaboration: Git provides a platform for collaboration, making it easier for teams to work together on container images. Team members can review and approve changes to Dockerfiles before they are merged into the main codebase, ensuring that container images are built consistently and reliably.
-
Continuous integration and delivery: By using Git with CI/CD tools, teams can automate the build and deployment process for container images, ensuring that changes are deployed quickly and reliably.
-
Centralized repository: Git provides a centralized repository for container images, making it easier to manage and track changes to images across multiple environments and deployments.
-
Easy integration with other tools: Git integrates easily with other tools commonly used in containerization workflows, such as Docker Compose, Kubernetes, and Helm.
By using Git for version control of container images, teams can manage changes to their images more effectively, collaborate more easily, and deploy changes more quickly and reliably, with a focus on automation and continuous improvement.
Integrating Git into the Docker and Kubernetes workflows
Integrating Git into Docker and Kubernetes workflows can help teams manage changes to their containerized applications more effectively. Here are some ways Git can be integrated into these workflows:
-
Version control for Dockerfiles and Kubernetes manifests: Storing Dockerfiles and Kubernetes manifests in Git allows teams to track changes to their containerized applications over time and collaborate more effectively on changes.
-
Continuous integration and delivery with Git and Docker: Git can be used with CI/CD tools like Jenkins, CircleCI, or GitLab CI to build, test, and deploy Docker images. This enables teams to automate the build and deployment process, ensuring that changes are deployed quickly and reliably.
-
Deployment with Kubernetes: Git can be used to automate the deployment of Kubernetes manifests, ensuring that changes are deployed quickly and reliably. Using GitOps, teams can create a Git repository that contains the desired state of their Kubernetes cluster, and then use Git to automatically deploy changes to the cluster.
-
Version control for Helm charts: Helm charts are used to deploy Kubernetes applications with predefined configurations. By storing Helm charts in Git, teams can track changes to the charts over time and collaborate more effectively on changes.
-
Git-based workflows: Using Git-based workflows, teams can use Git pull requests to manage changes to Dockerfiles, Kubernetes manifests, and Helm charts. This allows team members to review and approve changes before they are merged into the main codebase, ensuring that changes are consistent and reliable.
Overall, integrating Git into Docker and Kubernetes workflows can help teams manage changes to their containerized applications more effectively, automate the build and deployment process, and deploy changes quickly and reliably. By using Git in conjunction with these technologies, teams can focus on collaboration, automation, and continuous improvement, enabling them to deliver high-quality software more quickly and reliably.
GitOps and infrastructure as code (IaC)
GitOps and Infrastructure as Code (IaC) are two related concepts that can work together to help teams manage infrastructure and application deployments more effectively.
GitOps is a way of managing infrastructure and application deployments using Git as the single source of truth for the desired state of the system. This involves storing infrastructure definitions, application code, and configuration files in Git, and then using automation to deploy changes to the system based on the changes made in Git.
Infrastructure as Code (IaC) is the practice of defining infrastructure and application deployments in code, using tools like Terraform, CloudFormation, or Ansible. This allows teams to version control their infrastructure code, and easily deploy, test, and rollback changes.
Together, GitOps and IaC can provide a powerful way of managing infrastructure and application deployments. Here are some of the benefits of using these two concepts together:
-
Version control: By storing infrastructure code and application code in Git, teams can version control the entire deployment process. This provides an audit trail of changes made to the system over time, and allows teams to easily revert to a previous state if necessary.
-
Automation: By using automation to deploy changes to the system, teams can reduce the risk of human error and ensure that deployments are consistent and repeatable.
-
Collaboration: Using Git as the single source of truth for the desired state of the system, teams can collaborate more effectively on changes. Git pull requests can be used to review and approve changes before they are deployed to production.
-
Scalability: By defining infrastructure and application deployments in code, teams can easily scale their deployments to multiple environments, reducing the risk of configuration drift and ensuring consistency across environments.
Overall, GitOps and IaC provide a powerful way of managing infrastructure and application deployments, allowing teams to version control their deployments, automate the deployment process, collaborate more effectively on changes, and scale their deployments to multiple environments.
Understanding GitOps and its benefits
GitOps is a way of managing infrastructure and application deployments using Git as the single source of truth for the desired state of the system. It is a methodology that aims to automate infrastructure and application deployments, and provide an audit trail of changes made to the system over time.
The basic idea behind GitOps is to store infrastructure definitions, application code, and configuration files in Git, and then use automation to deploy changes to the system based on the changes made in Git. This approach provides several benefits, including:
-
Consistency: By defining infrastructure and application deployments in code, teams can ensure that deployments are consistent across environments, reducing the risk of configuration drift and making it easier to manage complex systems.
-
Automation: By using automation to deploy changes to the system, teams can reduce the risk of human error and ensure that deployments are consistent and repeatable.
-
Collaboration: By using Git as the single source of truth for the desired state of the system, teams can collaborate more effectively on changes. Git pull requests can be used to review and approve changes before they are deployed to production.
-
Auditing: By storing infrastructure code and application code in Git, teams can version control the entire deployment process. This provides an audit trail of changes made to the system over time, and allows teams to easily revert to a previous state if necessary.
-
Scalability: By defining infrastructure and application deployments in code, teams can easily scale their deployments to multiple environments, reducing the risk of configuration drift and ensuring consistency across environments.
Overall, GitOps provides a powerful way of managing infrastructure and application deployments, allowing teams to automate their deployments, collaborate more effectively on changes, version control their deployments, and ensure consistency across environments. By adopting GitOps, teams can improve the reliability, scalability, and agility of their deployments, and deliver higher-quality software more quickly and reliably.
Using Git for version control of infrastructure as code
Using Git for version control of infrastructure as code (IaC) is a common practice that provides several benefits for managing infrastructure deployments. By storing infrastructure code in Git, teams can version control their infrastructure definitions, collaborate on changes, and automate the deployment process. Here are some of the key benefits of using Git for version control of IaC:
-
Version Control: Git provides a complete history of all changes made to the infrastructure code, allowing teams to view, compare, and revert changes made over time. This provides an audit trail of changes made to the system, which is crucial for managing complex infrastructure deployments.
-
Collaboration: Git allows teams to collaborate more effectively on changes to the infrastructure code. Multiple team members can work on the same codebase, and Git pull requests can be used to review and approve changes before they are deployed.
-
Automation: By storing infrastructure code in Git, teams can use automation tools to automatically deploy changes to the system. This ensures that changes are consistent and repeatable across all environments, and reduces the risk of human error.
-
Scalability: Git allows teams to manage infrastructure deployments across multiple environments, such as development, staging, and production. By defining infrastructure code in Git, teams can easily scale their deployments to multiple environments, reducing the risk of configuration drift and ensuring consistency across environments.
-
Testing: By version controlling infrastructure code in Git, teams can easily test changes to the infrastructure code in isolation, without affecting the production environment. This allows teams to catch issues early in the development cycle, and reduces the risk of downtime and other production issues.
Overall, using Git for version control of infrastructure as code provides a powerful way of managing infrastructure deployments. By version controlling infrastructure code in Git, teams can improve collaboration, automate the deployment process, ensure consistency across environments, and catch issues early in the development cycle.
Implementing GitOps with tools like Flux, ArgoCD, and Jenkins X
Implementing GitOps with tools like Flux, ArgoCD, and Jenkins X is a common practice that provides a powerful way of managing infrastructure and application deployments. These tools allow teams to automate the deployment process, use Git as the single source of truth, and provide an audit trail of changes made to the system. Here’s how these tools work and how they can be used to implement GitOps:
-
Flux: Flux is a popular GitOps tool that automates the deployment process by using Git as the single source of truth for the desired state of the system. It works by monitoring a Git repository for changes to infrastructure and application code, and then automatically deploying those changes to the system. Flux can be used to manage deployments to Kubernetes clusters, and supports a wide range of deployment strategies, including canary deployments and blue-green deployments.
-
ArgoCD: ArgoCD is another GitOps tool that provides a powerful way of managing deployments to Kubernetes clusters. It works by using Git as the single source of truth for the desired state of the system, and then automating the deployment process based on changes made in Git. ArgoCD provides a powerful dashboard that allows teams to view the current state of the system, and can be used to automate the deployment of complex applications with multiple components.
-
Jenkins X: Jenkins X is a GitOps tool that provides a complete CI/CD pipeline for Kubernetes-based applications. It works by using Git as the single source of truth for the desired state of the system, and then automating the entire deployment process, from code changes to production deployments. Jenkins X supports a wide range of deployment strategies, including canary deployments and blue-green deployments, and provides a powerful dashboard that allows teams to view the current state of the system.
Overall, implementing GitOps with tools like Flux, ArgoCD, and Jenkins X provides a powerful way of managing infrastructure and application deployments. By using Git as the single source of truth, teams can automate the deployment process, collaborate more effectively on changes, version control their deployments, and ensure consistency across environments. By adopting GitOps, teams can improve the reliability, scalability, and agility of their deployments, and deliver higher-quality software more quickly and reliably.
Git and DevOps best practices
Git and DevOps best practices are essential for achieving efficient and effective software delivery. Here are some best practices for using Git in DevOps:
-
Branching Strategy: Adopt a branching strategy that fits the team’s workflow and the project’s needs. Git Flow, Trunk-Based Development, and Feature Branching are some common branching strategies.
-
Continuous Integration (CI): Use a CI system to automatically test changes made to the codebase. Jenkins, Travis CI, and CircleCI are some popular CI tools.
-
Continuous Delivery (CD): Use a CD system to automate the deployment of code changes to different environments. This ensures that the code is delivered quickly and consistently across environments. Tools like Flux, ArgoCD, and Jenkins X are some popular CD tools.
-
Infrastructure as Code (IaC): Version control the infrastructure code with Git and automate the deployment process. This ensures that the infrastructure is consistent across environments and reduces the risk of configuration drift.
-
Automation: Automate as many tasks as possible, such as building, testing, and deploying. This reduces the risk of human error and allows teams to deliver code more quickly and reliably.
-
Code Reviews: Use Git pull requests to review code changes before they are merged into the main branch. This ensures that the code is of high quality and meets the team’s standards.
-
Monitoring: Monitor the system and gather metrics to identify issues early in the development cycle. This helps teams to identify issues and improve the quality of the code.
By following these Git and DevOps best practices, teams can improve collaboration, automate the deployment process, ensure consistency across environments, and deliver higher-quality software more quickly and reliably.
Tips for using Git in DevOps
Here are some tips for using Git in DevOps:
-
Use Git as the Single Source of Truth: Use Git as the single source of truth for all changes made to the codebase and infrastructure. This ensures that all changes are version controlled, audited, and can be traced back to a specific commit.
-
Adopt a Branching Strategy: Choose a branching strategy that fits the team’s workflow and the project’s needs. Git Flow, Trunk-Based Development, and Feature Branching are some common branching strategies. Be consistent in following the branching strategy.
-
Commit Early and Often: Encourage team members to commit changes frequently to the Git repository. This helps to reduce the risk of conflicts and makes it easier to track changes made to the codebase.
-
Use Git Hooks: Use Git hooks to automate repetitive tasks, such as linting and testing. Git hooks can be used to trigger scripts or other tools that automate these tasks.
-
Use Tags: Use Git tags to mark important milestones, such as releases and production deployments. This makes it easier to track the history of the project and identify the state of the system at a specific point in time.
-
Use Pull Requests: Use pull requests to review and approve changes before they are merged into the main branch. This helps to ensure that the code meets the team’s standards and is of high quality.
-
Use Git to Version Control Infrastructure: Use Git to version control infrastructure code and automate the deployment process. This ensures that the infrastructure is consistent across environments and reduces the risk of configuration drift.
By following these tips for using Git in DevOps, teams can improve collaboration, automate the deployment process, ensure consistency across environments, and deliver higher-quality software more quickly and reliably.
Common mistakes to avoid
Here are some common mistakes to avoid when using Git in DevOps:
-
Not Using Git for Version Control: Avoid not using Git or any other version control system. Using a version control system is essential for DevOps, as it helps to keep track of changes, maintain code quality, and automate the deployment process.
-
Not Using Branching Strategies: Avoid not using a branching strategy, or using an inappropriate branching strategy. Choosing an appropriate branching strategy, such as Git Flow or Trunk-Based Development, can help teams to manage code changes and reduce the risk of conflicts.
-
Not Committing Frequently: Avoid not committing changes frequently to the Git repository. Frequent commits help to reduce the risk of conflicts and make it easier to track changes made to the codebase.
-
Not Using Pull Requests: Avoid not using pull requests for code reviews. Pull requests help to ensure that the code meets the team’s standards and is of high quality.
-
Not Automating the Deployment Process: Avoid not automating the deployment process. Automating the deployment process helps to reduce the risk of errors and ensures that the code is delivered quickly and consistently across environments.
-
Not Version Controlling Infrastructure: Avoid not version controlling infrastructure code. Version controlling infrastructure code helps to ensure that the infrastructure is consistent across environments and reduces the risk of configuration drift.
-
Not Backing Up the Git Repository: Avoid not backing up the Git repository. Backing up the Git repository is essential to ensure that the code and history are not lost in case of data loss or corruption.
By avoiding these common mistakes, teams can use Git effectively in DevOps, improve collaboration, automate the deployment process, and deliver higher-quality software more quickly and reliably.
Real-world examples of Git in DevOps workflows
Here are some real-world examples of Git being used in DevOps workflows:
-
Netflix: Netflix uses Git for version control, and its codebase is stored in a private GitHub repository. They use the Git Flow branching strategy, and developers are encouraged to commit changes frequently. Netflix also uses GitOps practices to manage its infrastructure and automate deployments.
-
Etsy: Etsy uses Git for version control and its codebase is stored in a private GitHub repository. They use a Trunk-Based Development branching strategy, which encourages small, frequent changes to the codebase. They also use Git hooks to automate linting, testing, and other repetitive tasks.
-
NASA: NASA uses Git for version control of its software systems, including the Mars Rover software. They use a Git Flow branching strategy and pull requests for code reviews. NASA also uses Jenkins for continuous integration and deployment, which integrates with Git to trigger automated builds and deployments.
-
Shopify: Shopify uses Git for version control and stores its codebase in a private GitHub repository. They use a Feature Branching branching strategy and pull requests for code reviews. Shopify also uses Kubernetes for container orchestration, which integrates with Git to automate deployments.
-
Walmart: Walmart uses Git for version control and stores its codebase in a private GitHub repository. They use a Git Flow branching strategy and pull requests for code reviews. Walmart also uses Terraform for infrastructure as code, which integrates with Git to version control infrastructure code and automate deployments.
These examples illustrate how Git can be used in various DevOps workflows, and how it can be integrated with other tools to automate the deployment process, ensure code quality, and improve collaboration.
Chapter 10: Git Security
Git security best practices
Here are some Git security best practices to help protect your code and Git repository:
-
Use strong passwords: Ensure that all users have strong passwords and use multi-factor authentication to protect access to the repository.
-
Limit access: Limit access to the repository to only those who need it. Grant users only the minimum privileges required to perform their tasks.
-
Use HTTPS or SSH: Use HTTPS or SSH for Git repository access instead of the unsecured Git protocol.
-
Encrypt data at rest and in transit: Ensure that the Git repository is encrypted at rest and in transit. Use SSL or TLS to encrypt data in transit and encrypt the repository using file-level or disk-level encryption.
-
Audit logs: Enable Git audit logs to track changes and user actions in the repository. This helps identify and investigate any suspicious activity.
-
Use signed commits: Require signed commits to ensure that code changes are authentic and unaltered.
-
Use Git hooks: Use Git hooks to enforce security policies and prevent malicious code from being committed to the repository.
-
Regularly update Git: Keep Git up to date with the latest security patches to ensure that any known vulnerabilities are addressed.
-
Regularly backup the repository: Regularly backup the repository to prevent data loss and to restore the repository in case of any issues or disasters.
By following these Git security best practices, you can help ensure the security of your code and Git repository, and reduce the risk of data breaches or other security incidents.
Preventing Git leaks
Preventing Git leaks is important to avoid exposing sensitive information such as passwords, API keys, and other confidential data that should not be shared. Here are some ways to prevent Git leaks:
-
Avoid committing sensitive data: Avoid committing sensitive data to Git repositories. This includes passwords, API keys, and other confidential data. Instead, store such information in a secure location such as a password manager.
-
Use .gitignore file: Use a .gitignore file to exclude sensitive files and directories from being committed to the repository. This file tells Git which files and directories to ignore, preventing them from being tracked and committed.
-
Use Git hooks: Use Git hooks to prevent certain files from being committed to the repository. For example, you can use a pre-commit hook to check if sensitive data is being committed and prevent the commit if it is.
-
Use Git LFS: Git LFS (Large File Storage) can be used to store large files outside of the Git repository. This reduces the risk of accidentally committing sensitive data that might be contained in large files.
-
Use Git submodules: Git submodules can be used to manage external dependencies separately from the main repository. This can help prevent sensitive data from being exposed in dependencies.
-
Use Git Secrets: Git Secrets is a tool that scans Git repositories for known sensitive data patterns and prevents them from being committed.
By following these practices, you can prevent Git leaks and avoid exposing sensitive data to unintended users.
Protecting your Git infrastructure
Protecting your Git infrastructure is critical to ensuring that your code and repositories are safe and secure. Here are some steps you can take to protect your Git infrastructure:
-
Use strong authentication: Ensure that strong authentication mechanisms are in place for all users accessing the Git infrastructure. This includes the use of secure passwords and two-factor authentication.
-
Use access controls: Limit access to Git repositories to only those users who need it. Grant users the minimum privileges required to perform their tasks.
-
Encrypt data in transit and at rest: Use SSL or TLS to encrypt data in transit between clients and the Git server. Use encryption to protect data at rest on the Git server and backup servers.
-
Implement backups: Regularly backup Git repositories and ensure that backups are tested and restorable.
-
Use firewall and network security: Implement firewalls and other network security measures to protect the Git infrastructure from unauthorized access.
-
Regularly update Git: Ensure that Git is kept up to date with the latest security patches to protect against known vulnerabilities.
-
Monitor Git logs: Regularly monitor Git logs for suspicious activity, such as multiple failed login attempts or unauthorized access attempts.
-
Use Git hosting providers: Consider using Git hosting providers that provide additional security features and protections.
By following these practices, you can help protect your Git infrastructure and ensure the security of your code and repositories.
Auditing Git repositories
Auditing Git repositories is an important process to ensure that your code and repositories are secure and compliant with your organization’s policies. Here are some ways to audit Git repositories:
-
Regularly review Git logs: Git logs can provide information on who has accessed and made changes to the repositories. Reviewing these logs regularly can help detect suspicious activity.
-
Use Git hooks: Git hooks can be used to enforce policies and best practices, such as preventing certain files from being committed or requiring commit messages to follow a certain format.
-
Conduct code reviews: Conducting code reviews can help ensure that code changes are following best practices and are compliant with your organization’s policies.
-
Scan for vulnerabilities: Use tools such as Git-Secrets, Trufflehog, and Gitrob to scan repositories for sensitive data and vulnerabilities.
-
Monitor third-party dependencies: Monitor third-party dependencies used in your code for security vulnerabilities and compliance with your organization’s policies.
-
Use access controls: Use access controls to limit access to repositories and ensure that users only have the minimum privileges required to perform their tasks.
-
Implement regular security assessments: Conduct regular security assessments to identify and address vulnerabilities in your Git infrastructure.
By implementing these auditing practices, you can help ensure that your Git repositories are secure and compliant with your organization’s policies.
Common security threats in Git and how to mitigate them
Here are some common security threats in Git and ways to mitigate them:
-
Weak credentials: Weak or easily guessable credentials can lead to unauthorized access to Git repositories. To mitigate this threat, enforce strong password policies and consider implementing two-factor authentication.
-
Social engineering: Social engineering attacks, such as phishing or pretexting, can be used to trick users into revealing their Git credentials. To mitigate this threat, educate users on how to recognize and avoid social engineering attacks.
-
Malware: Malware on a user’s computer can be used to steal Git credentials and gain unauthorized access to repositories. To mitigate this threat, ensure that users have up-to-date anti-malware software installed on their computers.
-
Misconfiguration: Misconfiguration of Git repositories, such as allowing unrestricted access, can lead to unauthorized access and data breaches. To mitigate this threat, ensure that Git repositories are properly configured with access controls and permissions.
-
Code injection: Code injection attacks can be used to inject malicious code into Git repositories. To mitigate this threat, use tools to scan Git repositories for vulnerabilities and regularly review code changes for signs of injection attacks.
-
Insider threats: Insider threats, such as employees or contractors with malicious intent, can be difficult to detect and mitigate. To mitigate this threat, implement access controls, conduct regular security assessments, and monitor Git logs for suspicious activity.
-
Third-party risks: Third-party risks, such as vulnerabilities in third-party dependencies, can be used to gain unauthorized access to Git repositories. To mitigate this threat, monitor third-party dependencies for security vulnerabilities and regularly update them to the latest versions.
By implementing these mitigation strategies, you can help protect your Git repositories from common security threats.
Git security risks associated with remote repositories
Remote repositories in Git can introduce additional security risks, as they involve transmitting data over networks and potentially storing data on third-party servers. Here are some Git security risks associated with remote repositories and how to mitigate them:
-
Man-in-the-middle attacks: Man-in-the-middle attacks can occur when an attacker intercepts and modifies data transmitted between a local repository and a remote repository. To mitigate this threat, use secure communication protocols, such as HTTPS or SSH, to transmit data between repositories.
-
Unauthorized access: Unauthorized access can occur when an attacker gains access to a remote repository without proper authentication or authorization. To mitigate this threat, enforce access controls and authentication requirements for remote repositories, and regularly review access logs for suspicious activity.
-
Data leaks: Data leaks can occur when sensitive data is inadvertently or intentionally exposed through a remote repository. To mitigate this threat, implement policies and procedures for handling sensitive data, and use tools to scan remote repositories for sensitive data.
-
Third-party risks: Third-party risks can occur when using third-party remote repositories, such as GitHub or Bitbucket. To mitigate this threat, use reputable third-party providers with strong security and compliance measures in place, and regularly review their security policies and procedures.
-
Distributed denial-of-service (DDoS) attacks: DDoS attacks can be used to overwhelm remote repositories and disrupt normal operations. To mitigate this threat, use DDoS protection services and implement redundancy and failover measures for remote repositories.
By understanding these Git security risks and implementing appropriate mitigation strategies, you can help protect your remote repositories from security threats.
Securing Git credentials and authentication
Securing Git credentials and authentication is an important aspect of Git security. Here are some best practices to follow:
-
Use strong passwords: Use strong, complex passwords or passphrases for Git authentication. Avoid using the same password for multiple accounts.
-
Use two-factor authentication: Implement two-factor authentication (2FA) for Git accounts to add an extra layer of security. 2FA can require a user to provide a password and a code generated by a mobile app or hardware token.
-
Avoid storing passwords in plaintext: Avoid storing Git passwords in plaintext files or scripts. Instead, use credential managers, such as Git’s built-in credential helper, to securely store and retrieve passwords.
-
Use SSH keys: Use SSH keys instead of passwords for Git authentication when possible. SSH keys are more secure than passwords because they are cryptographically generated and can be protected by a passphrase.
-
Limit access: Limit Git repository access to only those who need it. Use access controls, such as permissions and roles, to restrict access to sensitive repositories and information.
-
Rotate passwords and keys: Regularly rotate passwords and SSH keys to ensure that they are not compromised. Use password managers or key rotation scripts to automate the process.
By following these best practices, you can help secure Git credentials and authentication and reduce the risk of unauthorized access to your Git repositories.
Implementing access controls and permissions in Git
Implementing access controls and permissions in Git is an important aspect of Git security. Here are some best practices for implementing access controls and permissions in Git:
-
Use a role-based access control (RBAC) model: RBAC allows you to assign users to roles with different levels of access to Git repositories. This approach can simplify access control management by reducing the number of individual permissions that need to be managed.
-
Use Git hosting services that support access controls: Git hosting services like GitHub and GitLab provide granular access controls that allow you to specify access at the repository, branch, and file level. Use these features to ensure that users only have access to the repositories and information that they need.
-
Limit access to production branches: Limit access to production branches to a small group of trusted users. Require code reviews and approvals before merging code into production branches.
-
Implement branch protection rules: Use branch protection rules to prevent accidental changes to critical branches. These rules can prevent direct pushes to protected branches, require pull requests, and enforce code review and approval processes.
-
Use commit signing: Commit signing can help prevent unauthorized code changes. Use GPG or other cryptographic signatures to sign commits and verify that they have not been tampered with.
-
Regularly review access logs: Regularly review access logs to identify unauthorized access attempts and suspicious activity.
By implementing these best practices, you can help secure Git repositories and reduce the risk of unauthorized access or data breaches.
Encrypting Git data and backups
Encrypting Git data and backups is an important aspect of Git security. Here are some best practices to follow:
-
Use HTTPS or SSH: Use HTTPS or SSH to encrypt data in transit when communicating with Git servers. HTTPS and SSH both use encryption to protect data transmitted over the network.
-
Encrypt Git repositories: Use Git encryption features to encrypt the contents of Git repositories at rest. Git supports several encryption mechanisms, including GPG encryption and git-crypt.
-
Encrypt Git backups: Encrypt Git backups to prevent unauthorized access to sensitive data. Use a backup tool that supports encryption, such as GPG, to encrypt Git backups.
-
Use secure storage: Store Git repositories and backups in secure storage locations. Use storage solutions that provide encryption, such as encrypted file systems or encrypted cloud storage.
-
Rotate encryption keys: Regularly rotate encryption keys to ensure that they are not compromised. Use key rotation scripts or tools to automate the process.
-
Secure key management: Securely manage encryption keys to prevent unauthorized access. Use a key management system that provides encryption, access controls, and auditing capabilities.
By following these best practices, you can help secure Git data and backups and reduce the risk of unauthorized access or data breaches.
Using Git with SSL/TLS and SSH for secure communication
Using Git with SSL/TLS and SSH for secure communication is an important aspect of Git security. Here’s an overview of these two methods:
-
SSL/TLS: Git can be configured to use SSL/TLS to encrypt communication between clients and servers. To use SSL/TLS, you need to configure Git to use a certificate for the server, and ensure that the certificate is issued by a trusted Certificate Authority (CA). This helps to protect the communication between Git clients and servers against eavesdropping and man-in-the-middle attacks.
-
SSH: Git can also be configured to use SSH for secure communication between clients and servers. SSH provides end-to-end encryption and authentication for Git communication. To use SSH with Git, you need to generate a public-private key pair and add the public key to your Git server. This allows Git clients to authenticate with the server and securely exchange data.
Both SSL/TLS and SSH provide strong encryption and authentication for Git communication, and are widely used in secure Git deployments. When configuring SSL/TLS or SSH for Git, it’s important to follow best practices for key management, certificate management, and access controls to ensure the security of your Git infrastructure.
Best practices for securely storing and managing Git repositories
Here are some best practices for securely storing and managing Git repositories:
-
Use access controls: Limit access to Git repositories to authorized personnel only. Use access controls to restrict who can read, write, and execute Git repositories. This helps to prevent unauthorized access to sensitive data.
-
Use secure authentication: Use secure authentication methods, such as SSL/TLS or SSH, to authenticate users and protect against password attacks. Implement two-factor authentication (2FA) to add an additional layer of security.
-
Encrypt data at rest: Encrypt Git repositories at rest to protect against data breaches. Use disk encryption, file system encryption, or database encryption to encrypt data stored in Git repositories.
-
Implement backups: Regularly backup Git repositories to protect against data loss. Ensure that backup data is encrypted and stored in a secure location.
-
Monitor and log access: Monitor and log access to Git repositories to detect and respond to security incidents. Implement audit trails and security logs to record user activity and changes to Git repositories.
-
Use vulnerability scanners: Regularly scan Git repositories for vulnerabilities and security threats. Use vulnerability scanners, such as GitGuardian or GitLeaks, to detect and remediate potential security risks.
-
Keep Git up-to-date: Keep Git and related software up-to-date with the latest security patches and updates. Stay informed of security advisories and best practices for Git security.
By following these best practices, you can help ensure the security of Git repositories and protect against data breaches and other security threats.
Dealing with security incidents and breaches in Git
Dealing with security incidents and breaches in Git can be challenging, but having a plan in place can help minimize the impact and prevent further damage. Here are some steps to take in the event of a security incident or breach:
-
Contain the incident: As soon as you become aware of a security incident or breach, immediately isolate the affected systems and limit access to sensitive data. This can help prevent the spread of the incident and minimize the impact.
-
Investigate the incident: Gather as much information as possible about the security incident or breach, including when it occurred, who was involved, and what data was affected. This can help you determine the scope of the incident and the best course of action.
-
Notify stakeholders: Inform affected users, stakeholders, and authorities about the security incident or breach. Be transparent about what happened, what data was affected, and what steps you are taking to address the issue.
-
Mitigate the impact: Take steps to mitigate the impact of the security incident or breach. This may include restoring data from backups, updating access controls, or implementing new security measures.
-
Review and improve security practices: Once the incident has been contained and the impact has been mitigated, review your security practices to identify any weaknesses or areas for improvement. Implement new security measures and protocols to help prevent future incidents and breaches.
By following these steps, you can help minimize the impact of security incidents and breaches in Git and protect against future threats. It is important to have a plan in place for dealing with security incidents and to regularly review and improve your security practices to stay ahead of potential threats.
Chapter 11: Git for Open Source
The importance of Git in open source projects
Git is extremely important in open source projects as it enables developers to collaborate and contribute to codebases in a distributed manner. Open source projects are often developed by a large and diverse community of contributors who may be located around the world. Without a tool like Git, managing and coordinating contributions to an open source project would be incredibly challenging.
Git provides a number of features that are particularly well-suited to open source projects. These include:
-
Distributed version control: Git allows each contributor to maintain their own copy of the repository, which they can modify and then share with others. This makes it easy for developers to collaborate on code changes, even if they are located in different parts of the world.
-
Branching and merging: Git’s branching and merging features allow developers to work on different features or bug fixes simultaneously without interfering with each other’s work. This allows for a more efficient and organized development process.
-
Pull requests: Git’s pull request feature provides a way for contributors to suggest changes to the project’s codebase. Other contributors can then review the changes and provide feedback before the changes are merged into the main codebase.
-
Transparency: Git’s history tracking features make it easy to see who has contributed to the project, what changes they have made, and when those changes were made. This helps to promote transparency and accountability within the open source community.
Overall, Git has revolutionized the way that open source projects are developed and managed. It has made it easier for developers to collaborate and contribute to codebases, regardless of their location or level of expertise. As a result, Git has played a critical role in the growth and success of the open source movement.
Contributing to open source projects with Git
Contributing to open source projects with Git can be a great way to gain experience and build your skills as a developer. Git makes it easy for developers to collaborate on code and share their work with others, regardless of their location or level of experience.
Here are some steps you can follow to start contributing to open source projects with Git:
-
Find a project: Look for open source projects that interest you and that you would like to contribute to. You can use sites like GitHub, GitLab, and Bitbucket to search for projects and see their codebase.
-
Fork the project: Once you find a project you want to contribute to, fork the repository. This creates a copy of the project’s codebase in your own Git account that you can modify and experiment with.
-
Clone the repository: Clone the forked repository to your local machine. This creates a local copy of the repository that you can work with.
-
Make changes: Make changes to the codebase that you think will improve the project. This can include adding new features, fixing bugs, or improving documentation.
-
Commit changes: Once you have made changes, commit them to your local Git repository. Be sure to write a clear and descriptive commit message that explains the changes you made.
-
Push changes: Push your changes to your forked repository on the Git hosting platform. This makes your changes available for others to see and review.
-
Submit a pull request: Submit a pull request to the original project’s repository. This asks the project maintainers to review your changes and consider merging them into the main codebase.
-
Participate in the review process: Be prepared to respond to feedback and make changes to your code based on the feedback you receive. The review process is an important part of contributing to open source projects and can help you improve your coding skills.
By following these steps, you can start contributing to open source projects with Git and gain valuable experience as a developer.
Maintaining an open source project with Git
Maintaining an open source project with Git requires a combination of technical and interpersonal skills. Here are some best practices for maintaining an open source project with Git:
-
Keep the codebase organized: Use branching and tagging strategies to keep the codebase organized and easy to maintain. Use descriptive branch names, and consider using a branching strategy such as GitFlow.
-
Respond to issues and pull requests: Respond to issues and pull requests in a timely manner. Provide clear and helpful feedback, and be open to suggestions and contributions from others.
-
Keep documentation up-to-date: Maintaining up-to-date documentation is important for helping new contributors understand the project and get started with contributing.
-
Communicate effectively: Use tools such as GitHub’s issue tracker and pull request system to communicate with contributors and keep everyone informed about the status of the project.
-
Make releases regularly: Regularly releasing new versions of the project helps to keep users engaged and encourages ongoing contributions.
-
Build a community: Build a community of contributors and users around the project. Encourage contributions, and recognize and thank contributors for their work.
-
Be responsive to security issues: Respond promptly to security issues, and provide clear instructions for users on how to update to the latest, secure version of the project.
By following these best practices, you can effectively maintain an open source project with Git and build a community of contributors and users around the project.
Best practices for using Git in open source
Here are some best practices for using Git in open source projects:
-
Fork before making changes: If you want to make changes to an open source project, it’s best to create a fork of the project first. This will give you your own copy of the project to work with, and will make it easy to submit changes back to the original project later.
-
Create a descriptive branch name: When you create a new branch for your changes, use a descriptive name that summarizes the changes you are making.
-
Make small, focused commits: Break your changes up into small, focused commits that are easy to understand and review. Each commit should contain a single logical change, and should be accompanied by a clear commit message.
-
Follow the project’s contribution guidelines: Most open source projects have contribution guidelines that outline the project’s coding style, testing requirements, and other expectations for contributors. Be sure to read and follow these guidelines when making changes to the project.
-
Use pull requests to submit changes: When you’re ready to submit your changes back to the original project, use a pull request to do so. This will make it easy for the project maintainers to review your changes, and for other contributors to provide feedback.
-
Be responsive to feedback: Be open to feedback from the project maintainers and other contributors, and be willing to make changes to your code based on that feedback.
-
Keep your fork up-to-date: As the original project evolves, be sure to pull in changes from the upstream repository to keep your fork up-to-date. This will help to prevent merge conflicts and other issues when submitting changes back to the original project.
By following these best practices, you can effectively use Git in open source projects and contribute to the success of the project.
Understanding Git-based workflows in open source projects
In open source projects, Git is often used as the version control system to manage the codebase. Git-based workflows are designed to enable multiple developers to work together on a single codebase, while maintaining the stability and quality of the code. Here are some common Git-based workflows used in open source projects:
-
Centralized workflow: In this workflow, there is a single central repository that all developers work from. Each developer has their own local copy of the repository, and pushes their changes to the central repository when they are ready to share their work with others. This workflow is simple and straightforward, but can become cumbersome as the number of developers grows.
-
Feature branch workflow: In this workflow, each developer creates a branch for their changes, rather than making changes directly to the main branch. Once the changes are complete, they are merged back into the main branch. This workflow is useful when multiple developers are working on different features simultaneously, and allows for greater flexibility and parallel development.
-
Fork and pull request workflow: In this workflow, each developer creates a fork of the main repository, and makes their changes in their own fork. Once the changes are complete, they create a pull request to have their changes merged into the main repository. This workflow is particularly useful for open source projects, as it allows contributors to easily submit changes without having direct write access to the main repository.
Regardless of the specific Git-based workflow used in an open source project, it’s important to follow best practices such as creating descriptive branch names, making small, focused commits, and following the project’s contribution guidelines. This will help to ensure that changes are easily understood and reviewed by other developers, and will maintain the overall quality of the codebase.
Using Git to fork, clone, and contribute to open source projects
If you want to contribute to an open source project using Git, you will typically need to follow these steps:
-
Fork the repository: To contribute to an open source project, you will need to create a copy (or “fork”) of the project’s repository on a Git hosting platform such as GitHub or GitLab. This will create a new copy of the project’s repository that you can make changes to without affecting the original project.
-
Clone the repository: Once you have forked the repository, you will need to clone it to your local machine. This will create a local copy of the repository that you can work on.
-
Make changes: Once you have cloned the repository, you can make changes to the code. Be sure to follow the project’s contribution guidelines and coding standards.
-
Create a branch: When making changes to an open source project, it’s a good idea to create a new branch for each set of changes you make. This will keep your changes separate from the main branch and make it easier to manage them.
-
Commit your changes: Once you have made your changes, you will need to commit them to your branch. Be sure to include a descriptive commit message that explains the changes you made.
-
Push your changes: Once you have committed your changes, you will need to push them to your fork of the repository on the Git hosting platform.
-
Create a pull request: After you have pushed your changes to your fork of the repository, you can create a pull request to ask the project’s maintainers to review and merge your changes into the main repository.
It’s important to note that contributing to open source projects can be a complex process, and each project may have its own unique contribution guidelines and requirements. Be sure to read the project’s documentation carefully and reach out to the maintainers if you have any questions or concerns.
Understanding Git pull requests and code review processes in open source
In open source projects, Git pull requests (PRs) play a crucial role in the code review process. A pull request is a way for a contributor to suggest changes to the project maintainer(s) by submitting a request to pull a branch of their changes into the main branch of the project. The pull request provides an opportunity for the maintainer(s) to review the changes and provide feedback or request additional changes before merging the pull request.
The code review process in open source projects typically involves multiple reviewers and can be quite extensive, depending on the size and complexity of the project. It’s important for contributors to be responsive to feedback and willing to make changes as requested by the reviewers.
Code review comments can be made directly on the pull request, allowing for discussion and collaboration between the contributor and the reviewers. Once all issues have been addressed, the pull request can be merged into the main branch of the project, incorporating the contributor’s changes into the project.
Maintaining open source projects using Git-based tools such as GitHub, GitLab, and Bitbucket
Maintaining open source projects using Git-based tools such as GitHub, GitLab, and Bitbucket involves several best practices to ensure the project stays organized, efficient, and welcoming to contributors.
-
Keep the issue tracker up-to-date: Encourage contributors to use the issue tracker to report bugs, request features, or ask questions. Keep the issue tracker organized and up-to-date to ensure that issues are being addressed in a timely and efficient manner.
-
Use labels and milestones: Labels and milestones can help categorize issues and track progress. Labels can be used to mark issues as “bug”, “enhancement”, or “help wanted”. Milestones can be used to group related issues and track progress towards a specific goal.
-
Review and merge pull requests regularly: Review and merge pull requests regularly to ensure that contributions are being incorporated into the project. Be sure to provide feedback and guidance to contributors during the review process.
-
Keep documentation up-to-date: Documentation is critical for open source projects. Make sure documentation is up-to-date and easy to understand. Encourage contributors to submit documentation updates along with code changes.
-
Manage contributions: Encourage contributions from the community and manage them in a way that is welcoming and inclusive. Ensure that contributors understand the project’s code of conduct and are following it.
-
Use automation: Git-based tools such as GitHub, GitLab, and Bitbucket offer a variety of automation features, such as continuous integration and automated testing. Use these tools to streamline the development process and ensure that code changes are tested and validated before being merged.
-
Communicate with the community: Keep the community informed of project updates, progress, and upcoming changes. Use social media, mailing lists, or other communication channels to engage with the community and gather feedback.
Managing issues, bug reports, and feature requests using Git-based tools
Git-based tools like GitHub, GitLab, and Bitbucket provide a range of features to help manage issues, bug reports, and feature requests for open source projects. These tools provide a central location for the community to report issues and suggest new features. Some best practices for managing these issues using Git-based tools include:
-
Encourage clear and detailed issue reports: Ask community members to provide as much detail as possible when reporting an issue, including steps to reproduce the issue and any relevant logs or error messages.
-
Use labels and milestones to categorize and track issues: Assigning labels and milestones to issues can help you organize and prioritize work, as well as communicate progress to the community.
-
Set up templates for issue reports: Consider creating templates for issue reports to help guide community members in providing the necessary information.
-
Use a consistent and transparent process for triaging and resolving issues: Consider using a defined process for triaging and resolving issues, such as a specific set of labels that indicate the status of an issue (e.g., “needs triage,” “in progress,” “resolved”).
-
Encourage community involvement in issue resolution: Consider allowing community members to submit pull requests that address issues, or to comment on open issues to provide additional information or context.
By following these best practices, you can effectively manage issues and feature requests using Git-based tools, while also fostering a transparent and collaborative community.
Collaborating with other contributors and maintaining the integrity of the project using Git
In open source projects, collaboration is key to maintaining the project and ensuring its success. Git provides a number of features and workflows that can be used to collaborate effectively with other contributors and maintain the integrity of the project.
One important aspect of collaboration in Git is the use of branches. Each contributor can create their own branch to work on a specific feature or fix, without impacting the main development branch. This allows for parallel development, and reduces the risk of conflicts.
Another key aspect of collaboration is code review. When a contributor has completed work on their branch, they can create a pull request (PR) to request that their changes be merged into the main development branch. Other contributors can review the code changes and provide feedback, suggestions, and approval before the changes are merged.
It is also important to maintain the integrity of the project by enforcing rules and guidelines for contributing. This can include code style and formatting guidelines, testing requirements, and documentation requirements. Git-based tools such as GitHub, GitLab, and Bitbucket provide features for enforcing these rules, such as pre-commit hooks and automated testing.
Communication is also essential for collaboration in open source projects. Contributors should use Git-based tools to communicate with each other, such as commenting on pull requests and issues, and using chat and messaging tools to discuss project development and coordinate efforts.
Finally, it is important to be respectful of other contributors and maintain a positive and inclusive environment in the project. This can include being open to feedback and criticism, providing constructive feedback to others, and avoiding personal attacks or disrespectful behavior.
Navigating open source licensing and copyright issues using Git and related tools
When working with open source projects, it’s important to understand licensing and copyright issues in order to avoid potential legal issues. Git and related tools can help navigate these issues by providing mechanisms for managing licenses and tracking changes to the codebase.
One of the key features of Git is its ability to track changes to files and directories over time. This makes it easy to see when changes were made, who made them, and what the changes were. When contributing to an open source project, it’s important to be aware of the project’s license and any copyright restrictions on the code. Git can help by providing a record of all changes made to the codebase, which can be used to ensure that all contributions are made in compliance with the project’s licensing and copyright requirements.
Many Git-based tools also provide features for managing licenses and copyright information. For example, GitHub provides a feature called License Detection, which automatically detects the license used by a project based on the contents of the project’s repository. This can be a useful tool for contributors to ensure that their contributions are made in compliance with the project’s license.
Another important aspect of navigating licensing and copyright issues is understanding the legal implications of different licenses. Some open source licenses require that any derivative works be made available under the same license, while others do not. It’s important to understand the implications of the license in order to avoid potential legal issues. Git and related tools can be useful for tracking the license of the codebase, as well as any changes to the license over time.
Overall, using Git and related tools can be a valuable resource for navigating licensing and copyright issues when working with open source projects. By keeping track of changes to the codebase and providing tools for managing licenses and copyright information, these tools can help ensure that contributions are made in compliance with the project’s requirements, while also helping to maintain the integrity of the codebase.
Chapter 12: Real-World Git Projects
Sample Git projects and use cases
Sure, here are some sample Git projects and their use cases:
-
GitLab - an open-source Git repository management platform that allows teams to collaborate on code, test, and deploy code changes. It has a built-in continuous integration and continuous deployment (CI/CD) pipeline, issue tracking, and code review tools.
-
React - a JavaScript library for building user interfaces. It is used by developers to build reusable UI components for web applications.
-
TensorFlow - an open-source software library for dataflow and differentiable programming across a range of tasks. It is used for machine learning and deep learning applications.
-
Ansible - an open-source automation tool used for configuration management, application deployment, and task automation. It uses a declarative language to define systems and their configurations.
-
Kubernetes - an open-source container orchestration platform used to deploy, scale, and manage containerized applications.
These are just a few examples of the many projects and use cases for Git.
A web development project with multiple contributors
Sure, here’s an example of a web development project with multiple contributors using Git:
Suppose a team of web developers is working on a project to create a new website for a client. The team consists of five developers, each with a different area of expertise. The project requires them to work on different parts of the website, such as the front-end design, back-end functionality, database management, and content creation.
The team decides to use Git for version control and collaboration. They create a remote repository on GitHub, and each team member clones the repository to their local machine. The team decides to use the Gitflow workflow, which involves creating feature branches for new features, and merging them into the main branch once they are complete.
To start working on the project, each developer creates a new feature branch for the part of the website they will be working on. For example, the front-end developer creates a feature branch called “frontend-design,” the back-end developer creates a feature branch called “backend-functionality,” and so on.
As each developer works on their part of the website, they commit their changes to their feature branch and push the changes to the remote repository. They can also create pull requests to review their code changes with other team members and get feedback before merging the changes into the main branch.
The team uses Git tools like GitHub’s issue tracker to manage tasks, assign responsibilities, and track progress. They also use Git’s version control features to roll back changes if necessary, and to keep track of who made what changes and when.
Once the project is complete, the team merges all the feature branches into the main branch, and pushes the changes to the remote repository. They can then deploy the website to the client’s server, confident that they have a complete history of all changes made to the project, and the ability to revert to any previous state if necessary.
A machine learning project with versioned datasets and models
Sure, here’s an example use case for Git in a machine learning project:
Suppose you are working on a machine learning project with a team of data scientists, where you need to version control large datasets and machine learning models. You can use Git to track the changes made to your datasets and models over time and ensure that your team members can work collaboratively and efficiently.
You can use Git to version control your datasets by creating a separate Git repository for each dataset. Each repository can contain a different version of the dataset, with the name of the repository indicating the version number. You can also use Git LFS (Large File Storage) to store large binary files, such as image or audio data.
Similarly, you can use Git to version control your machine learning models by creating a separate Git repository for each version of the model. You can track changes made to your models over time, and each repository can contain a different version of the model.
With Git, you can also create branches for different experiments and versions of your models, allowing your team to work on different versions of the same model in parallel. Git also allows you to easily merge different branches and versions of your code, making it easy to collaborate on the project and keep everyone up-to-date.
In addition, you can use Git to track the performance of different models and compare the results of different experiments. You can use Git to create tags for different versions of the model, allowing you to easily switch between different versions and compare their performance.
Overall, Git can be a powerful tool for version controlling large datasets and machine learning models in a collaborative team environment.
A game development project with asset management
A game development project often involves managing a large number of assets, such as images, sounds, and 3D models, in addition to code. Git can be used to version control these assets and manage collaboration among team members.
For example, imagine a team of game developers working on a new mobile game. The game has several levels, each with unique assets such as background images, sound effects, and enemy characters. The team can use Git to version control each level’s assets, making it easy to roll back changes or restore deleted files.
In addition, the team can use Git to manage collaboration on game mechanics, such as enemy behavior and scoring systems. Each team member can work on their own branch, making changes to the code or assets related to their specific task. When they’re ready to merge their changes, they can create a pull request and request code review from other team members.
Git can also be used to version control datasets and models in machine learning projects. For example, a team working on a computer vision project may use Git to version control the training datasets and models used to develop the machine learning algorithm. This makes it easy to track changes to the datasets and models and collaborate with other team members.
An infrastructure project with IaC and GitOps
Sure, an infrastructure project with IaC and GitOps is a great use case for Git. Let’s say you have a team responsible for managing the infrastructure of a web application. The infrastructure is defined as code using a tool like Terraform, and you want to implement GitOps practices to manage changes to the infrastructure in a controlled manner.
Here’s a sample workflow:
- Developers make changes to the infrastructure code locally on their machines.
- They commit their changes to a Git repository, using a feature branch.
- They open a pull request (PR) to merge their changes into the main branch of the Git repository.
- Other team members review the changes in the PR and provide feedback, comments, or suggestions.
- Once the changes have been reviewed and approved, they are merged into the main branch.
- A Git webhook triggers a pipeline to deploy the changes to the infrastructure, using a tool like Flux or ArgoCD.
- If the deployment is successful, the infrastructure is updated and ready to use.
By using Git as the version control system and implementing GitOps practices, the team can easily manage changes to the infrastructure in a collaborative and controlled manner. They can track the history of changes, roll back to previous versions if needed, and ensure that changes are deployed in a consistent and reliable way.
Ideas for implementing Git in your own projects
If you are looking to implement Git in your own projects, here are some ideas to consider:
-
Start by creating a repository for your project and commit your code regularly. This will allow you to easily track changes and collaborate with others.
-
Use branching and merging to manage feature development and bug fixes. This will help you keep your development process organized and make it easier to isolate and fix issues.
-
Integrate Git into your CI/CD pipeline to automate testing and deployment. This can help you catch issues early and streamline your release process.
-
Consider using Git-based tools like GitHub, GitLab, or Bitbucket to manage your project and collaborate with others. These tools offer a range of features, including issue tracking, pull requests, and code review.
-
Explore Git-based workflows like GitFlow, GitHub Flow, or Trunk-Based Development to find a process that works best for your team and project.
-
Use Git with containerization technologies like Docker and Kubernetes to manage your infrastructure and deployments.
-
Consider using Git for version control of non-code assets, like documentation or design files, to keep everything organized in one place.
Remember, Git is a powerful tool that can help you streamline your development process and collaborate more effectively with others. By taking the time to learn how to use Git effectively, you can set your project up for success.
Choosing a branching strategy for your team
Choosing a branching strategy is an important decision for any team using Git for version control. Here are some factors to consider when choosing a branching strategy:
-
Team size: Larger teams may require more complex branching strategies to manage changes effectively.
-
Release frequency: If your team releases frequently, you may want to consider a branching strategy that allows for more isolated development and testing.
-
Risk tolerance: Some branching strategies involve more risk than others. Consider how much risk your team is willing to take on when choosing a branching strategy.
-
Development style: The branching strategy should match the way your team works. For example, if your team prefers to work in feature branches, you may want to choose a branching strategy that supports that approach.
Some common branching strategies include:
-
Feature branching: This strategy involves creating a new branch for each new feature or development task. This allows developers to work on new features without disrupting the main codebase.
-
Gitflow: This strategy involves creating separate branches for development, releases, and hotfixes. It also includes a master branch that represents the current stable release.
-
Trunk-based development: This strategy involves working directly on the trunk branch, with all changes going through a code review process before being merged.
-
GitLab flow: This strategy is similar to Gitflow, but it includes an additional branch for staging changes before they are released.
Ultimately, the best branching strategy for your team will depend on your specific needs and development style. It’s important to experiment and iterate until you find a strategy that works well for your team.
Using Git hooks to automate tasks and enforce standards
Git hooks are scripts that run automatically when certain Git events occur, such as committing changes or pushing commits to a remote repository. Git hooks can be used to automate tasks, enforce code standards, and perform other actions that help maintain the quality and consistency of a project.
There are several types of Git hooks, including pre-commit, pre-push, and post-merge hooks. Pre-commit hooks are run before a commit is made and can be used to enforce coding standards, run automated tests, or perform other tasks to ensure that the code being committed is of high quality. Pre-push hooks are run before changes are pushed to a remote repository and can be used to prevent pushes of code that does not meet certain criteria. Post-merge hooks are run after a merge is completed and can be used to perform cleanup tasks or other actions that need to occur after a merge.
To implement Git hooks in your own projects, you can create a new script in the .git/hooks directory of your repository and give it executable permissions. You can then write the script to perform the desired action, such as running tests or checking for code style violations, and Git will automatically execute the script when the appropriate event occurs.
It’s important to keep in mind that Git hooks are local to each developer’s copy of the repository, so it’s not possible to enforce them across an entire team or organization. However, by using Git hooks, you can help ensure that each developer is following the same standards and contributing high-quality code to the project.
Integrating Git with your CI/CD pipeline
Integrating Git with your CI/CD pipeline is an essential aspect of modern software development. The integration allows you to automate the building, testing, and deployment of your code, resulting in faster and more reliable delivery of new features and bug fixes. Here are some tips for integrating Git with your CI/CD pipeline:
-
Use a Git webhook to trigger your CI/CD pipeline: When a developer pushes a commit to the Git repository, a webhook can be triggered to notify your CI/CD pipeline to start the build, test, and deployment process.
-
Use a Git-based pipeline definition: Many CI/CD tools allow you to define your pipeline using a Git-based configuration file. This approach enables you to version your pipeline configuration, track changes, and collaborate with other team members.
-
Use Git branches to manage different environments: You can use Git branches to manage different environments such as development, staging, and production. This approach enables you to test and deploy changes to specific environments before promoting them to production.
-
Use Git tags to create releases: Git tags enable you to create named releases of your code. You can use this feature to trigger a release pipeline that builds and deploys your code to production.
-
Use Git submodules to manage dependencies: If your project has dependencies on other Git repositories, you can use Git submodules to manage them. Submodules enable you to include other repositories as subdirectories within your repository and track their changes along with your code.
By following these tips, you can integrate Git with your CI/CD pipeline to automate your development workflow and improve the quality of your software delivery.
Using Git submodules to manage dependencies
Git submodules allow you to include one Git repository as a subdirectory within another Git repository. This is useful for managing dependencies or including code from other projects in your own project.
To use Git submodules, you first need to add the submodule to your repository using the git submodule add command. This will clone the submodule repository and add it to your main repository as a subdirectory. You can then commit the changes to your main repository, which will include the submodule as a reference to a specific commit in the submodule repository.
When you clone a repository with submodules, the submodules are not cloned by default. To clone the submodules as well, you can use the git submodule update command. You can also use the --recursive option when cloning the main repository to clone all submodules at once.
One common use case for Git submodules is managing dependencies in a project. For example, if you have a web application that depends on a specific version of a JavaScript library, you can include that library as a submodule in your repository. This ensures that anyone who clones your repository has the correct version of the library.
It’s important to note that Git submodules can be complex to work with, especially if you have multiple levels of submodules or if you need to update the submodule to a different commit. It’s important to have a clear understanding of how submodules work before using them in a production project.
Advanced Git techniques for real-world scenarios
Here are some advanced Git techniques that can be useful in real-world scenarios:
-
Interactive rebase: Interactive rebase allows you to edit your commit history by reordering, combining, or splitting commits. This can be useful when you want to clean up your commit history before pushing it to a public repository. You can use interactive rebase to squash multiple commits into one, split a commit into multiple ones, or change the commit message.
-
Reflog: Git’s reflog is a log of all the changes to Git’s references (branches, tags, and HEAD) in your repository. This can be useful in case you accidentally delete a branch or reset your HEAD to a previous commit. You can use reflog to recover your lost work by finding the SHA-1 hash of the commit that you accidentally deleted.
-
Git rerere: Git rerere (reuse recorded resolution) is a feature that allows Git to automatically resolve conflicts that have been previously resolved. This can be useful when you have conflicts that occur frequently, and you want to avoid resolving them manually each time they occur. Git rerere remembers how you resolved conflicts in the past and applies that resolution automatically.
-
Cherry-pick: Cherry-pick allows you to apply a specific commit from one branch to another branch. This can be useful when you want to apply a fix from a different branch without merging the entire branch.
-
Bisect: Git bisect allows you to find the commit that introduced a bug by performing a binary search on the commit history. This can be useful when you have a large codebase and want to find the commit that introduced a bug. Git bisect will help you narrow down the search to the specific commit that caused the problem.
-
Git worktree: Git worktree allows you to create multiple working directories from a single Git repository. This can be useful when you want to work on multiple branches simultaneously without having to switch back and forth between branches in the same working directory.
-
Git blame: Git blame allows you to see who last modified each line of a file and when the modification was made. This can be useful when you want to find out who introduced a specific change or when a particular line was last modified.
-
Git stash: Git stash allows you to temporarily store changes that are not ready to be committed. This can be useful when you want to switch branches or perform a git pull without committing your changes first.
These are just a few examples of advanced Git techniques that can be useful in real-world scenarios. There are many more features and techniques in Git that can help you work more efficiently and effectively.
Squashing commits to clean up history
Squashing commits is a technique used to clean up a Git repository’s commit history by combining multiple commits into a single commit. This can be useful when you have made multiple small commits that are related to the same change and you want to present them as a single, cohesive change.
To squash commits, you can use the git rebase command with the -i option. This will open an interactive rebase editor where you can modify the commit history.
Here’s an example workflow for squashing commits:
-
Start by creating a new branch from the branch you want to modify:
git checkout -b new-feature-branch main -
Make your changes and commit them with descriptive commit messages.
git add . git commit -m "Add feature A" git commit -m "Add feature B" git commit -m "Add feature C" -
Run an interactive rebase to squash the commits:
git rebase -i HEAD~3This will open an editor where you can modify the commit history. Change the first commit to “pick” and the rest to “squash”:
pick abc123 Add feature A squash def456 Add feature B squash ghi789 Add feature CSave and close the editor.
-
Git will now combine the changes from the “squash” commits into the first “pick” commit. You will be prompted to enter a new commit message that describes the combined changes.
-
Force push the changes to the remote branch:
git push --force
Note that when you squash commits, you are rewriting the Git history, so use caution when doing this on a branch that other developers are working on.
Using bisect to find bugs and regressions
git bisect is a command in Git that helps in finding the commit that introduced a bug or regression in the codebase. The process of finding the problematic commit involves a binary search through the commit history, where Git checks out a commit in the middle of the history and asks the user if the code is working correctly or not. Based on the answer, Git eliminates half of the remaining commits and continues the process until it finds the commit that introduced the issue.
Here are the steps to use git bisect:
-
Identify a good and bad commit: Start by identifying a known good commit (a commit where the code works correctly) and a bad commit (a commit where the code contains the bug or regression). You can use Git tags, branch names, or commit hashes to mark these commits.
-
Start the bisect process: Use the command
git bisect startto start the bisect process. -
Mark the good and bad commits: Use the command
git bisect good <good-commit>to mark the good commit andgit bisect bad <bad-commit>to mark the bad commit. -
Test the current commit: Git will now check out a commit in the middle of the good and bad commits and ask you to test the code. Use this opportunity to run tests, manually verify the code, or perform any other checks to determine whether the code works correctly or not. Once you have tested the code, mark the current commit as good or bad using the
git bisect goodorgit bisect badcommands. -
Repeat until the problematic commit is found: Git will continue to check out commits in the middle of the good and bad commits and ask you to test the code until it finds the commit that introduced the issue. Once the problematic commit is found, use the command
git bisect resetto exit the bisect process and return to the current branch.
git bisect is a powerful tool for finding bugs and regressions in your codebase, but it requires a good understanding of the Git history and a disciplined approach to testing and debugging. It’s also important to note that git bisect works best when you have a relatively small number of commits between the good and bad commits, so it’s a good idea to keep your commit history clean and organized.
Rewriting history with filter-branch and rebase
Git provides a couple of ways to rewrite the history of a repository, such as the filter-branch and rebase commands. Here’s a brief explanation of each:
-
filter-branch: This command is useful for modifying the commits of a branch, either to clean up the history, remove sensitive data, or to extract a subdirectory into its own repository. The command applies a filter to each commit in the branch, creating a new commit with the changes applied. While it’s a powerful command, it’s important to note that it rewrites the entire history of the branch, which can lead to problems with collaborators if not handled correctly. -
rebase: This command is useful for integrating changes from one branch into another while keeping a clean and linear history. The command applies the changes of one branch onto another by replaying the commits on top of the target branch. The result is a new branch with the same changes but with a linear history that’s easier to follow. While it’s a useful command, it’s important to note that it can lead to conflicts and should be used with caution.
It’s worth noting that both of these commands rewrite the Git history, which can lead to problems with collaborators and downstream systems. As such, it’s important to use them carefully and communicate with other contributors when making changes.
Cherry-picking specific changes across branches
Cherry-picking is the act of selecting a specific commit from one branch and applying it to another branch. This can be useful when you want to apply a specific change from one branch to another without merging the entire branch. Here are the steps to cherry-pick a commit:
- Switch to the branch where you want to apply the commit:
git checkout <branch>- Identify the commit you want to cherry-pick. You can use the
git logcommand to view the commit history and find the commit ID:
git log- Once you have identified the commit you want to cherry-pick, use the
git cherry-pickcommand followed by the commit ID:
git cherry-pick <commit-id>- Git will apply the changes from the selected commit to the current branch. You may encounter conflicts if the changes in the commit you are cherry-picking conflict with changes in the current branch. Resolve any conflicts and commit the changes.
Cherry-picking can be useful for applying specific changes or bug fixes to different branches without merging an entire branch. However, it is important to use cherry-picking carefully and avoid creating conflicts or duplicating work.
Tips and tricks for optimizing Git performance
Here are some tips and tricks for optimizing Git performance:
-
Keep your repository small: It’s essential to keep your repository small as larger repositories take more time to clone, fetch, and push. It’s a good idea to store large files like binary files outside the repository and use Git LFS for versioning them.
-
Use shallow clones: A shallow clone is a clone with only the latest commit history. It can save a lot of time and disk space when working with large repositories.
-
Use Git with SSH: Using SSH instead of HTTPS can improve the performance of Git when interacting with remote repositories.
-
Reduce the frequency of Git fetches: Fetching from the remote repository frequently can slow down your Git performance. Instead, fetch only when necessary, or consider using a Git client that uses background fetching.
-
Use Git’s native commands instead of shell scripts: It’s always better to use Git’s native commands for operations like merging and rebasing, as they are optimized for performance.
-
Optimize Git settings: You can optimize Git performance by setting the correct values for Git configuration settings like
core.preloadIndex,core.compression, andgc.auto. -
Use Git’s packfiles: Git’s packfiles can help you optimize your repository by reducing the number of loose objects and saving disk space.
-
Keep your Git client up to date: Git performance improvements are regularly included in new releases. Keeping your Git client up to date can help you take advantage of these improvements.
-
Use Git with parallelism: Some Git operations, like cloning and fetching, can be done in parallel to improve performance. You can use Git’s
--jobsoption to set the number of parallel jobs. However, be careful not to overload your system. -
Consider using Git alternatives: If you have a large project that’s slow to work with using Git, you can consider using Git alternatives like Mercurial or Perforce, which are designed to handle large repositories.
Limiting the scope of git commands with flags and options
When working with Git, there are various flags and options available for many commands that allow you to limit the scope of what the command does. Here are some examples:
-
--authoror--committer: These flags can be used withgit logto limit the output to commits made by a specific author or committer. -
--sinceor--until: These flags can be used withgit logto limit the output to commits made within a specific time range. -
--grep: This flag can be used withgit logto limit the output to commits that contain a specific search term in their commit message or diff. -
--patch: This flag can be used withgit addto selectively stage changes in a file, rather than adding the entire file. -
--interactiveor-i: This flag can be used with various Git commands to bring up an interactive menu that allows you to select which changes or commits to work with. -
--no-verify: This flag can be used withgit committo bypass pre-commit hooks, which can be useful when you need to commit changes that violate the hooks (e.g., for debugging purposes). -
--quietor-q: This flag can be used with various Git commands to suppress output, which can be useful when you want to automate Git commands.
By using these flags and options, you can tailor Git commands to your specific needs and limit their scope to improve performance and reduce the chance of errors.
Using Git’s caching mechanisms to speed up common operations
Git provides a number of caching mechanisms that can help speed up common operations. Here are some examples:
-
Credential caching: Git can cache your credentials so that you don’t have to enter them every time you interact with a remote repository. The credentials are stored in memory or on disk, depending on the caching mode you choose. You can set the caching mode using the
credential.helperconfiguration option. -
Object caching: Git can cache objects (commits, trees, blobs, etc.) in memory to speed up common operations. By default, Git uses a least-recently-used (LRU) cache with a maximum size of 1,024 objects. You can configure the size of the cache using the
core.packedGitLimitandcore.packedGitWindowSizeconfiguration options. -
Index caching: Git can cache the index (staging area) in memory to speed up common operations like
git status. By default, Git uses a least-recently-used (LRU) cache with a maximum size of 1,024 entries. You can configure the size of the cache using thecore.indexCacheconfiguration option. -
Diff caching: Git can cache diffs (changes between files or commits) in memory to speed up common operations like
git diff. By default, Git uses a least-recently-used (LRU) cache with a maximum size of 512 entries. You can configure the size of the cache using thecore.packedGitLimitandcore.packedGitWindowSizeconfiguration options. -
Packfile caching: Git can cache packfiles (collections of objects) in memory to speed up common operations like
git log. By default, Git uses a least-recently-used (LRU) cache with a maximum size of 128MB. You can configure the size of the cache using thecore.packCacheLimitconfiguration option.
Note that caching can have tradeoffs. While it can improve performance, it can also consume more memory or disk space. It’s important to monitor the performance of your Git operations and adjust caching settings as needed.
Configuring Git to use a faster compression algorithm
By default, Git uses the zlib compression algorithm to compress objects before storing them in the repository. While zlib provides a good compression ratio, it can be slow on older hardware or repositories with large files. In recent versions of Git (since 2.20), a new compression algorithm called zstd has been added, which provides a better balance of compression ratio and speed.
To configure Git to use zstd compression, you can set the core.compression setting in your Git configuration:
git config --global core.compression zstdThis will enable zstd compression for all Git repositories on your system. You can also set the compression level by adding a number between 0 and 22 after the algorithm name (with higher numbers providing better compression but slower performance):
git config --global core.compression 'zstd:15'Note that zstd compression is only supported in Git versions 2.20 and later, so you may need to update your Git version to take advantage of this feature. Additionally, zstd may not be supported by all Git hosting services or clients, so it’s important to check with your team before making this change.
Employing shallow clones to reduce download times for large repositories
Shallow cloning is a technique used to reduce the amount of data that needs to be downloaded when cloning a Git repository. Instead of downloading the entire repository history, only a portion of it is fetched. This can significantly reduce the time it takes to clone a large repository.
To perform a shallow clone, use the --depth option when running the git clone command. For example, to clone a repository with a depth of 1, you would run:
git clone --depth 1 <repository URL>This will fetch only the most recent commit, along with the necessary objects to build that commit. If you need to fetch more history later, you can use the git fetch --depth command to increase the depth of your clone.
Note that shallow clones have limitations. You cannot push changes back to the original repository from a shallow clone, and some Git commands may not work as expected. Additionally, if you need to perform operations that require access to more history than is available in your shallow clone, you will need to convert your shallow clone to a full clone by fetching the missing history.